Disponibilité de l'API GPT-5.5 : Ce que les équipes doivent planifier
GPT-5.5 est annoncé, mais l'accès à l'API n'est pas encore entièrement disponible. Voici ce que les équipes peuvent planifier maintenant et ce qui nécessite encore une vérification.

J’ai passé le vendredi dernier à réorienter un workflow Codex vers GPT-5.5, puis j’ai passé le lundi à expliquer à deux clients pourquoi la décision de déploiement est plus complexe que ce que suggèrent les titres du lancement. Mon nom apparaît sur beaucoup de documents « faut-il migrer ? » chez WaveSpeedAI, donc je suis Dora — la personne qui fait patienter les équipes deux semaines avant de valider un changement de modèle. L’API est en ligne. C’est la partie que la plupart des articles couvrent correctement et s’arrêtent là. Ce dont je veux parler, c’est des dix jours qui suivent le lancement, quand « disponible » devient « vraiment intégré », et là où la plupart des équipes avec lesquelles je travaille se heurtent à des obstacles.
C’est une note de planification, pas un tutoriel. Si vous êtes venu pour des exemples curl, la documentation officielle s’en sort mieux que moi.
Où GPT-5.5 est disponible aujourd’hui
Statut de déploiement dans ChatGPT et Codex
GPT-5.5 est entré en service le 23 avril 2026 pour les utilisateurs Plus, Pro, Business et Enterprise dans ChatGPT et Codex, avec GPT-5.5 Pro restreint aux niveaux Pro, Business et Enterprise. Dans Codex spécifiquement, le modèle est livré avec une fenêtre de contexte de 400K tokens et un mode Rapide qui s’exécute 1,5x plus vite à 2,5x le coût — des détails que l’annonce officielle du lancement de GPT-5.5 sur OpenAI présente clairement. Le lancement ne couvrait que les interfaces grand public le premier jour. Je tiens à le signaler car la moitié des tickets que j’ai vus la semaine dernière supposaient une parité API dès le départ.
Ce qu’OpenAI dit sur la disponibilité de l’API
La partie que le cycle de presse initial a manquée : l’accès à l’API est arrivé un jour plus tard, le 24 avril 2026. gpt-5.5 et gpt-5.5-pro sont désormais exposés dans les API Responses et Chat Completions, confirmé dans la propre documentation du modèle GPT-5.5 d’OpenAI. La fenêtre de contexte est de 1M tokens sur l’interface API, distincte du plafond de 400K de Codex. Deux interfaces, deux limites — facile à confondre, et ça vaut la peine de le noter avant que vos ingénieurs le fassent. La question n’est donc plus « quand mon équipe peut-elle l’utiliser ». C’est « devons-nous le faire, et que vérifions-nous en premier ? »
