Capacités de Cybersécurité de Claude Mythos : Ce que les Équipes de Développeurs et de Sécurité Doivent Savoir
Claude Mythos a soulevé de sérieuses préoccupations en matière de cybersécurité. Voici ce que les affirmations divulguées signifient pour les équipes de développeurs et de sécurité qui évaluent ce modèle.

“Devrions-nous nous en inquiéter ?” Le message de l’équipe de sécurité du client est arrivé sur Slack pendant que je passais en revue les options d’outils IA internes et que l’histoire de la fuite chez Anthropic est apparue dans mon fil d’actualité.
Disponible sur WaveSpeedAI — tarification transparente par token, endpoint compatible OpenAI. Claude Opus 4.7 API → · Ouvrir le Playground →
Cette question est revenue sans cesse au cours des 48 heures suivantes. Non pas de la part d’enthousiastes de l’IA, mais de RSSI, de responsables sécurité et de développeurs qui construisent sur une infrastructure IA et se sont soudainement retrouvés dans une conversation pour laquelle ils n’étaient pas préparés.
L’histoire Mythos n’est pas qu’une simple annonce de produit IA. C’est un signal sur l’évolution de l’environnement des menaces, et comprendre ce qui est réellement confirmé par rapport à ce qui relève de la spéculation est plus important qu’à l’ordinaire lorsqu’un nouveau modèle sort. Dans cet article, nous allons explorer ensemble la réponse à cette question.
Ce que le brouillon divulgué a révélé sur les capacités cybersécurité de Mythos
Le brouillon de billet de blog divulgué — faisant partie de près de 3 000 actifs internes exposés — contenait deux affirmations frappantes sur la cybersécurité qui ont été largement citées. Les propres mots d’Anthropic, rédigés en interne avant toute annonce publique, décrivaient le modèle non publié (en interne lié au niveau “Capybara” et désigné sous le nom de Claude Mythos) comme “actuellement bien en avance sur tout autre modèle IA en matière de capacités cyber.” Il avertissait en outre que le modèle “préfigure une vague prochaine de modèles capables d’exploiter des vulnérabilités d’une manière qui surpasse largement les efforts des défenseurs.”
Un deuxième passage clé faisait preuve d’une prudence inhabituelle : “En préparant la sortie de Claude Mythos, nous souhaitons agir avec une prudence supplémentaire et comprendre les risques qu’il pose — même au-delà de ce que nous apprenons lors de nos propres tests. En particulier, nous souhaitons comprendre les risques potentiels à court terme du modèle dans le domaine de la cybersécurité — et partager les résultats pour aider les défenseurs cyber à se préparer.”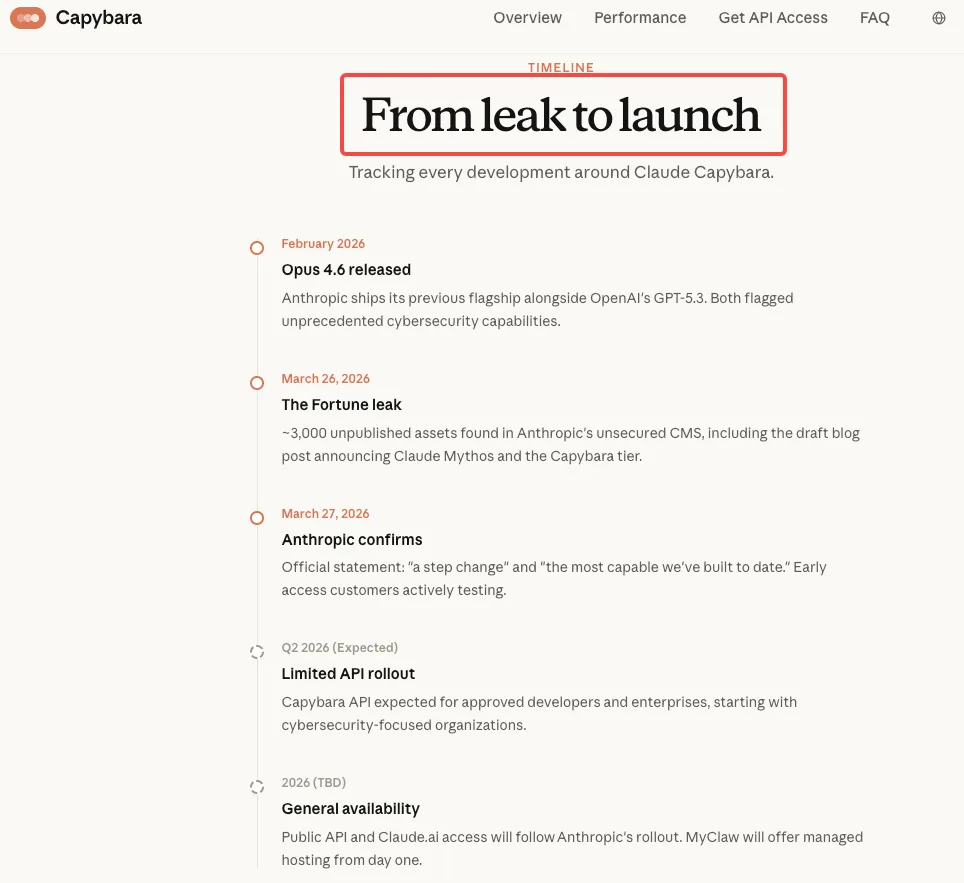
Cette formulation traite le risque cybersécurité non pas comme une limitation gérable, mais comme une externalité significative nécessitant un partage proactif avec les défenseurs. C’est une posture sensiblement différente des précédentes publications d’Anthropic.
