Tarification des agents gérés Claude et limites bêta
Les agents gérés Claude facturent les tokens plus 0,08 $/heure de session d'exécution, avec la recherche web à 10 $/1 000 appels. Voici ce que signifie la structure de facturation bêta pour votre charge de travail.

J’ai consulté notre feuille de coûts d’infrastructure d’agents hier et je l’ai regardée un moment. Je m’appelle Dora. Nous exploitons une boucle d’agent auto-hébergée — orchestration d’outils, sandboxing, récupération d’erreurs, logique de points de contrôle — et elle consomme environ 0,4 du temps d’un ingénieur rien que pour l’empêcher de s’effondrer. Quand Anthropic a lancé Claude Managed Agents le 8 avril, la première chose que j’ai faite n’a pas été de lire la liste des fonctionnalités. J’ai ouvert la page de tarification.
Cet article documente à quoi ressemble réellement la structure de facturation lorsqu’on fait les calculs, où se situent les limites de débit, et ce qui reste incertain en raison du label bêta.
Comment est tarifé Claude Managed Agents
Facturation en deux parties : tokens + durée de session
La facturation de Managed Agents comporte deux dimensions : les tokens et la durée de session. Les tokens sont facturés aux tarifs standard du modèle Claude API — le même prix par million de tokens que vous paieriez via l’API Messages. Opus 4.6 coûte 5 $ en entrée / 25 $ en sortie par MTok. Sonnet 4.6 est à 3 $ / 15 $. Les multiplicateurs de mise en cache des prompts s’appliquent de manière identique : les lectures de cache coûtent 10 % du prix d’entrée de base.
La deuxième dimension est le frais d’infrastructure pour le conteneur géré.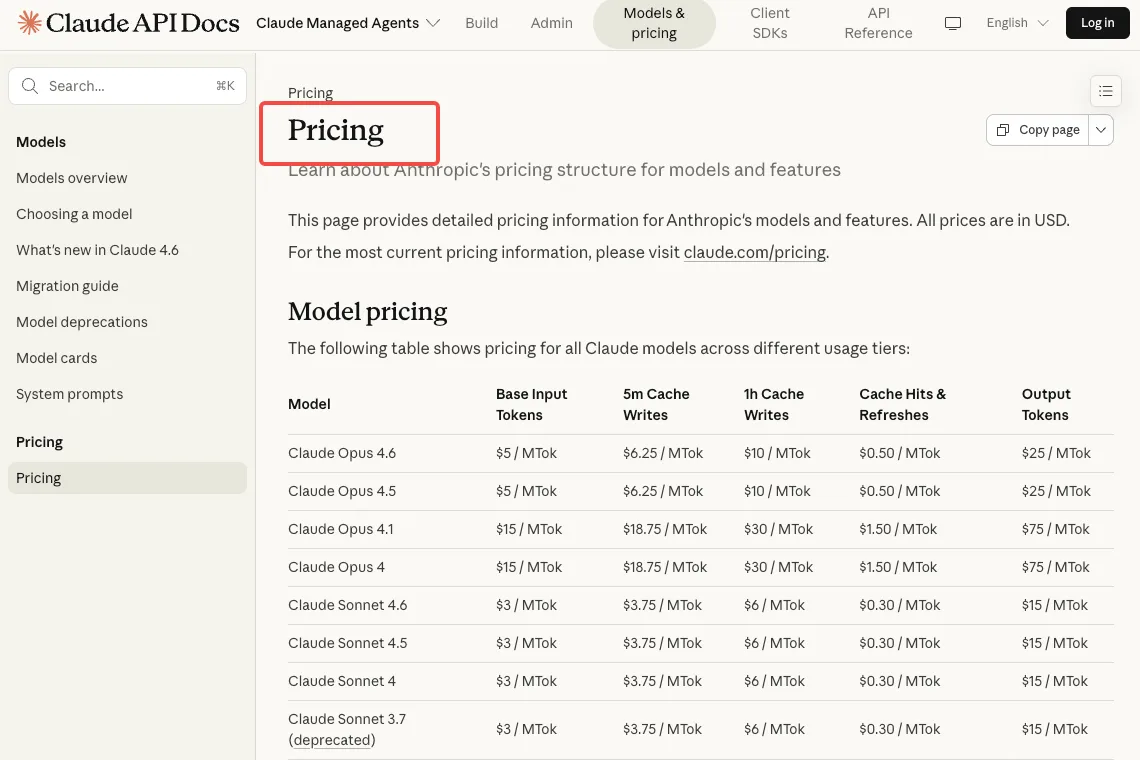
Durée de session : 0,08 $ par heure de session
Le frais de durée est de 0,08 $ par heure de session pour la durée active, facturé à la consommation. C’est le coût d’infrastructure du conteneur sandbox dans lequel votre agent s’exécute.
