Gemini 3.1 Flash-Lite : Fonctionnalités, Cas d'Usage et Comparaison avec Flash
Gemini 3.1 Flash-Lite est le modèle d'inférence le moins coûteux de Google. Fonctionnalités, cas d'usage réels et comparaison directe avec Gemini Flash.

J’ai remarqué quelque chose d’étrange quand Google a sorti Gemini 3.1 Flash-Lite le 3 mars. Habituellement, ils lancent d’abord le modèle Flash plus puissant — ou sautent complètement le palier Lite. Cette fois, ils sont allés directement à l’option économique. Ce changement a retenu mon attention.
Disponible sur WaveSpeedAI — tarification transparente par token, endpoint compatible OpenAI. Gemini 2.5 Pro API → · Gemini 2.5 Flash Lite API → · Ouvrir le Playground →
Je suis Dora. Je l’ai testé pendant la dernière journée, et ce qui m’a surprise n’était pas seulement la vitesse. C’était la façon dont la structure tarifaire rendait soudainement certains workflows… abordables d’une manière qui ne l’était pas avant.

Qu’est-ce que Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite se situe en bas de la nouvelle gamme de modèles de Google, mais « bas » ne signifie plus ce que ça voulait dire. Selon la documentation officielle de Google, c’est leur modèle Gemini le plus rentable, optimisé pour les cas d’usage à faible latence et à fort trafic. Il vise à égaler les performances de Gemini 2.5 Flash dans les domaines de capacités clés, tout en étant nettement plus rapide et moins cher.
Sa place dans la gamme Gemini 3.1
La famille Gemini 3 compte désormais trois niveaux distincts. Au sommet, il y a Gemini 3.1 Pro — le poids lourd pour les tâches de raisonnement complexes. Au milieu se trouve Gemini 3 Flash, qui combine l’intelligence de niveau Pro avec la rapidité de Flash. Et désormais, Flash-Lite occupe le créneau à fort volume et sensible aux coûts.
Ce qui rend cela intéressant, c’est que Flash-Lite n’est pas une version allégée de Flash. Il est en réalité basé sur l’architecture de Gemini 3 Pro, puis optimisé spécifiquement pour le débit et la latence. Ce choix architectural se reflète dans les benchmarks — ce n’est pas seulement plus rapide, c’est plus intelligent qu’on ne s’y attendrait pour ce prix.
Comment fonctionne la logique des niveaux Pro / Flash / Flash-Lite
L’approche à plusieurs niveaux ne concerne pas les fonctionnalités — il s’agit d’allocation de ressources de calcul. Pro dépense plus de tokens pour réfléchir à des problèmes complexes. Flash équilibre le raisonnement et la vitesse. Flash-Lite minimise le raisonnement interne par défaut, mais vous pouvez l’ajuster.
Cette dernière partie est nouvelle. Google a ajouté ce qu’ils appellent des « niveaux de réflexion » — minimal, faible, moyen ou élevé. Pour une simple tâche de traduction, vous le réglez au minimum et obtenez des résultats instantanés. Pour quelque chose nécessitant plus de précision, vous l’augmentez et acceptez une latence et un coût légèrement plus élevés.
J’ai essayé cela avec un lot de tickets de support client. Avec une réflexion minimale, les réponses arrivaient en moins de deux secondes. Au niveau moyen, cela prenait cinq secondes mais captait des nuances que le passage rapide avait manquées. Le contrôle semble pratique.
Fonctionnalités clés de Gemini 3.1 Flash-Lite
Coût d’inférence ultra-faible
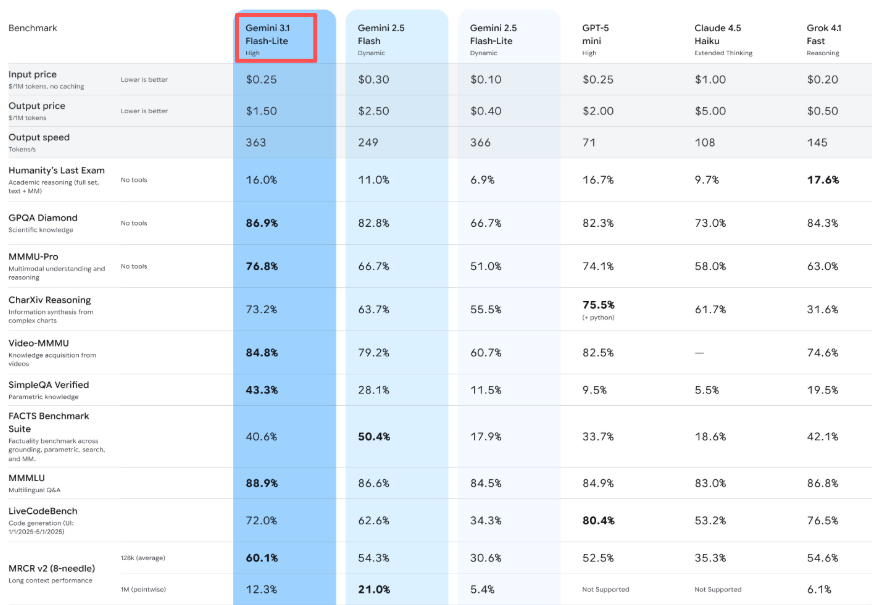
Le tarif est de 0,25 $ par million de tokens en entrée et de 1,50 $ par million de tokens en sortie. Pour mettre cela en perspective : Gemini 3.1 Pro commence à 2,00 $ par million de tokens en entrée et 18 $ par million de tokens en sortie pour les charges de travail exigeantes. Flash-Lite coûte environ un huitième du prix de Pro pour les tâches basiques.
Mais voici ce qui m’a surprise — il est aussi moins cher que Gemini 2.5 Flash (qui était à 0,30 $/2,50 $), malgré des capacités supérieures. C’est inhabituel. En général, on paie plus pour les améliorations.
Débit élevé et faible latence
Google affirme que Flash-Lite génère des sorties à 363 tokens par seconde, et dans mes tests, cela semble exact. Plus important encore, le temps jusqu’au premier token — le moment où vous arrêtez d’attendre et commencez à voir la sortie — est 2,5 fois plus rapide que Gemini 2.5 Flash, selon leurs benchmarks internes.
Je l’ai remarqué surtout lors de la construction d’un simple pipeline de modération de contenu. La différence entre une attente de trois secondes et une attente d’une seconde ne semble pas grande. Mais quand vous traitez des centaines d’éléments, ce délai s’accumule. Avec Flash-Lite, le pipeline se sentait réactif plutôt que lent.
Support d’entrées multimodales
