Claude Code Agent Harness : Analyse de l'architecture
Comment Claude Code connecte les outils, gère les permissions et orchestre les sessions d'agents — une analyse technique pour les développeurs.

Je me suis retrouvé face à la même question en construisant mon propre système d’appel d’outils : pourquoi le câblage semble-t-il tellement plus difficile que le prompting ?
La partie modèle s’est assimilée rapidement. Mais dès que j’avais besoin qu’il fasse des choses — lire des fichiers, exécuter des commandes shell, communiquer avec des services externes — chaque décision semblait pouvoir tout casser. Les limites de permissions. Les limites de contexte. La distribution des outils.
Puis, fin mars 2026, le code source de Claude Code a été accidentellement exposé via une source map npm dans la version 2.1.88. Plus de 500 000 lignes de TypeScript, dupliquées en quelques heures. Anthropic a confirmé qu’il s’agissait d’une erreur de packaging — aucune donnée client impliquée — et a commencé à émettre des avis DMCA.
Mais l’architecture est devenue de notoriété publique. Et ce qu’elle révélait n’était pas le modèle. C’était le harnais.
Une note sur les sources : Les détails présentés ici proviennent d’analyses communautaires, de reproductions open-source et de la documentation publique et du blog d’ingénierie d’Anthropic — pas du code divulgué lui-même. Les détails incertains sont signalés.
Qu’est-ce qu’un harnais d’agent ?
Définition et rôle dans les systèmes agentiques
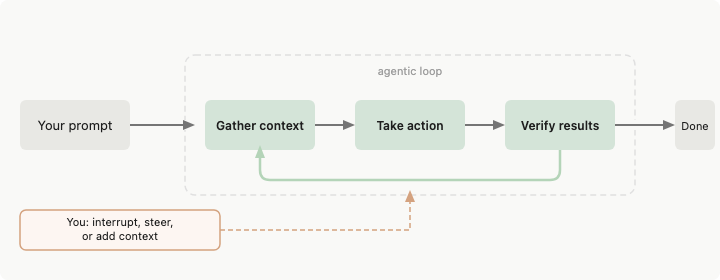
Un harnais d’agent est tout ce qui se trouve entre le modèle de langage et le monde réel. Le modèle génère du texte. Le harnais décide ce que ce texte peut toucher.
La documentation d’Anthropic pour Claude Code le décrit directement : Claude Code « fournit les outils, la gestion du contexte et l’environnement d’exécution qui transforment un modèle de langage en un agent de codage capable. » Le modèle raisonne. Le harnais agit.
Lorsque votre agent lit un fichier, le harnais décide si la lecture est autorisée, ce qui arrive au résultat, et quelle part de la réponse tient dans le prochain prompt. Le modèle ne touche jamais directement le système de fichiers.
Pourquoi la conception du harnais compte en production
La plupart des démos d’agents sautent cette partie. On voit un modèle appeler une fonction, obtenir un résultat, en appeler une autre. Ça semble propre. Puis on le lance pendant 45 minutes sur une vraie base de code, et les choses s’effondrent silencieusement — le contexte déborde, les permissions sont trop laxistes ou trop contraignantes, les résultats des outils sont tronqués sans que le modèle le sache.
L’équipe d’ingénierie d’Anthropic a écrit à ce sujet : même un modèle de pointe tournant en boucle sur plusieurs fenêtres de contexte sera sous-performant sans un harnais bien conçu. L’agent essaie de faire trop de choses à la fois, ou déclare la tâche terminée prématurément. Le harnais impose une structure à cette tendance.

La surface d’outils de Claude Code
Catégories d’outils principaux
D’après la documentation officielle de Claude Code et les analyses publiques, Claude Code expose environ 19 outils soumis à contrôle de permission. Les catégories principales : lectures et modifications de fichiers, exécution shell (Bash), opérations Git, récupération web, édition de notebooks et appels d’outils MCP. Les analyses communautaires suggèrent que le nombre pourrait être plus proche de 40 lorsqu’on inclut l’intégration LSP, la création de sous-agents et les outils de coordination interne.