Ce que les équipes peuvent planifier sereinement avant l’intégration de l’API
Critères d’évaluation et préparation de la migration
Je ne recommande pas une migration le jour même. Voici ce que je consoliderais en premier.
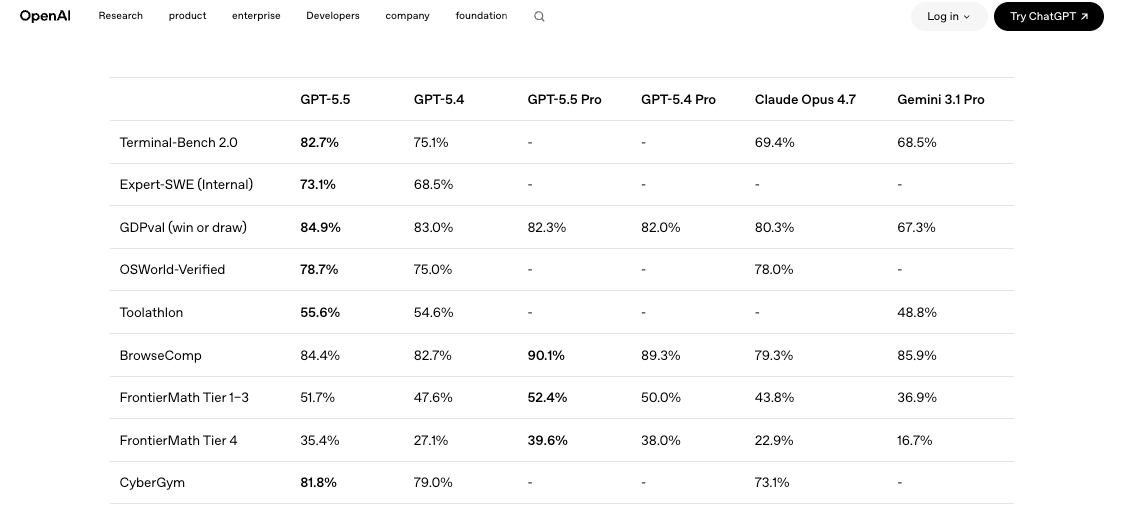
Construisez un petit dispositif d’évaluation par rapport à votre modèle actuel. Cinq à dix prompts représentatifs de votre charge de travail réelle, notés selon les dimensions qui comptent vraiment pour vous : exactitude, coût en tokens, latence, taux de nouvelles tentatives. Faites tourner GPT-5.4 et GPT-5.5 côte à côte, mêmes prompts, mêmes paramètres de température, mêmes définitions d’outils. Des benchmarks indépendants comme la comparaison publiée sur LLM Stats montrent que GPT-5.5 progresse sur 9 des 10 benchmarks communs mais n’obtient que des gains marginaux sur SWE-Bench Pro. Traduction : la mise à niveau est réelle, mais elle n’est pas uniformément meilleure. C’est votre charge de travail qui décide.
Décidez de votre chemin de repli maintenant, pas après le premier 429. Les nouvelles versions de modèles arrivent historiquement avec des limites de débit plus strictes pendant les 30 premiers jours. Ayez GPT-5.4 câblé en secours avant de basculer la moindre requête de production. J’ai vu deux équipes ignorer cette étape par le passé et le payer lors d’un pic de trafic le jour du lancement.
Questions pour les achats, la sécurité et l’ingénierie
Quelques-unes auxquelles j’ai dû répondre cette semaine :
- Les prix ont doublé. Le tarif standard est de $5 pour 1M tokens d’entrée et $30 pour 1M tokens de sortie, selon la page officielle de tarification OpenAI. Le tarif Pro est de $30 / $180. Les arguments d’efficacité en tokens compensent partiellement cela sur les charges de travail Codex, mais sur la plupart des autres charges de travail, attendez-vous à ce que votre facture grimpe sensiblement.
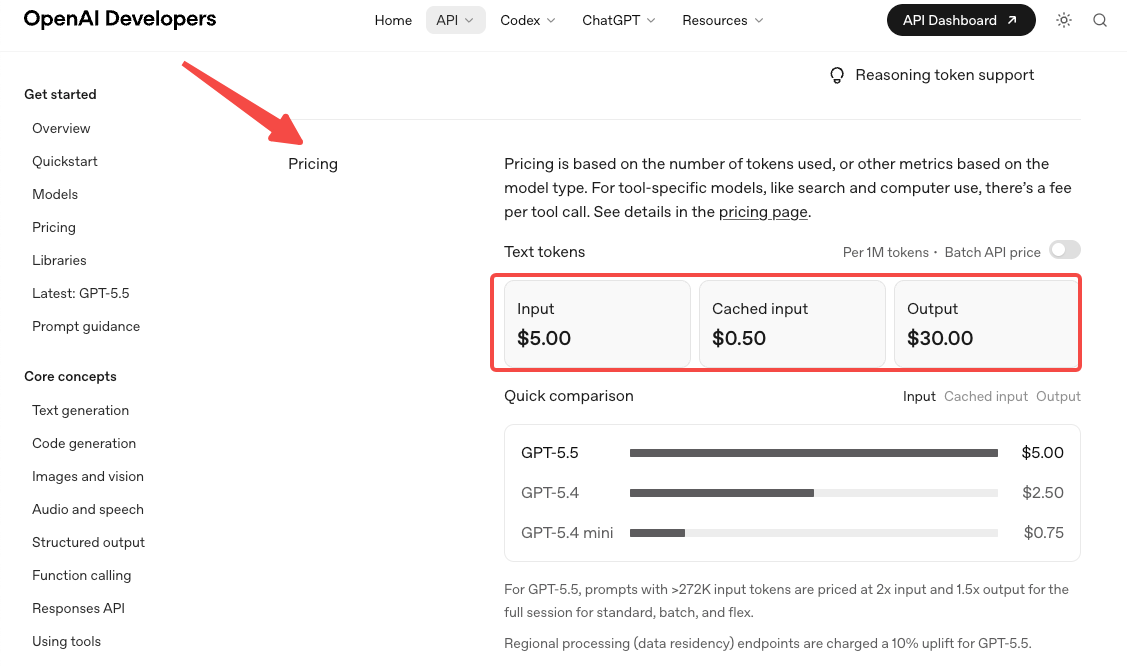
- La tarification du contexte long change à 272K. Au-delà de ce seuil, l’entrée est 2x et la sortie est 1,5x pour toute la session. Si votre workflow dépasse régulièrement 272K tokens, modélisez votre coût deux fois — une fois en dessous du seuil, une fois au-dessus. Cela concerne les équipes qui ont construit autour de la structure de niveaux de GPT-5.4 et ont supposé que le nouveau modèle l’hériterait.