Flash-Lite gère le texte, les images, l’audio et la vidéo. La fenêtre de contexte va jusqu’à 1 million de tokens, et il peut générer jusqu’à 64 000 tokens de texte en sortie.
Je l’ai testé avec un mélange d’images de produits et de descriptions pour un prototype e-commerce. Il les a étiquetés de manière cohérente et rapide — les premiers utilisateurs comme Whering ont rapporté une cohérence de 100 % dans l’étiquetage des articles pour des catégories de mode complexes. Ce type de fiabilité est important quand vous construisez des systèmes qui ne peuvent pas se permettre de dériver.
Grande fenêtre de contexte
La fenêtre de contexte d’un million de tokens signifie que vous pouvez lui fournir des documents entiers, de longs fils de conversation ou de grands ensembles de données sans les découper en morceaux plus petits au préalable. Je n’utilise pas souvent la fenêtre complète, mais quand je le fais — comme lors de l’analyse de PDF multi-pages — c’est la différence entre un workflow fluide et un workflow frustrant.
Gemini 3.1 Flash-Lite vs Flash : Comparaison directe
Quand utiliser Flash-Lite
Utilisez Flash-Lite quand vous exécutez des milliers ou des millions de tâches similaires. Pipelines de traduction, files de modération de contenu, analyse de sentiment à grande échelle, extraction de données basique — tout ce où la tâche est bien définie et où le coût par token compte plus que le raisonnement approfondi.
J’ai également trouvé qu’il fonctionne bien comme routeur. Vous pouvez utiliser Flash-Lite pour classer les requêtes entrantes comme « simples » ou « complexes », puis router les complexes vers Flash ou Pro. Cela économise de l’argent sans sacrifier la qualité là où ça compte.
Quand utiliser Flash à la place
Si la tâche nécessite un raisonnement en plusieurs étapes, une résolution créative de problèmes, ou la gestion d’instructions ambiguës, Flash est le meilleur choix. Il est deux fois plus cher, mais aussi plus intelligent — surtout pour les tâches de codage, où il égale ou dépasse Pro sur certains benchmarks.
J’ai testé les deux sur une tâche qui impliquait de générer des composants d’interface utilisateur à partir de prompts en langage naturel. Flash-Lite pouvait gérer les requêtes simples (« créer un formulaire de connexion »), mais avait du mal avec les vagues (« concevoir quelque chose de moderne et épuré »). Flash gérait les deux.
Cas d’usage de Gemini 3.1 Flash-Lite
Routage d’agents IA et classification de tâches
L’un des cas d’usage les plus propres que j’ai vus est d’utiliser Flash-Lite comme contrôleur de trafic. Quand un utilisateur soumet une requête, Flash-Lite la lit, détermine sa complexité et la route vers le modèle approprié — Flash pour les tâches moyennes, Pro pour les difficiles.
Ce pattern est déjà utilisé dans des outils en production. La CLI Gemini open-source utilise Flash-Lite exactement pour cela, et ça fonctionne parce que le modèle est suffisamment rapide et bon marché pour ajouter cette étape de routage sans augmenter sensiblement la latence ou le coût.
Chat à fort volume et automatisation du support
Le support client est là où les économies de coûts se manifestent vraiment. Si vous gérez des dizaines de milliers de tickets de support quotidiennement, la différence entre 0,25 $ et 2,00 $ par million de tokens en entrée s’amplifie rapidement.
Flash-Lite peut gérer les questions simples, extraire les intentions et router les tickets nécessitant une attention humaine. Il ne va pas résoudre des problèmes techniques complexes, mais il n’en a pas besoin. Il doit juste être fiable et rapide.
Modération et étiquetage de contenu
J’ai construit un pipeline de test rapide pour modérer le contenu généré par les utilisateurs — signaler le spam, le langage inapproprié et les publications hors sujet. Flash-Lite a traité environ 500 éléments en moins d’une minute, avec une précision constante.
L’élément clé ici est la cohérence. Certains modèles dérivent avec le temps ou donnent des réponses différentes à des entrées similaires. Flash-Lite est resté prévisible sur plusieurs exécutions répétées, ce qui compte quand vous construisez des systèmes qui doivent se comporter de la même manière à chaque fois.
Pipelines de prétraitement de documents
Flash-Lite excelle dans l’extraction de données structurées. Étant donné un lot de factures ou de reçus, il peut extraire les champs clés — dates, montants, noms de fournisseurs — et les produire en JSON.
J’ai testé cela avec un mélange de factures PDF, et il en a géré la plupart correctement. Celles avec lesquelles il avait du mal étaient des scans de mauvaise qualité avec un texte médiocre, mais c’est une limitation de l’entrée, pas du modèle.
Ce que Flash-Lite signifie pour la conception d’infrastructure IA