Chaque outil est sandboxé indépendamment. Ce n’est pas « l’agent a accès au système de fichiers » — c’est « l’agent peut utiliser l’outil Read, et Read a sa propre porte de permission qui vérifie un pipeline de règles avant que quoi que ce soit s’exécute. »
Comment les outils sont enregistrés et distribués
Le modèle décide ce qu’il veut tenter. Le système d’outils décide ce qui est autorisé. Architecturalement séparés.
Chaque appel d’outil passe par une vérification de permission avant l’exécution. Des analyses communautaires approfondies décrivent une fonction centrale qui évalue les règles deny/ask/allow dans cet ordre — deny gagne toujours. Trois résultats possibles : procéder silencieusement, demander à l’utilisateur, ou bloquer.
Un modèle compromis ne peut pas contourner les vérifications de sécurité en étant persuasif. Le harnais ne tient pas compte des arguments du modèle. Les règles sont les règles.
Niveaux de permission
Le modèle de permission de Claude Code a été décrit par plusieurs analystes communautaires comme ayant environ trois niveaux :
Niveau 1 — Auto-approuvé : Actions en lecture seule ou intrinsèquement sûres. Lectures de fichiers, recherche textuelle, navigation dans le code. Ces actions ne changent pas l’état, donc elles s’exécutent sans interruption.
Niveau 2 — Demande de confirmation : Actions qui modifient l’état de manière contrôlée. Modifications de fichiers, certaines commandes shell. En mode automatique (introduit en mars 2026), un classificateur en arrière-plan tournant sur Sonnet 4.6 évalue si ces actions peuvent procéder sans demander. Le classificateur voit la requête de l’utilisateur et l’appel d’outil, mais pas la prose du modèle — un choix de conception délibéré pour empêcher le modèle de se frayer un chemin en douceur jusqu’à la porte.
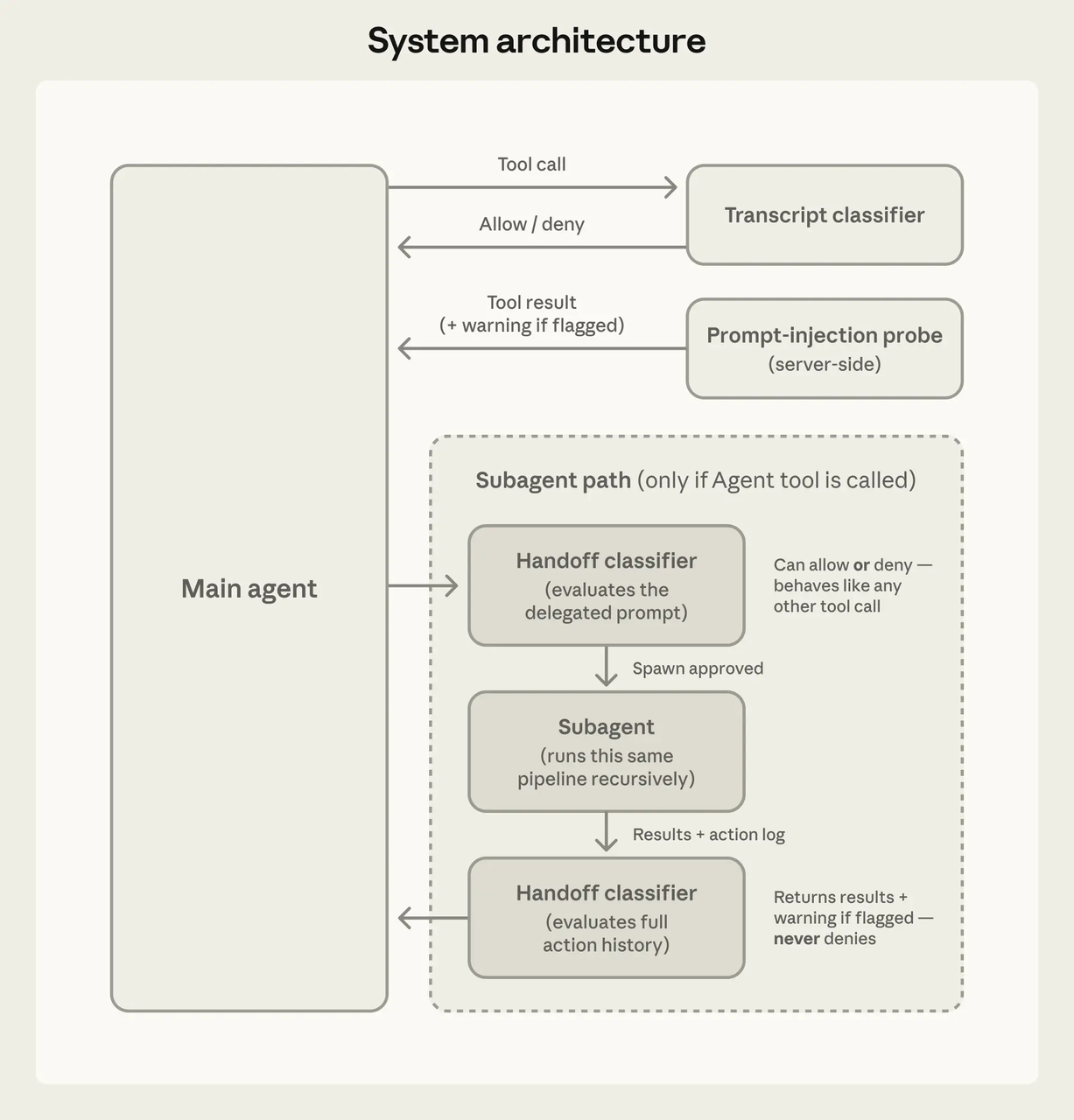 Niveau 3 — Nécessite une approbation explicite ou est bloqué : Opérations à haut risque. Commandes shell pouvant modifier l’état du système de manière imprévisible, opérations en dehors du répertoire de travail, tout ce qui ressemble à une exfiltration de données.