Qu’est-ce qui manque dans la fuite ? Des chiffres de référence spécifiques, des catégories d’exploitation ou une méthodologie détaillée. Les affirmations de “scores considérablement plus élevés sur les tests de cybersécurité” représentent l’étendue complète des capacités divulguées. Tout ce qui est plus spécifique qui circule en ligne relève de l’extrapolation.
Pourquoi Anthropic traite cela comme un risque sans précédent
Ce que signifie réellement “Bien en avance sur tout autre modèle IA en matière de capacités cyber”
Cette affirmation prend une toute autre dimension si l’on comprend ce dont Opus 4.6 — la base de référence actuelle — est déjà capable. Ce n’est pas Mythos surpassant un faible standard.
En utilisant Claude Opus 4.6, la Frontier Red Team d’Anthropic a trouvé et validé plus de 500 vulnérabilités de haute sévérité dans des bases de code open-source en production — des bugs qui étaient passés inaperçus pendant des décennies, malgré des années de revue par des experts. L’équipe n’a utilisé aucune instruction spécialisée ni aucun dispositif personnalisé, en s’appuyant uniquement sur les capacités prêtes à l’emploi du modèle.
Un cas notable : Opus 4.6 a identifié une injection SQL aveugle dans Ghost CMS (une plateforme avec plus de 50 000 étoiles GitHub et un historique de sécurité jusque-là irréprochable) en environ 90 minutes.
La différence structurelle entre la découverte de vulnérabilités assistée par IA et le fuzzing traditionnel est un contexte important. Les fuzzers envoient des entrées dans le code jusqu’à ce que quelque chose se brise. Claude raisonne sur le code : traçant la logique entre les composants, lisant l’historique des commits pour trouver des variantes non corrigées de bugs résolus, et évaluant quels chemins de code sont intrinsèquement risqués plutôt que d’étudier chaque entrée possible. Mythos, selon l’évaluation interne d’Anthropic, fait cela mieux que tout ce qui est actuellement disponible — avec une marge significative.
Le problème du fossé défenseur : pourquoi l’offense pourrait surpasser la défense
L’insight le plus important du brouillon n’était pas de cataloguer de nouveaux types d’attaques. C’était d’articuler pourquoi l’asymétrie attaquant-défenseur existe en premier lieu. Les attaquants doivent trouver une seule faiblesse. Les défenseurs doivent tout couvrir. Un modèle IA capable de raisonner sur le code, d’identifier des schémas de vulnérabilité potentiels et d’aider à l’affinement des exploits comprime le temps entre “l’idée” et “l’attaque fonctionnelle.”
Anthropic aurait averti de hauts responsables gouvernementaux que Mythos pourrait rendre les cyberattaques à grande échelle plus probables en 2026 en permettant des agents autonomes très sophistiqués. Un sondage Dark Reading du début 2026 a révélé que 48 % des professionnels de la cybersécurité classent désormais l’IA agentique comme le principal vecteur d’attaque de l’année — devant les deepfakes et l’ingénierie sociale.
Ce n’est pas un problème que Mythos crée de toutes pièces ; c’est un accélérateur. Les adversaires utilisent déjà l’IA sans hésitation ni friction de conformité. Les défenseurs qui s’auto-restreignent dans l’accès aux modèles frontier risquent de céder un terrain critique.
