Fuite de GPT-5.4 : Ce que les développeurs doivent savoir
GPT-5.4 est apparu brièvement dans les dépôts OpenAI Codex avant d'être supprimé. Voici ce que les signaux de cette fuite pourraient signifier pour les développeurs.

Bonjour, je suis Dora. Je ne cherchais pas un nouveau modèle. Je nettoyais simplement un pipeline de build quand j’ai vu un fil de discussion circuler avec des captures d’écran d’un commit mentionnant « GPT 5.4 ». Pas de fanfare, juste une petite ligne dans une pull request. Je me suis arrêtée, non pas parce que j’avais besoin d’un autre acronyme dans ma journée, mais parce que les indices discrets et accidentels en disent souvent plus que les lancements tape-à-l’œil.
Disponible sur WaveSpeedAI — tarification transparente par token, endpoint compatible OpenAI. GPT-5.4 API → · GPT-5.5 API → · Ouvrir le Playground →
Au cours de la première semaine de mars 2026, j’ai suivi les miettes de pain : des diffs mis en cache, des discussions entre développeurs, et une PR qui semblait apparaître et disparaître. Je n’ai pas testé GPT 5.4 (il n’y a rien d’officiel à tester), mais j’ai examiné attentivement ce que le code semblait référencer et comment il était géré. Le ton de la piste importait presque autant que le contenu.
Comment GPT-5.4 a fait surface dans la nature
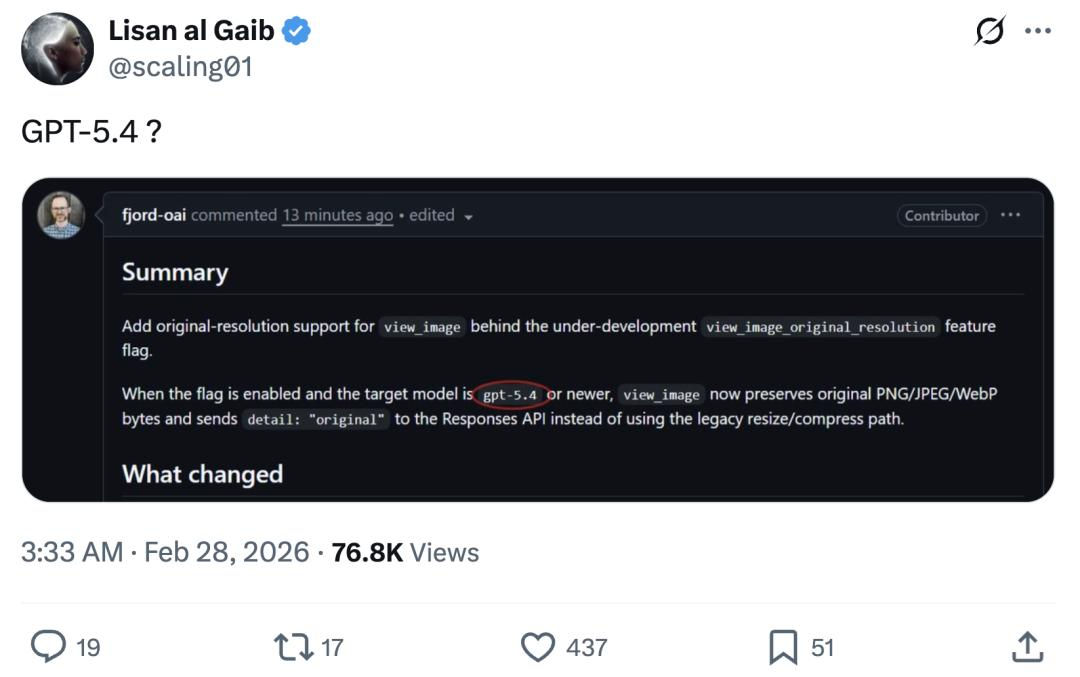
Les références dans la PR Codex
J’ai d’abord remarqué des mentions de GPT 5.4 liées à une modification éphémère dans un dépôt qui semblait toucher des contextes « Codex », soit un nommage hérité, soit un chemin interne qui utilise encore « codex » comme bucket pour les flux de codage. L’extrait qui circulait montrait quelques éléments auxquels on s’attendrait autour du routage de modèles et des feature flags, rien qui criait « lancement », plutôt de la plomberie. Si vous avez travaillé autour de changements de modèles, vous savez que ces lignes sont généralement ennuyeuses et importantes.
Deux choses ressortaient dans ces extraits : une référence à un switch « /fast » dans une couche de commandes de chat ou d’agent, et un label de capacité qui ressemblait à une vision en pleine résolution. Je suis précise ici parce que ça compte. Les labels ne correspondent pas toujours à la réalité, mais ils sont rarement aléatoires.
Pourquoi le code a été rapidement supprimé
Le commit n’a pas duré. D’après ce que j’ai vu, la branche a été réécrite et le diff de la PR a été nettoyé. C’est courant quand une équipe arrive trop tôt sur une référence ou mélange par erreur des configurations internes et externes. En d’autres termes : ça ressemblait à une maintenance de routine sous pression, pas à un retrait.
J’ai fait la même chose sur des équipes plus petites — attraper un flag que je n’aurais pas dû exposer, force-pousser, et passer à autre chose. La rapidité de la correction suggérait que quelqu’un en amont avait remarqué les discussions et décidé de fermer la boucle. Pas un scandale. Juste du contrôle des dégâts.
Ce que les suppressions par force-push signalent généralement
Un force-push ne prouve rien de fascinant. Il signale généralement l’urgence et le désir de restaurer le dépôt dans un état connu. Vous pouvez lire la position même de Git sur la réécriture de l’historique dans la documentation — outil utile et tranchant, facile de se couper si on n’est pas prudent. Si vous voyez un force-push au milieu d’une fuite, cela signifie souvent que l’équipe traite la fuite comme du bruit plutôt que comme une révélation coordonnée.
Pour contexte (pas comme preuve), voici une référence neutre : les notes de Git sur le force-pushing et la réécriture de l’historique. Un univers différent, le même schéma.
Ce que le code fuité montre réellement
La commande Fast mode (/fast)
La ligne qui mentionnait une commande « /fast » ressemblait, à mes yeux, à un override au niveau utilisateur ou agent. En termes pratiques, elle suggère un mode qui échange une partie de la profondeur contre la vitesse — un réglage familier dans les routeurs de modèles. Si cela est lié à GPT 5.4, je m’attendrais à des premiers tokens plus rapides, peut-être une mise en cache plus agressive, peut-être des seuils d’appels d’outils plus souples. Rien de flashy, mais utile quand on est dans une boucle qui exécute des dizaines de petites vérifications.