Un détail à noter : la durée de session remplace le modèle de facturation à l’heure de conteneur Code Execution lors de l’utilisation de Managed Agents — vous n’êtes pas facturé en double.
Recherche web : 10 $ par 1 000 recherches
La recherche web déclenchée dans une session Managed Agents coûte le tarif standard de 10 $ par 1 000 recherches. Même tarif que l’API autonome. Un agent de recherche qui effectue des dizaines de recherches web par session ressentira cet élément de coût.
Disponible uniquement via l’API Claude directement
Managed Agents est facturé directement via la Plateforme Claude. La tarification des plateformes tierces — Bedrock, Vertex AI, Foundry — ne s’applique pas ici. Si vous exécutez des agents via l’un de ces fournisseurs, il s’agit d’une relation de facturation distincte.
Coût de durée de session : ce que cela signifie en pratique
Ce qui compte comme durée de session
La durée est mesurée à la milliseconde et ne s’accumule que lorsque le statut de la session est running. Le temps d’inactivité — attendre votre prochain message, une confirmation d’outil, ou rester en état terminé — ne compte pas. Le compteur s’arrête lorsque l’agent n’a rien à faire.
Cela importe plus qu’il n’y paraît. Un agent qui termine une tâche et attend 20 minutes une entrée utilisateur ne consomme pas 0,08 $/h pendant ces 20 minutes.
Agents à longue durée vs agents à tâches courtes
Un travail de traitement de fichiers de 10 minutes sur Sonnet 4.6 coûte environ 0,013 $ en durée. À peine perceptible. Le coût des tokens domine.
Une session d’agent de recherche de 4 heures sur Opus 4.6 est différente. Cela représente 0,32 $ en durée, mais si l’agent raisonne activement à travers des chaînes d’outils complexes, vous pourriez consommer plus de 200 000 tokens d’entrée et 50 000 tokens de sortie. La facture de tokens seule pourrait dépasser 1,25 $ avant que la mise en cache entre en jeu.
Exemple d’estimation de coût
Voici l’exemple détaillé tiré de la documentation de tarification d’Anthropic : une session de codage d’une heure sur Opus 4.6 consommant 50 000 tokens d’entrée et 15 000 tokens de sortie coûte environ 0,70 $ au total. Avec la mise en cache des prompts active et 40 000 de ces entrées atteignant le cache, cela diminue sensiblement. La durée représente 0,08 $ de ce total.
La vraie question n’est pas “est-ce que 0,08 $/heure est cher ?” C’est “quel est l’appétit en tokens de la boucle d’outils de mon agent ?” Chaque commande bash, lecture de fichier, récupération web et recherche web contribue des tokens. Une session très agentique avec des dizaines d’appels d’outils consomme rapidement le contexte.