Applications défensives vs offensives : où se trouve la ligne
Cas d’usage légitimes : scan de vulnérabilités, red teaming, durcissement du code
Les applications défensives des capacités de Mythos sont véritablement significatives — et c’est la principale raison pour laquelle Anthropic construit et publie cela.
Claude Code Security, une nouvelle capacité intégrée à Claude Code, analyse les bases de code à la recherche de vulnérabilités de sécurité et suggère des correctifs logiciels ciblés pour examen humain, permettant aux équipes de trouver et corriger des problèmes de sécurité que les méthodes traditionnelles manquent souvent. Rien n’est appliqué sans approbation humaine : Claude Code Security identifie les problèmes et suggère des solutions, mais les développeurs prennent toujours la décision finale.
La capacité de niveau Mythos appliquée à ce workflow signifierait trouver des classes de vulnérabilités que même Opus 4.6 manque — des failles dépendantes du contexte dans la logique métier, des schémas d’interaction multi-composants, des contournements d’authentification nécessitant de comprendre l’architecture système plutôt que les schémas de code. Pour les équipes de sécurité qui paient actuellement des tests de pénétration manuels sur un cycle trimestriel, le scan continu piloté par IA à la qualité de raisonnement de niveau Mythos représente un changement significatif dans ce qui est opérationnellement réalisable.
Pour les red teams, la même puissance nécessite un cadrage et une autorisation stricts. Le modèle lui-même ne fait pas la distinction entre les tests autorisés et l’utilisation malveillante — cette responsabilité reste avec vos processus et garde-fous.
Ce qu’Anthropic fait pour limiter les abus
Parallèlement à Opus 4.6, Anthropic a déployé des sondes au niveau de l’activation pour détecter et bloquer les abus cyber en temps réel, reconnaissant une friction potentielle pour la recherche en sécurité légitime. “Cela créera de la friction pour la recherche légitime et certains travaux défensifs, et nous voulons travailler avec la communauté de recherche en sécurité pour trouver des moyens d’y remédier au fur et à mesure,” a averti l’entreprise.
Pour Mythos spécifiquement, les contrôles sont structurels plutôt que simplement techniques. Sur la base des documents divulgués et des déclarations publiques d’Anthropic, l’accès initial est restreint aux chercheurs en sécurité et défenseurs vérifiés — l’objectif est de construire des outils défensifs avant que les capacités offensives ne deviennent largement disponibles. Cela reflète la gestion par Anthropic des précédentes publications à haut risque et s’aligne sur les pratiques recommandées par le cadre de gestion des risques IA du NIST, qui préconise un déploiement par étapes avec une surveillance continue pour les systèmes IA à double usage.
La section sur les tactiques IA adversariales du cadre MITRE ATT&CK mérite d’être examinée par toute équipe de sécurité cherchant à modéliser la surface de menace ici. Les tactiques documentées supposent des modèles considérablement moins capables que ce que représente Mythos.
Ce qu’évaluent les clients de sécurité en accès anticipé
Le brouillon divulgué était explicite sur la priorité de déploiement d’Anthropic : “Nous allons lentement étendre l’accès à Claude Mythos à davantage de clients utilisant l’API Claude au cours des prochaines semaines. Puisque nous sommes particulièrement intéressés par les usages en cybersécurité, c’est là que nous visons à étendre l’EAP initialement.”
La cohorte d’accès anticipé évalue Mythos par rapport au problème spécifique pour lequel le modèle a été conçu : trouver des vulnérabilités dans des bases de code de production durcies plus rapidement et plus complètement que les outils existants. Les analystes notent qu’il pourrait comprimer le fossé offense-défense dans les deux sens — permettant une découverte plus rapide des vulnérabilités, un red teaming continu et la chasse aux menaces, tout en abaissant la barre pour les attaques sophistiquées en cas d’utilisation abusive.
Pour les clients de sécurité actuellement en période d’évaluation, les questions pratiques se concentrent sur trois domaines : comment Mythos s’intègre aux flux de travail SIEM et de gestion des vulnérabilités existants, si les résultats du modèle peuvent être présentés dans des formats compatibles avec les systèmes de ticketing existants, et à quoi ressemblent les exigences de revue humaine à grande échelle.
Dans des entretiens avec plus de 40 RSSI dans différents secteurs, VentureBeat a constaté que les cadres de gouvernance formels pour les outils de scan basés sur le raisonnement sont l’exception, pas la norme. Les réponses les plus courantes étaient que le domaine était considéré comme si naissant que de nombreux RSSI ne pensaient pas que cette capacité arriverait aussi tôt en 2026. Les équipes au sein du programme d’accès anticipé écrivent, dans un sens réel, le manuel de gouvernance que le reste de l’industrie suivra.