- La sécurité doit lire la fiche système. GPT-5.5 est livré avec des classificateurs cyber plus stricts, documentés dans la fiche système de GPT-5.5. Certaines charges de travail légitimes seront bloquées initialement pendant qu’OpenAI les ajuste. Vaut la peine de le signaler à quiconque fait tourner des outils de sécurité, des pipelines d’analyse de code ou des workflows red-team via l’API.
Ce qui doit encore être vérifié avant une utilisation en production
Identifiants de modèles, limites de débit, tarification et support d’outils
Je vérifierais dans cet ordre :
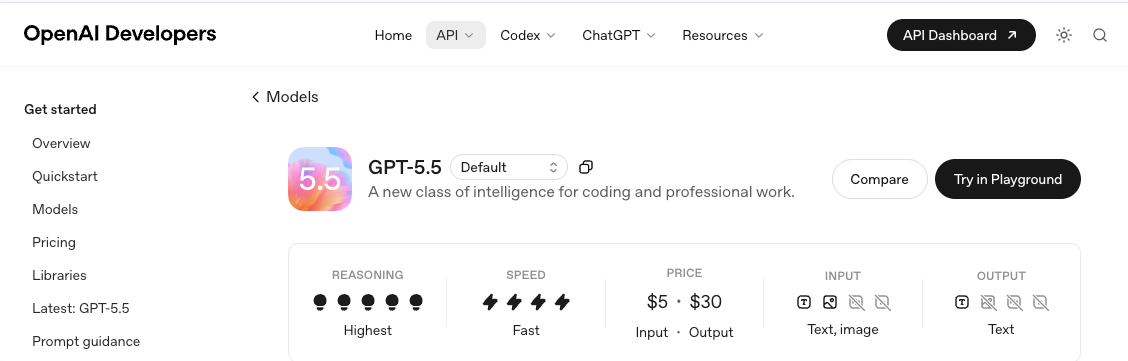
1.Identifiants de modèles et snapshots. Verrouillez sur un snapshot, pas sur l’alias. Les alias changent ; les snapshots non. Vérifiez la liste disponible sur la page du modèle GPT-5.5 avant de coder en dur quoi que ce soit dans votre client.
2.Les limites de débit de votre niveau. Le système de niveaux d’OpenAI se promeut automatiquement en fonction des dépenses, mais les limites du jour de lancement peuvent être plus strictes que ce dont profite GPT-5.4 aujourd’hui. La documentation sur les limites de débit d’OpenAI est mon point de départ, et il vaut la peine d’exécuter un test de rafale synthétique sur votre niveau actuel avant de supposer que la marge existe.
3.Comportement des outils et des sorties structurées. L’appel de fonctions, la recherche web et les sorties structurées fonctionnent toutes, mais les schémas exacts et les interactions en mode raisonnement nécessitent un test de fumée par rapport à vos définitions d’outils réelles. J’ai vu des paramètres d’effort de raisonnement modifier le comportement des nouvelles tentatives d’une manière qui n’apparaît pas avant d’atteindre le trafic de production.