Niveau 3 — Nécessite une approbation explicite ou est bloqué : Opérations à haut risque. Commandes shell pouvant modifier l’état du système de manière imprévisible, opérations en dehors du répertoire de travail, tout ce qui ressemble à une exfiltration de données.
Une mise en garde : le cadre à trois niveaux vient d’analyses communautaires, pas de la documentation officielle d’Anthropic. Le système officiel utilise des règles allow/ask/deny et six modes de permission (default, acceptEdits, plan, auto, dontAsk, bypassPermissions). Les « trois niveaux » constituent un modèle mental utile, mais c’est une simplification.
Gestion des sessions et du contexte
Comment Claude Code suit l’état de session
Claude Code accumule du contexte au cours d’une session — fichiers lus, commandes exécutées, résultats grep, diffs, sortie d’erreurs. Tout s’empile dans un prompt croissant. Contrairement à une interface de chat où chaque message est relativement indépendant, une session Claude Code est une mémoire de travail continue.
Les sessions sont sauvegardées localement. Chaque message, utilisation d’outil et résultat est stocké, ce qui permet le rembobinage, la reprise et le branchement. Avant les modifications de code, le harnais prend un instantané des fichiers affectés pour permettre le retour arrière.
Troncature des sorties et gestion des coûts en tokens
Les sorties d’outils volumineuses posent un vrai problème. Claude Code définit un maximum par défaut de 25 000 tokens pour la sortie des outils MCP, avec un avertissement à 10 000 tokens. Les auteurs de serveurs peuvent annoter leurs outils pour permettre des résultats plus grands (jusqu’à 500 000 caractères), qui sont persistés sur disque plutôt que conservés en contexte.
C’est le genre de chose à laquelle on ne pense pas jusqu’à ce que son agent perde silencieusement la trace d’informations parce qu’un résultat d’outil a été tronqué. Des limites explicites et configurables avec des solutions de secours basées sur le disque — ça vaut la peine d’être repris.
Comportement de compaction
Ça m’a posé problème avant que je comprenne. Lorsque l’utilisation de tokens atteint environ 98 % de la fenêtre de contexte, Claude Code se compacte automatiquement : il résume l’historique antérieur pour libérer de l’espace. Les métadonnées critiques sont préservées. Les images et les PDF sont supprimés.