Ça ne ressemblait pas à une fonctionnalité pour impressionner lors d’une démo. Ça ressemblait à quelque chose qu’on activerait pendant des déploiements ou des étapes CI quand la latence compte plus que l’éloquence — par exemple, la normalisation des doc strings, les petits refactors, ou les diffs de schémas qui n’ont pas besoin d’une prose parfaite.
La référence à la vision en pleine résolution
« Full-res vision » est une expression chargée de sens. En pratique, cela pourrait signifier des limites d’entrée plus élevées, une meilleure gestion des captures d’écran d’interfaces denses, ou un downscaling moins agressif avant que le modèle ne voie les pixels. Si c’est exact, ça penche vers des workflows où la fidélité compte — lire du vrai code dans des captures d’écran, examiner des états d’interface, ou extraire une structure de diagrammes sans en brouiller les détails.
Je travaille avec beaucoup de notes produit entassées dans des images — des maquettes avec de petites annotations, des redlines, ce genre de choses. Si GPT 5.4 gère celles-ci nativement à plus haute résolution, ça supprimerait une taxe discrète mais constante : l’étape de préparation où je recadre ou ré-encode des images pour qu’un modèle voie ce que je vois.
Les signaux d’agent de codage dans le contexte Codex
Les références à Codex ressemblaient à de l’échafaudage pour des agents de codage. Pas de la magie « écris-moi une appli », plutôt les petits muscles : la sélection d’outils, les appels de fonctions, les politiques de retry, et les fallbacks quand un appel renvoie quelque chose d’inattendu. Les indices que j’ai vus pointaient vers cette couche, pas vers le titre accrocheur.
Si cette lecture est correcte, GPT 5.4 pourrait être optimisé pour des flux de codage agentiques qui survivent au chaos des vrais dépôts : des tests partiels, des environnements instables, des gestionnaires de dépendances mixtes. Moins « génie du code », plus « collègue fiable qui ne lâche pas après la deuxième erreur ». Je peux travailler avec ça.
Pour quoi GPT-5.4 est probablement conçu
Les workflows de codage IA
Je ne pense pas que GPT 5.4 cherche la nouveauté. La piste suggère des mains plus stables sur les boucles courantes : lire du code, faire de petites modifications, valider, et recommencer sans drame. Si vous livrez des fonctionnalités dans des contraintes réelles, ce rythme compte plus qu’un coup de génie ponctuel.
Une hypothèse, ancrée dans ce que j’ai vu et ce qui revient constamment dans les équipes avec lesquelles je travaille : GPT 5.4 est probablement destiné à se rapprocher du code, pas des diapositives de présentation. Il vise probablement des diffs raisonnablement rapides, des mises à jour de documentation cohérentes, des refactors plus sûrs, et des suggestions pragmatiques qui survivent à l’étape d’exécution.
L’optimisation des boucles d’agents
Les boucles d’agents sont fragiles pour des raisons ennuyeuses — timeouts, erreurs d’outils, dérive du contexte, et tentatives qui ne convergent jamais. L’indice « /fast » ressemble à un moyen de garder les boucles vives, tandis que la référence à la vision suggère que l’agent peut lire ce que les humains font circuler (captures d’écran, logs, photos de terminal) sans tracas supplémentaire.
Si c’est vrai, deux gains de qualité de vie pourraient apparaître :
- Moins de retries manuels : une meilleure classification des erreurs et une logique de back off plus calme réduisent les oscillations.
- Des appels d’outils plus précis : des sauts moins coûteux et plus rapides quand une étape n’a pas besoin d’un raisonnement complet.
Ça ne m’a pas fait gagner du temps au départ — suivre une fuite ne le fait jamais — mais la forme de tout ça donnait l’impression d’un effort mental réduit pour les équipes qui automatisent les parties fastidieuses de la maintenance du code.
Les intégrations d’outils pour développeurs
La façon dont les références étaient nichées dans des indices de routage me dit que GPT 5.4 pourrait être empaqueté pour s’insérer dans les stacks de développement existantes. Par exemple :
- Des hooks CI/CD qui choisissent la vitesse ou la profondeur par étape.
- Des extensions d’éditeur qui peuvent lire des images à plus haute fidélité sans prétraitement externe.
- Des frameworks d’agents qui s’appuient moins sur du code glue artisanal.
Si c’est là où GPT 5.4 se dirige, la valeur ne sera pas dans une démo : elle sera dans moins d’adaptateurs fragiles. C’est le genre de mise à niveau que vous remarquez trois semaines plus tard quand rien ne casse, et que vous réalisez que vous n’avez pas eu à surveiller l’agent un vendredi.