Limites de débit et quotas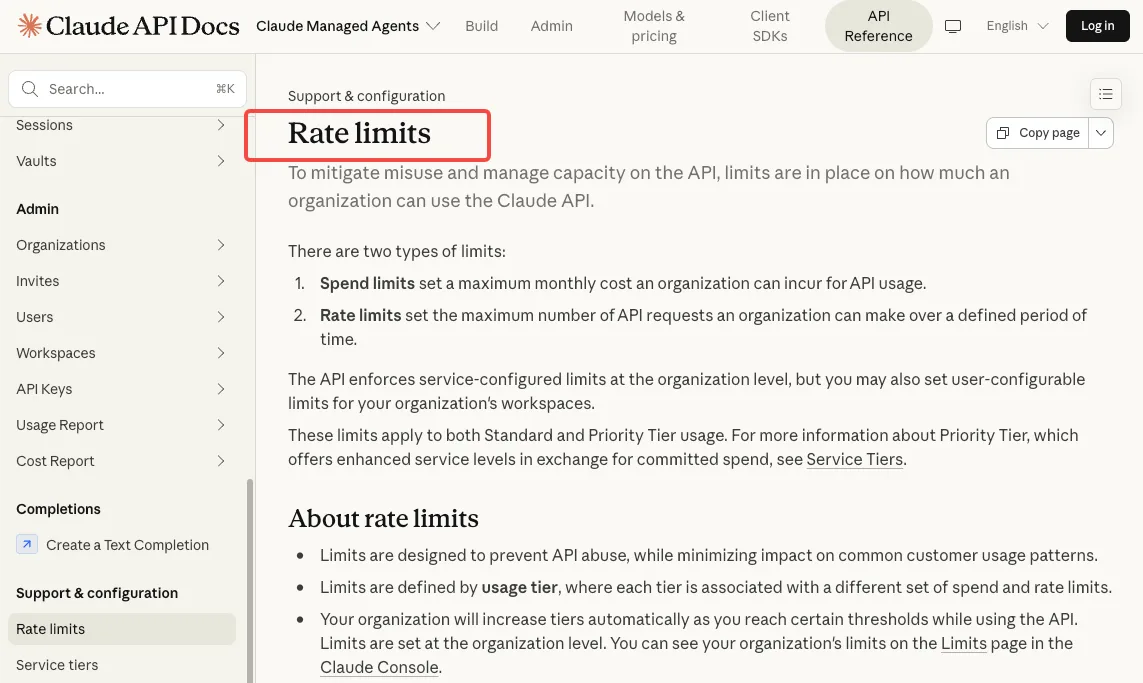
Points de terminaison de création : 60 requêtes par minute
Les points de terminaison Managed Agents sont limités par organisation, et ces limites sont distinctes des limites de débit de l’API Messages. Les points de terminaison de création autorisent 60 RPM au niveau de l’organisation.
Points de terminaison de lecture : 600 requêtes par minute
Les points de terminaison de lecture sont limités à 600 RPM au niveau de l’organisation. Si vous interrogez fréquemment l’état des sessions sur de nombreux agents simultanés, c’est le plafond que vous atteindrez en premier.
Les limites de dépenses au niveau de l’organisation et les limites de débit par niveau s’appliquent également
Les limites de débit standard par niveau s’ajoutent par-dessus. Les limites de tokens par minute et de requêtes par minute de votre niveau API s’appliquent toujours aux appels de modèle sous-jacents effectués par vos agents.
Comment demander des limites plus élevées
Pour les charges de travail en production nécessitant plus de marge, Anthropic propose un Niveau Prioritaire avec un engagement de dépenses. Contactez leur équipe commerciale via la Console Claude pour des arrangements de limites de débit personnalisés. Les graphiques de limites de débit de la Console affichent la marge en temps réel — utilisez-les pour voir quand vous approchez des limites avant de recevoir des erreurs 429.
En-tête bêta et ce qui change lors de la disponibilité générale
managed-agents-2026-04-01 : requis sur chaque requête
Tous les points de terminaison Managed Agents nécessitent l’en-tête bêta managed-agents-2026-04-01. Le SDK le définit automatiquement. Si vous utilisez cURL brut ou un client HTTP personnalisé, ajoutez-le manuellement à chaque requête.
Incertitude en période bêta
La documentation officielle indique que les comportements peuvent être affinés entre les versions pour améliorer les résultats. C’est une mise en garde standard pour les bêtas.
Je veux être précise sur ce que cela signifie pour la tarification. Ce n’est pas une annonce qu’Anthropic prévoit de modifier la tarification lors de la disponibilité générale. Cela signifie que les chiffres actuels ne constituent pas un engagement contractuel permanent — ce qui est vrai pour toute tarification en période bêta, partout. Intégrez cette incertitude dans vos modèles de coûts, mais ne le lisez pas comme un signal de changements de prix imminents.
Les fonctionnalités en aperçu de recherche restent limitées
Certaines fonctionnalités — les outcomes, la coordination multi-agents et la mémoire — sont en aperçu de recherche et nécessitent des demandes d’accès séparées. Celles-ci pourraient avoir des implications de coûts supplémentaires lorsqu’elles quitteront l’aperçu. Je ne sais pas encore. Personne en dehors d’Anthropic non plus.