Le pattern d’architecture de modèles à plusieurs niveaux
La sortie de Flash-Lite complète ce qui commence à ressembler à un pattern standard de l’industrie : une pile de modèles à trois niveaux. Vous avez un poids lourd pour les problèmes difficiles, une option équilibrée pour l’usage quotidien, et un modèle léger pour les travaux répétitifs à fort volume.
Ce n’est pas nouveau — OpenAI a GPT-5 / GPT-5 mini, Anthropic a Claude Opus / Sonnet / Haiku — mais l’implémentation de Google est intéressante parce que les écarts de prix sont plus importants. Flash-Lite est vraiment bon marché comparé à Pro, ce qui rend certains workflows économiquement viables qui ne l’étaient pas avant.
Routeur bon marché + raisonneur puissant — pourquoi c’est important
Le pattern que je vois sans cesse est le suivant : utiliser un modèle bon marché pour décider à quel type de tâche vous avez affaire, puis router vers un modèle plus cher uniquement quand nécessaire. Il ne s’agit pas seulement d’économiser de l’argent. Cela améliore aussi la latence pour les tâches simples, car vous n’attendez pas qu’un modèle lourd se charge.
J’ai essayé cela avec un lot mixte de 100 tâches — moitié simples, moitié complexes. En utilisant Flash-Lite comme routeur, les tâches simples se terminaient en quelques secondes, et les complexes étaient routées vers Flash. Le coût total était environ 40 % inférieur à celui d’exécuter tout via Flash, sans perte de qualité sur les tâches complexes.
Cette architecture ne fonctionne que si le routeur est suffisamment rapide et bon marché pour ne pas devenir le goulot d’étranglement. Flash-Lite l’est.
Disponibilité actuelle et statut de l’API
Gemini 3.1 Flash-Lite est disponible dès maintenant en aperçu via l’API Gemini dans Google AI Studio et Vertex AI. Il n’est pas dans l’application Gemini grand public — c’est destiné aux développeurs.
Les modèles en aperçu peuvent changer avant de devenir stables, et ils ont des limites de débit plus strictes. En pratique, je n’ai pas atteint ces limites lors des tests normaux, mais si vous planifiez un déploiement en production à grande échelle, c’est quelque chose à surveiller.
Le modèle est également activement mis à jour. Les notes de version de Google montrent des améliorations continues du suivi des instructions, de la qualité de l’entrée audio et des capacités de raisonnement. Nous en sommes encore aux débuts — il s’améliorera probablement au cours des prochains mois.
Une pensée persistante
Ce à quoi je reviens sans cesse n’est pas la vitesse ni le coût. C’est le fait que Flash-Lite donne à certains workflows un sentiment moins expérimental et plus utilitaire. Quand le coût baisse suffisamment, on arrête de se demander « devrais-je utiliser l’IA pour ça ? » et on commence à se demander « comment est-ce que je construis ça pour que ça passe à l’échelle ? »
Ce changement — de la nouveauté à l’infrastructure — c’est là que les outils commencent à s’installer durablement.
Articles associés

Claude Fable 5 vient de sortir : 80,3 % sur SWE-Bench Pro, prix 2× Opus 4.8, gratuit jusqu'au 22 juin

Comment choisir une API de médias IA pour les applications Codex (2026)

API Hunyuan 3D : Ce que les développeurs doivent savoir

Hunyuan 3D vs Hyper3D vs Pixal3D

Créer des applications vidéo IA avec des agents de codage