Ce qu’on ne sait toujours pas
Aucun benchmark confirmé
Je n’ai pas vu de benchmarks crédibles liés à GPT 5.4. Pas de feuilles d’évaluation, pas de tâches standardisées, pas de comparaisons tête-à-tête avec les modèles actuels. Sans chiffres, tout ce qu’on a ce sont des impressions et des labels. Si et quand ça arrive, je chercherai d’abord des tests petits et pratiques : le temps de résolution d’un test qui échoue, la précision sur la lecture de captures d’écran denses, ou le nombre de retries par problème résolu.
Aucun détail de prix ou d’API
Il n’y a rien de public sur les prix ou les quotas. Pour la planification, ça compte plus que le battage médiatique. Un excellent modèle difficile à budgétiser n’arrive pas en production. Si vous cartographiez des scénarios aujourd’hui, gardez des espaces réservés dans vos feuilles de calcul et faites une vérification de cohérence par rapport à la documentation des modèles OpenAI actuelle plutôt qu’aux labels fuités.
Calendrier de sortie incertain
Je n’ai pas de date, de trimestre, ni même de saison. La suppression rapide suggère un mouvement interne, pas un timing de marché. Si GPT 5.4 apparaît, il pourrait se manifester discrètement dans des tables de routage ou comme un flag dans des frameworks d’agents avant toute grande bannière. Ou il pourrait changer de nom et ne jamais être appelé « GPT 5.4 » en public.
Statut actuel et avertissement (modèle non officiellement publié)
Début mars 2026, GPT 5.4 n’a pas été annoncé ni documenté. Je partage des observations tirées de références de code éphémères et de la façon dont elles ont été gérées, rien de plus. Ce n’est pas un conseil pour refondre quoi que ce soit. Si vous êtes curieux, gardez un œil sur la documentation stable, pas sur les captures d’écran. Et si vous repérez une autre référence égarée, prenez une pause. La plupart des fuites sont plus discrètes, et plus utiles, que les gros titres ne le suggèrent.
Je m’arrêterai là : ce qui m’a accrochée n’était pas le numéro de version. C’étaient les petits signes de soin autour des boucles et de la latence. Si c’est là que les choses se dirigent, je me fais une raison avec moins de spectacle.
Articles associés

Claude Fable 5 vient de sortir : 80,3 % sur SWE-Bench Pro, prix 2× Opus 4.8, gratuit jusqu'au 22 juin

Comment choisir une API de médias IA pour les applications Codex (2026)

API Hunyuan 3D : Ce que les développeurs doivent savoir

Hunyuan 3D vs Hyper3D vs Pixal3D

Créer des applications vidéo IA avec des agents de codage
