Les versions du modèle GPT-5 expliquées : de GPT-5 à GPT-5.4
GPT-5 n'est pas un modèle unique. Ce guide explique chaque version GPT-5.x et ce que les développeurs doivent savoir sur cette famille de modèles en évolution.

Bonjour, je m’appelle Dora. Je n’avais pas prévu d’écrire sur les modèles GPT-5 cette semaine. Je me suis simplement retrouvée bloquée à choisir une version dans le menu déroulant des modèles. Une petite hésitation, puis la question familière : est-ce que la 5.2 m’aide vraiment ici, ou est-ce que je clique sur la version plus récente simplement parce qu’elle est plus récente ?
Disponible sur WaveSpeedAI — tarification transparente par token, endpoint compatible OpenAI. GPT-5.5 API → · GPT-5.4 API → · Ouvrir le Playground →
Cette petite friction m’a entraînée dans un terrier de lapin. J’ai passé quelques soirées fin février et début mars 2026 à relancer les mêmes tâches sur toute la famille 5.x : un résumé de recherche compact, une extraction JSON structurée et un simple refactoring de code multi-fichiers. Rien de spectaculaire. Juste le genre de travail qui soit paraît plus facile, soit ne l’est pas. Ce sont mes notes de terrain, pas un bilan triomphal.

Pourquoi GPT-5 est un système, pas un modèle unique
Je vois souvent des gens parler du modèle GPT-5 « en soi », comme s’il s’agissait d’un cerveau unique que l’on substitue. Ça ne correspond pas à ce que j’ai observé, ni à ce qu’OpenAI laisse entendre dans ses docs et ses interventions publiques.
Vue d’ensemble de l’architecture de routage
Le comportement ressemble à un système routé : une “porte d’entrée” unique qui décide discrètement quel spécialiste interne traite quelle partie de votre requête. On peut l’imaginer comme un contrôleur de trafic avec quelques objectifs en tête : maintenir une latence stable, atteindre un seuil de qualité et éviter de solliciter des spécialistes coûteux sauf si le prompt en a vraiment besoin. C’est pourquoi le même prompt peut sembler légèrement différent entre les paramètres « rapide » et « par défaut », ou entre des versions adjacentes — plus d’un modèle est en jeu.
En pratique, j’ai observé des signaux de cela lorsque :
- L’appel d’outils est capté plus rapidement sur certaines exécutions, comme si un planificateur intervenait plus tôt.
- La fiabilité du mode JSON fait un bond après une mise à jour côté système, même si les paramètres API n’ont pas changé.
- La latence se maintient sous charge mieux que ce que permettrait un seul monolithe.
Je ne peux pas voir derrière le rideau, mais les sorties suggèrent un routeur qui pèse coût, vitesse et type de tâche, puis choisit un chemin. Ce cadre m’aide à comprendre pourquoi deux labels « GPT-5 » peuvent se comporter différemment.
Comment fonctionne le versionnage d’OpenAI
OpenAI publie généralement des familles de modèles avec des versions nommées et des versions « preview » occasionnelles. Avec le temps, une version peut devenir la version par défaut, puis être dépréciée. Les labels peuvent évoluer plus vite que les articles de blog ne peuvent suivre. Quand je doute, je consulte la documentation des modèles OpenAI et le changelog de l’API avant de fixer une version. Il vaut aussi la peine de parcourir la référence API pour les paramètres petits mais importants (schéma de réponse, modes JSON, nuances des appels d’outils) qui changent entre les versions.
Donc quand je dis « GPT-5 », je parle du système routé exposé sous ce nom de famille. Et quand je dis « 5.1 » ou « 5.3 », je parle d’une configuration spécifique de ce système, souvent avec des comportements par défaut différents, des routeurs légèrement différents, et parfois de nouveaux garde-fous en matière de sécurité ou de fiabilité.