Interactions avec l’API Batch et la mise en cache
API Batch : non disponible pour Managed Agents
C’est celui qui va surprendre les gens. Les modificateurs de l’API Messages, y compris l’API Batch, ne s’appliquent pas aux sessions Claude Managed Agents. Si vous avez compté sur la remise de 50 % pour le traitement en masse, vous ne pouvez pas reproduire cette structure de coûts avec Managed Agents. Il s’agit d’une limitation confirmée, pas d’un élément de feuille de route.
Mise en cache des prompts : intégrée
La mise en cache des prompts est intégrée dans le harnais Managed Agents. Les multiplicateurs standard s’appliquent — les écritures en cache à 1,25x le prix d’entrée de base pour un TTL de 5 minutes, les lectures en cache à 0,1x. Pour les sessions longues où le prompt système et le contexte initial sont réutilisés à travers de nombreux appels d’outils, la mise en cache peut réduire sensiblement la facture de tokens.
Compaction : intégrée
Le harnais prend en charge la compaction intégrée et d’autres optimisations de performance pour des sorties d’agents efficaces. Pour les sessions qui s’étendent suffisamment longtemps pour approcher les limites de la fenêtre de contexte, la compaction résume automatiquement les tours de conversation antérieurs. Cela aide à gérer l’accumulation de tokens sans que vous ayez à construire une stratégie de troncature personnalisée.
Considérations sur les coûts cachés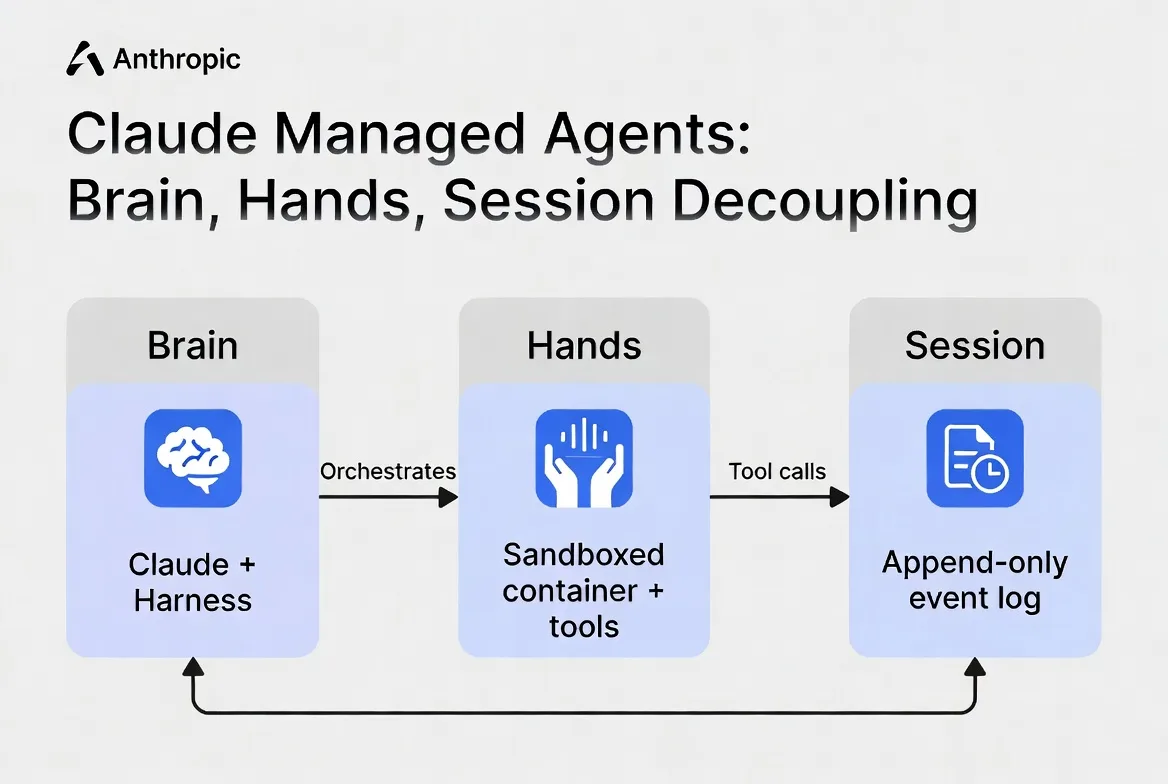
Surcharge d’exécution des outils
Chaque appel d’outil génère des tokens. Les commandes bash, les lectures de fichiers, les récupérations web — chacune ajoute des tokens d’entrée et de sortie à votre total de session. Un agent de recherche qui enchaîne 30+ appels d’outils dans une seule session accumulera des coûts de tokens qui éclipsent les 0,08 $/heure de frais de durée.