Implications pour les équipes de développeurs construisant sur une infrastructure IA
Si votre équipe construit des produits sur Claude ou tout autre modèle IA frontier, la situation Mythos crée deux catégories distinctes de préoccupations.
La première est directe : vous êtes une cible potentielle pour les attaques assistées par IA, et ces attaques deviennent de plus en plus capables.
La deuxième préoccupation est architecturale : comment votre infrastructure IA est sécurisée contre l’injection de prompt, l’accès non autorisé aux outils et l’abus d’agents. Les organisations doivent traiter chaque agent, bot et service IA comme une identité, en apportant le même niveau de contrôles, d’autorisations et de supervision aux identités non humaines qu’aux utilisateurs humains — en exigeant un inventaire des accès et en éliminant les identifiants codés en dur qui créent des bots non sécurisés.
Concrètement, cela signifie plusieurs choses pour les équipes construisant sur Claude aujourd’hui :
Limitez strictement l’accès aux serveurs MCP. Chaque serveur MCP que vous connectez à un agent Claude est une surface d’attaque potentielle. Les capacités agentiques étendues qui rendent Claude Code puissant font également des permissions d’agents mal délimitées un vecteur de risque significatif.
Traitez CLAUDE.md comme un document de sécurité. Les instructions dans CLAUDE.md qui définissent quels outils un agent peut utiliser, quels fichiers il peut lire et quelles opérations il peut effectuer sont des contrôles de sécurité, pas seulement des aides à la productivité. Un CLAUDE.md mal rédigé qui accorde un accès étendu aux fichiers ou des permissions d’outils amplifie le risque.
Appliquez la revue humaine aux correctifs générés par IA, pas seulement au code généré par IA. Le code généré par IA est 2,74 fois plus susceptible d’introduire des vulnérabilités XSS et 1,91 fois plus susceptible d’introduire des références d’objets non sécurisées par rapport au code écrit par des humains. La même capacité de raisonnement qui trouve des vulnérabilités peut en introduire. La revue humaine des changements pertinents pour la sécurité n’est pas optionnelle.
FAQ
Les équipes de sécurité peuvent-elles accéder à Claude Mythos maintenant ?
Pas par un canal public. Le plan de déploiement du modèle reflète la préoccupation en matière de cybersécurité : l’accès anticipé est restreint aux organisations de cybersécurité défensive vérifiées. Pour les équipes de sécurité souhaitant se préparer, Claude Code Security — construit sur Opus 4.6, disponible dès maintenant en aperçu de recherche limité pour les clients Enterprise et Team — est l’outil le plus proche accessible au public, et une base utile pour comprendre ce que la capacité de niveau Mythos permettrait d’étendre.
Quelles mesures de protection Anthropic met-il en place ?
Les mesures confirmées incluent des sondes de détection des abus en temps réel, un déploiement par étapes priorisant les défenseurs, et des exigences d’intervention humaine pour les correctifs. Pour Mythos, l’accent est mis sur la gouvernance du déploiement, les limites des outils et les pistes d’audit.
Claude Mythos sera-t-il disponible pour le red teaming commercial ?
Non confirmé. La cohorte d’accès anticipé est axée sur les cas d’usage de sécurité défensive. Le red teaming commercial — où les organisations embauchent des entreprises de sécurité pour sonder activement leurs systèmes — se situe dans une zone ambiguë : c’est de l’offense autorisée. Compte tenu de la préoccupation déclarée de l’entreprise concernant les abus offensifs, attendez-vous à des contrôles d’accès significatifs plutôt qu’à un accès API ouvert pour les cas d’usage de red teaming.
Articles précédents :
- Claude Mythos vs Claude Opus 4.6 : Ce que la fuite révèle pour les développeurs
- Claude Mythos (Opus 5) divulgué : Ce que nous savons jusqu’à présent
- Qu’est-ce que Claude Mythos ? Fuite, niveau Capybara et ce qu’Anthropic a confirmé
- Claude Sonnet 4.6 : Un modèle de travail “sans accaparement des projecteurs”
- Claude Opus 4.6 et Sonnet 4.6 : Tout ce que vous devez savoir
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué
API GLM-5.2 : Tarification, contexte 1M et routage en production
Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie
API MAI-Image-2.5 : Ce que les développeurs doivent savoir