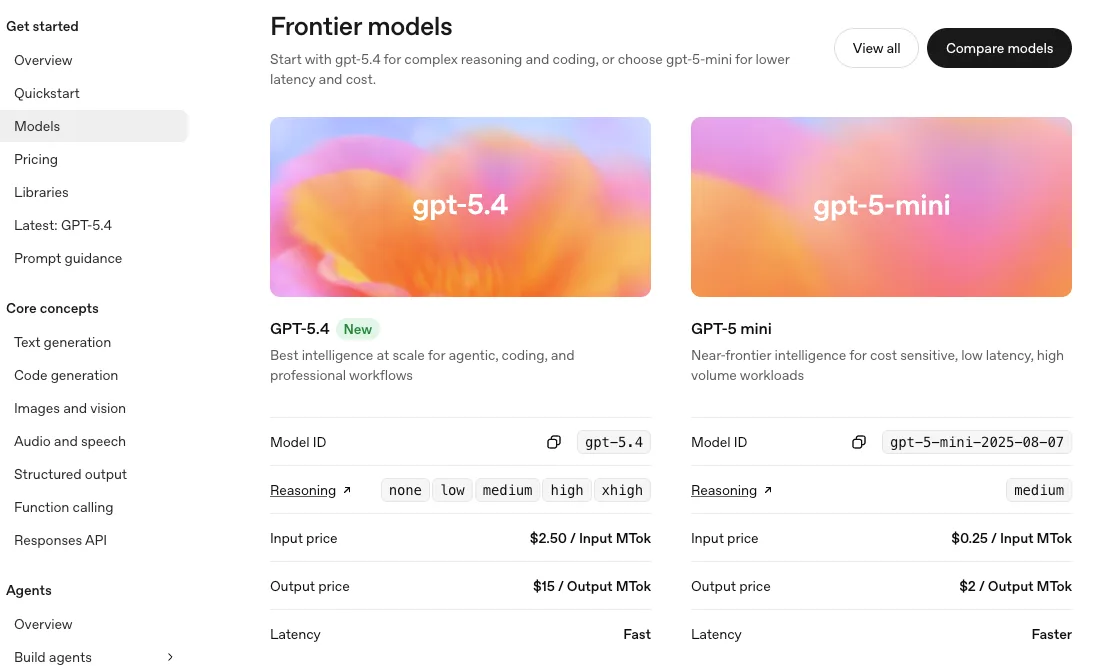
GPT-5 (Base) — Capacités initiales
J’ai d’abord traité le GPT-5 de base comme un généraliste. Non pas parce qu’il était magique, mais parce qu’il gérait trois tâches courantes assez bien avec peu de configuration.
Fonctionnalités principales au lancement
- Clarté du raisonnement : Pour les tâches de planification — « rédige une approche en 3 étapes, puis développe l’étape 1 » — le modèle de base respectait la structure sans que j’aie besoin de trop expliquer. Ce n’était pas spectaculaire. C’était régulier.
- Utilisation des outils sans drama : L’appel de fonctions fonctionnait dès le départ. Lorsque je lui demandais d’extraire des champs structurés, il passait des arguments cohérents et typés la plupart du temps.
- Contexte long sans s’effondrer : J’ai poussé de longs briefs et des références en plusieurs parties. Il restait suffisamment cohérent pour être utile, surtout quand je l’ancrait avec des en-têtes de section.
- Mode JSON et schémas de réponse : Avec un schéma simple, j’obtenais des sorties analysables 8 à 9 fois sur 10 au premier essai. Quand ça échouait, ça échouait de façon évidente (objet tronqué), ce qui est une sorte de miséricorde étrange.
Limitations initiales
- Le déterminisme reste souple : même avec une température basse, des exécutions répétées faisaient légèrement varier les formulations et parfois l’ordre. Pour la production, j’ai dû ajouter un post-traitement léger (tri des clés, normalisation des espaces) pour maintenir des diffs propres.
- Rappel des appels d’outils : si j’enchaînais des outils, le modèle « oubliait » parfois les contraintes limites d’un outil précédent à moins que je ne les reformule. Une petite contrariété, mais bien réelle.
- Pics de latence : la plupart des appels étaient corrects. Puis un ou deux prenaient nettement plus de temps. Pas des minutes, juste assez pour déstabiliser une boucle serrée.
- Conscience des coûts : le modèle de base n’était pas le moins cher, donc les prompts longs imprudents coûtaient cher. J’ai raccourci les messages système et déplacé le code standard vers des modèles de code. Étape simple, économies significatives.
GPT-5.1 à GPT-5.3 — Changements incrémentiels
Ces versions mineures n’ont pas changé le caractère des modèles GPT-5. Elles ont resserré les vis.
Améliorations version par version
- 5.1 : Le suivi des instructions est devenu plus précis. Quand je demandais « points de liste uniquement, sans introduction », il obéissait plus souvent. La conformité JSON a également légèrement progressé.