La recherche web à 10 $/1 000 appels est le coût par appel le plus visible. Mais le moins visible est la surcharge de tokens provenant des résultats des outils qui reviennent dans le contexte. Une récupération web qui renvoie une longue page déverse des milliers de tokens dans votre session.
Fonctionnalités en aperçu de recherche : multiplicateur de coûts potentiel
La coordination multi-agents — où les agents peuvent lancer et diriger d’autres agents — est disponible en aperçu de recherche. Chaque sous-agent exécute sa propre session avec sa propre consommation de tokens et son propre compteur de durée. Le multiplicateur de coûts dépend du nombre de sous-agents lancés et de la durée d’exécution de chacun. Je n’ai pas pu vérifier si les sessions de sous-agents comportent des frais de durée séparés ou partagent ceux du parent. C’est un point à surveiller.
FAQ
Claude Managed Agents est-il gratuit pendant la bêta ?
Non. La tarification à la consommation est active maintenant — tarifs standard des tokens plus 0,08 $ par heure de session pour la durée active. Il n’y a pas de niveau gratuit spécifiquement pour Managed Agents. Les nouveaux utilisateurs de l’API reçoivent une petite quantité de crédits gratuits pour les tests initiaux, mais ce sont les crédits d’intégration API standard, pas un avantage Managed Agents.
Comment fonctionne la facturation de la durée de session pour les agents asynchrones ?
La durée ne s’accumule que lorsque le statut de la session est running. Si un agent termine une tâche et entre en inactivité — attendant le prochain message utilisateur ou une confirmation d’outil — ce temps d’inactivité ne coûte rien. Le compteur s’arrête et reprend lorsque le traitement redémarre. La mesure est à la milliseconde.
Puis-je utiliser la remise de l’API Batch avec Managed Agents ?
Non. La remise de 50 % de l’API Batch ne s’applique pas. Si les économies au niveau du batch sont essentielles à votre flux de travail, évaluez si les économies d’infrastructure provenant de l’hébergement géré compensent la perte de la remise batch. Pour certaines charges de travail, exécuter votre propre boucle d’agent sur l’API Messages avec traitement par batch sera encore moins cher.
Que se passe-t-il avec la facturation quand la bêta se termine ?
Anthropic ne s’est pas engagé sur une tarification spécifique pour la disponibilité générale. Les 0,08 $/heure de session actuels et les tarifs standard des tokens sont des chiffres de la période bêta. Le modèle de facturation persistera probablement sous une forme ou une autre, mais les chiffres spécifiques pourraient changer. Intégrez cette incertitude dans toutes les projections de coûts à long terme.
Existe-t-il un niveau gratuit ou un essai ?
Aucun essai dédié Managed Agents n’existe. Les crédits gratuits standard de l’API s’appliquent. Pour l’évaluation en entreprise, l’équipe commerciale d’Anthropic peut discuter d’arrangements d’essai prolongés — contactez-les via la Console Claude ou à sales@anthropic.com.
Voilà ce que je peux confirmer au 9 avril 2026. La structure de tarification est simple une fois que vous séparez les deux dimensions de facturation, mais la vraie variable est l’accumulation de tokens par les appels d’outils — c’est là que vos estimations divergeront de la réalité. Je continue d’exécuter des sessions de test pour mieux comprendre comment la compaction et la mise en cache interagissent à partir de la barre des 2 heures. À suivre.
Articles précédents :
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué
API GLM-5.2 : Tarification, contexte 1M et routage en production
Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie
API MAI-Image-2.5 : Ce que les développeurs doivent savoir