Débit et détails du déploiement en entreprise
Pour ceux qui font tourner des volumes sérieux : Batch et Flex s’exécutent à la moitié du tarif standard, Priority à 2,5x. Traduction : si votre travail tolère l’asynchrone, Batch sur GPT-5.5 coûte le même prix par token que GPT-5.4 en standard. C’est le vrai arbitrage caché dans cette version, et presque personne à qui j’ai parlé ne l’a encore pris en compte. La décomposition des tarifs de GPT-5.5 sur apidog détaille mieux les exemples concrets que je ne le ferai ici.
Planification directe chez le fournisseur vs préparation basée sur une plateforme
Je travaille dans une plateforme qui agrège l’accès aux modèles, donc mon biais est sur la table. Mais l’argument structurel est le même quelle que soit la plateforme que vous utilisez : quand un seul fournisseur sort un modèle au prix doublé dès le premier jour, le cas pour une logique de routage se renforce, pas l’inverse.
L’intégration directe chez le fournisseur ressemble à ceci : réécrire votre client, retester vos prompts, refaire votre modèle de coût, répéter par fournisseur. Les plateformes multi-modèles — WaveSpeedAI inclus, mais aussi d’autres — vous permettent de changer de modèle avec un changement de configuration. Le compromis est que vous ajoutez une couche entre vous et la source. Pour les équipes à haute fréquence qui livrent quotidiennement, cette couche vaut généralement l’abstraction. Pour une équipe qui fait tourner un modèle sur une charge de travail à faible volume, ce n’est pas le cas.
Je planifierais une configuration de routage dans tous les cas. Requêtes premium vers GPT-5.5, trafic de routine vers GPT-5.4 ou un autre modèle frontier — ce schéma seul tend à réduire les factures de 40 à 60 % par rapport aux valeurs par défaut à modèle unique, quel que soit le fournisseur sur lequel vous vous centrez.
FAQ
GPT-5.5 est-il déjà lancé dans l’API ?
Oui, depuis le 24 avril 2026. Le lancement du 23 avril ne couvrait que ChatGPT et Codex ; l’API a suivi un jour plus tard. gpt-5.5 et gpt-5.5-pro sont accessibles dans les endpoints Responses et Chat Completions avec une fenêtre de contexte de 1M tokens.
Que doivent vérifier les équipes avant de commencer les travaux d’intégration ?
L’impact tarifaire sur votre mix de tokens réel, les plafonds de limite de débit sur votre niveau actuel, le repli vers GPT-5.4 câblé et testé, et un court dispositif d’évaluation comparant les deux modèles sur votre charge de travail réelle. Verrouillez sur un ID de snapshot, pas sur l’alias.
Vaut-il mieux attendre plutôt que d’utiliser GPT-5.4 ?
Cela dépend de la charge de travail. Pour les tâches de codage agentique et d’utilisation par ordinateur, GPT-5.5 montre des gains significatifs, comme documenté dans la couverture du lancement par TechCrunch. Pour les charges de travail où GPT-5.4 répond déjà à votre niveau de qualité, le prix par token doublé est difficile à justifier sans un gain mesurable.
Comment les équipes doivent-elles se préparer à un déploiement API rapide ?
Construisez le dispositif d’évaluation maintenant, routez via une couche d’abstraction si ce n’est pas déjà le cas, et supposez que les limites de débit se resserreront avant de se desserrer. Ne prépayez pas de gros soldes de crédits — la tarification de cette génération est encore en mouvement.
Le prix doublé signifie-t-il vraiment des factures doublées ?
Non, mais presque. Les gains d’efficacité en tokens sur les charges de travail Codex ramènent les factures réelles en dessous de 2x. Sur les autres charges de travail, attendez-vous à être plus proche de l’affichage. Le traitement par lots à moitié tarif est le levier à activer en premier.
Conclusion
L’API est en ligne. La tarification a changé. Les limites de débit se stabilisent encore. Rien de tout cela ne signifie que vous devriez vous précipiter. Ce que cela signifie, c’est que la fenêtre de planification que la plupart des équipes espéraient s’est fermée plus vite que prévu, et que le travail maintenant est la vérification plutôt que l’attente.
Je mène ma propre migration au cours des deux prochaines semaines. Si GPT-5.5 reste dans mon routage par défaut après ce point — je ne sais pas encore. C’est à ça que sert l’évaluation.
La suite arrive.
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué

API GLM-5.2 : Tarification, contexte 1M et routage en production

Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie

API MAI-Image-2.5 : Ce que les développeurs doivent savoir