- 5.2 : Meilleur ancrage dans les citations. Quand je fournissais des passages et demandais des résumés appuyés sur des citations, il s’ancrait plus proprement dans le texte cité. Les hallucinations ont diminué — pas à zéro, mais suffisamment pour que je le remarque.
- 5.3 : Les appels d’outils semblaient plus fiables sous charge. Moins de formes d’arguments étranges. J’ai aussi observé des premiers tokens légèrement plus rapides dans mes logs, bien que cela puisse être dû au routeur effectuant un triage intelligent plutôt qu’au modèle lui-même.
Tout cela s’est manifesté de façon discrète : moins de nouvelles tentatives, moins de nettoyage, moins de guidage dans les prompts.
Différences côté développeur
- Schémas de réponse : les nouvelles versions étaient plus exigeantes dans le bon sens. Quand je déclarais un schéma, elles le suivaient ou échouaient rapidement. Ça m’a fait gagner plus de temps que n’importe quelle amélioration d’« intelligence ».
- Deltas de streaming : le flux de tokens arrivait en morceaux plus stables. Plus facile de construire des interfaces qui ne sautillent pas.
- Tolérance aux signatures d’outils : 5.2 et 5.3 géraient les types stricts sans improviser. Si un champ était un enum, il inventait moins souvent de nouvelles valeurs. Cela a réduit le code de garde-fou.
Ce sont de petites choses, mais elles éliminent les irritants. Si vous maintenez des agents, le petit finit par faire grand sur de nombreux appels.
Ce qui est resté inchangé
- Les réalités du contexte long : alimenter un contexte énorme pénalise toujours la latence et le coût. L’élagage et l’indexation restent gagnants.
- Dérive de style : même avec des exemples, le ton dérivait un peu sur les sorties longues. Je garde des extraits de référence et demande au modèle de les imiter — ça marche mieux que les adjectifs.
- Le « génie en un seul essai » est rare : les meilleurs résultats viennent toujours d’un échafaudage solide, d’objectifs clairs, de petites étapes et de retours. Le modèle s’est amélioré, mais la conception de mon système comptait davantage.
GPT-5.4 — Ce que les fuites suggèrent actuellement
Je n’ai pas accès à la 5.4 au moment où j’écris ces lignes. Je me base sur des indices publics, des conversations de développeurs, quelques références SDK que des gens ont repérées, et la tendance générale d’évolution de ces familles. Considérez cela comme indicatif, pas définitif. Si vous êtes proche d’une fenêtre de lancement, vérifiez la documentation des modèles et les notes de version récentes.
Références au mode rapide
Il y a beaucoup de discussions autour d’un chemin de routage « rapide » ou « turbo » dans la 5.4. Mon hypothèse : un profil privilégiant la latence qui assouplit quelques garde-fous de qualité, similaire dans l’esprit aux niveaux de vitesse vus dans les familles précédentes. Si cela se concrétise, je m’attendrais à :
- Un premier token plus rapide.
- Une variance légèrement plus élevée sur le formatage exact, sauf si vous utilisez des schémas stricts.
- Un meilleur comportement en concurrence pour les interfaces de chat et les agents en direct.
Si vous accordez plus d’importance à la vitesse perçue qu’à une formulation parfaite, cela pourrait devenir le choix par défaut.
Signaux sur le traitement des images
Quelques indices pointent vers une compréhension des images plus solide et un OCR plus robuste sur les entrées difficiles (reflets, reçus inclinés, captures d’écran de code). Je m’attendrais aussi à des réponses plus stables sur les graphiques et tableaux, surtout si vous fournissez un schéma cible. La conséquence pratique : moins de pré-traitement manuel. Aujourd’hui, je recadre ou améliore souvent les images avant de les envoyer. Si la 5.4 peut absorber davantage ce chaos, une étape entière disparaît.
Améliorations du flux de travail de codage
Les discussions ici portent sur la planification et les modifications multi-fichiers. Si c’est vrai, la 5.4 pourrait :
- Proposer des plans d’étapes plus clairs avant de toucher au code.
- Maintenir des signatures de fonctions cohérentes entre les fichiers.
- Réduire les erreurs de décalage et les problèmes de chemins d’import.