La partie délicate : la compaction peut perdre des détails importants. La solution pratique : mettre tout ce qui est critique dans CLAUDE.md, que le harnais relit à chaque tour.
La recherche d’Anthropic sur la conception des harnais a révélé que les réinitialisations complètes de contexte — où une nouvelle instance d’agent reprend à partir d’un artefact de transfert — fonctionnent parfois mieux que la compaction pour les sessions prolongées. Plus de complexité d’orchestration, mais une meilleure fidélité du contexte.
Couche d’intégration MCP
Comment Claude Code se connecte aux serveurs MCP
 MCP (Model Context Protocol) est un standard ouvert pour connecter des outils IA à des services externes. Claude Code prend en charge trois modes de transport : HTTP (recommandé pour les serveurs distants), stdio (pour les processus locaux) et SSE.
MCP (Model Context Protocol) est un standard ouvert pour connecter des outils IA à des services externes. Claude Code prend en charge trois modes de transport : HTTP (recommandé pour les serveurs distants), stdio (pour les processus locaux) et SSE.
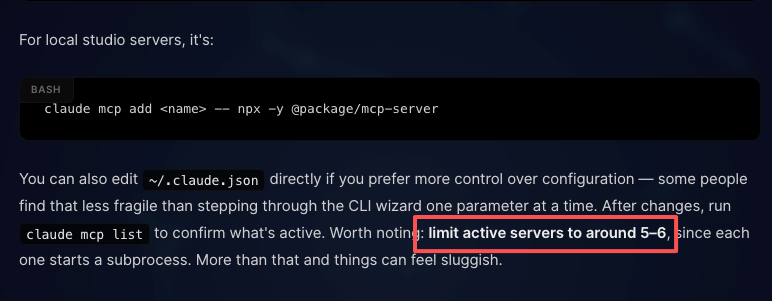
Ajouter un serveur se fait en une commande : claude mcp add server-name --transport http "URL". Après ça, les outils du serveur apparaissent comme des outils appelables dans la session, soumis au même pipeline de permission que les outils intégrés.
Découverte d’outils et flux d’authentification
Un détail qui m’a impressionné : la recherche d’outils. Lorsque vous connectez des serveurs MCP, Claude Code ne charge pas tous leurs schémas d’outils dans le contexte au démarrage. Il ne charge que les noms des outils au début de la session, puis utilise un mécanisme de recherche pour découvrir les outils pertinents lorsqu’une tâche en a réellement besoin. Seuls les outils que Claude utilise entrent dans le contexte.
Cela maintient les frais généraux MCP faibles. Les flux d’authentification dépendent du serveur — OAuth, clés API, en-têtes. Claude Code exige une approbation explicite de l’utilisateur pour les nouveaux serveurs MCP.
Ce qui est prêt pour la production vs. ce qui évolue encore
L’intégration MCP est fonctionnelle et activement utilisée. Mais quelques limites pratiques méritent d’être connues :
Le plafond recommandé est d’environ 5 à 6 serveurs MCP actifs, car chacun démarre un sous-processus. La recherche d’outils aide avec les frais généraux de contexte, mais la latence augmente au-delà de ça.
 Les grandes réponses MCP nécessitent une gestion soigneuse. La limite par défaut de 25K tokens fonctionne pour la plupart des cas d’usage mais devient serrée pour les schémas de bases de données. Le repli de persistance sur disque aide, bien que le modèle n’obtienne qu’une référence plutôt que le résultat complet en contexte.
Les grandes réponses MCP nécessitent une gestion soigneuse. La limite par défaut de 25K tokens fonctionne pour la plupart des cas d’usage mais devient serrée pour les schémas de bases de données. Le repli de persistance sur disque aide, bien que le modèle n’obtienne qu’une référence plutôt que le résultat complet en contexte.
Et les serveurs MCP construits par la communauté varient en qualité. La documentation d’Anthropic note explicitement que les serveurs tiers peuvent être des vecteurs d’injection de prompt. Le système de permissions aide, mais la confiance reste de votre responsabilité.