Même une petite amélioration de la fiabilité compte. Dans mes tests avec les versions précédentes, 70 à 80 % du « temps perdu » ne relevait pas de la logique — c’était le nettoyage de modifications confiantes mais légèrement incorrectes. Si la 5.4 réduit cela de 10 à 15 %, cela donnera l’impression d’une version plus qu’incrémentielle.

Comment les développeurs choisissent entre les versions GPT-5.x
Je ne choisis pas une version parce qu’un article de blog me l’a dit. Je fais de petits tests ennuyeux. Voici le cadre qui a tenu pour moi.
Cartographie des cas d’utilisation
- Rédaction de contenu avec contrôle du ton : je penche vers les versions plus récentes (5.2/5.3) parce que l’adhérence au style s’est légèrement améliorée. Je maintiens une petite bibliothèque d’exemples de ton et je les référence.
- Extraction structurée : la version qui me donne la meilleure adhérence au schéma gagne. Dernièrement, c’était la 5.2 ou la 5.3 avec des schémas de réponse explicites. J’ajoute quand même un validateur et une nouvelle tentative.
- Agents et flux de travail d’outils : la 5.3 a été la plus stable sur les arguments de fonctions. Si le mode rapide de la 5.4 est réel, je le testerai en A/B pour les agents en direct qui ont besoin de va-et-vient rapides plutôt que de prose parfaite.
- Assistance au code : je commence avec un contexte court et demande d’abord un plan. Si le modèle ne peut pas écrire un plan crédible, il n’écrira pas de diffs propres. Les versions 5.x adjacentes diffèrent juste assez ici pour que ça compte — testez sur votre dépôt, pas sur un fichier jouet.
Je suis trois chiffres pour chaque cas d’utilisation : taux de réussite au premier passage, latence moyenne et pourcentage d’appels nécessitant une correction humaine. Si une version plus récente ne fait pas bouger au moins l’un d’eux dans la bonne direction, je ne bascule pas.
Compromis coût vs capacité
Les tarifs OpenAI évoluent, et je ne devinerai pas de chiffres ici. La tendance, cependant, est stable :
- Les modèles plus récents ne sont pas toujours plus chers, mais ils peuvent l’être. Je budgétise par tokens, pas par intuition.
- Les prompts longs multiplient les coûts. J’élimine le standard, compresse les exemples et référence des IDs externes quand c’est possible.
- Si vous traitez en lot (résumés, extractions), la version fiable la moins chère gagne généralement. Si vous êtes en contact avec des utilisateurs, la vitesse perçue compte souvent plus que le coût brut.
Deux conseils pratiques qui m’ont fait économiser temps et argent :
- Ensembles dorés : gardez 20 à 50 vrais prompts avec des sorties connues comme bonnes. Relancez-les quand vous envisagez un changement. Pas de mémoire, juste des comparaisons propres. Vous verrez les compromis rapidement.
- Garde-fous dans le code, pas dans la prose : les schémas, validateurs et petits post-processeurs l’emportent sur des paragraphes d’instructions.
Politique de mise à jour de la page (maintenue en continu)
Je mets cette page à jour quand je vois des changements significatifs dans les modèles GPT-5, généralement après avoir relancé mon ensemble de tests ou quand les docs d’OpenAI changent. J’ajoute une courte note avec une date, ce que j’ai testé et ce qui a bougé (le cas échéant). Je renvoie aux sources officielles quand je le peux et signale les incertitudes quand je ne peux pas vérifier quelque chose.
Si vous faites face à des contraintes similaires, ça vaut la peine d’y jeter un œil de temps en temps — mais n’attendez pas après moi. La documentation des modèles est la source de vérité. Je maintiens mes notes de façon stable, pas exhaustive.
Une petite observation pour finir : plus je traite « GPT-5 » comme un système vivant plutôt que comme un simple interrupteur, plus mes décisions deviennent sereines. Le menu déroulant cesse d’avoir l’air d’un test. C’est juste un bouton que je tourne avec une raison.
Articles associés
Présentation de ByteDance Seedance 2.0 Mini sur WaveSpeedAI

Claude Fable 5 et le basculement vers Opus 4.8 expliqué
API GLM-5.2 : Tarification, contexte 1M et routage en production
Prix de GPT-5.4 Mini : coûts d'entrée, mis en cache et de sortie
API MAI-Image-2.5 : Ce que les développeurs doivent savoir