Leçons pour les développeurs
Ce que cette architecture révèle sur les systèmes agentiques de niveau production
Quelques patterns issus de la conception de Claude Code que je pense généralisables :
Séparez le raisonnement de l’application des permissions. Le modèle décide ce qu’il veut faire. Un système différent décide si c’est autorisé. Un modèle compromis ne peut pas contourner les vérifications de sécurité parce que c’est littéralement un chemin de code différent.
Rendez la gestion du contexte explicite. Compaction, limites de troncature, recherche d’outils, persistance sur disque — ce sont tous des mécanismes pour gérer activement ce que le modèle voit. La plupart des projets d’agents amateurs traitent le contexte comme un sac sans fond. Ce n’en est pas un.
Concevez pour la continuité de session. Instantanés, modifications de fichiers réversibles, CLAUDE.md comme ancre persistante. Les agents à longue durée d’exécution ont besoin d’une mémoire qui survit à la compression du contexte.
La granularité des permissions est payante. Des règles par outil, par pattern, par répertoire avec une évaluation deny-first. Plus de travail qu’un simple drapeau « tout autoriser », mais c’est la différence entre une démo et un système déployable.
Quand construire son propre harnais vs. utiliser une couche gérée
Tâche étroite et bien définie — un bot CI qui exécute des tests et publie des résultats — vous pouvez câbler un harnais minimal vous-même. Quelques outils, une vérification de permission simple, une fenêtre de contexte fixe.
Sessions prolongées, état à travers les réinitialisations de contexte, sortie d’outils non fiable, des dizaines d’outils — construisez sur un harnais existant ou étudiez-en un en détail. Le Claude Agent SDK, l’architecture Codex d’OpenAI, LangGraph ont tous résolu des problèmes que vous rencontrerez tôt ou tard.
La plupart des équipes sous-estiment la complexité du harnais. Je l’ai certainement fait. Le modèle est la partie facile.
FAQ
Qu’est-ce que le harnais d’agent de Claude Code ?
La couche d’infrastructure entre le modèle Claude et le monde réel — distribution des outils, permissions, gestion du contexte, état de session, connexions MCP. Anthropic le décrit comme ce qui « transforme un modèle de langage en un agent de codage capable. »
Comment Claude Code gère-t-il les permissions des outils ?
Un pipeline basé sur des règles évalue chaque appel d’outil : allow, ask, ou deny, avec deny qui gagne toujours. En mode automatique, un classificateur en arrière-plan sur une instance de modèle séparée évalue les cas ambigus — et ne voit délibérément pas la sortie en prose de l’agent pour prévenir l’injection de prompt.
L’intégration MCP de Claude Code est-elle prête pour la production ?
Fonctionnelle et activement utilisée, mais avec des limites pratiques concernant le nombre de serveurs, la taille des réponses et la fiabilité des tiers. Elle évolue rapidement.
Puis-je construire mon propre harnais en utilisant les mêmes patterns ?
Oui. Le Claude Agent SDK expose les mêmes modes de permission, hooks et gestion du contexte. Des projets communautaires comme Everything Claude Code ont également documenté des patterns réutilisables.
Quelle est la différence entre parité de spécification et parité comportementale ?
La parité de spécification signifie prendre en charge les mêmes outils et configurations. La parité comportementale signifie gérer les cas limites de la même manière — la compaction qui supprime une règle critique, un outil qui renvoie 100K tokens, un modèle qui essaie de contourner les permissions. Correspondre à la spécification est simple. Correspondre au comportement prend des mois.
Quelque chose qui m’est resté en tête : le harnais est la partie difficile. Tout le monde suppose que le modèle est l’avantage concurrentiel. Et c’est vrai — jusqu’à ce que vous essayiez de lui faire faire des choses de manière fiable pendant plus de cinq minutes. C’est là que vit l’ingénierie.
Articles précédents :
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué

API GLM-5.2 : Tarification, contexte 1M et routage en production

Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie

API MAI-Image-2.5 : Ce que les développeurs doivent savoir
