Disponibilidad de la API de GPT-5.5: Lo que los equipos deben planificar
GPT-5.5 ha sido anunciado, pero el acceso a la API aún no está completamente disponible. Esto es lo que los equipos pueden planificar ahora y lo que todavía necesita verificación.

El viernes pasado redireccioé un flujo de trabajo de Codex a GPT-5.5 y luego pasé el lunes explicándole a dos clientes por qué la decisión de implementación es más complicada de lo que sugieren los titulares del lanzamiento. Mi nombre aparece en muchos documentos de “¿deberíamos migrar?” en WaveSpeedAI, así que soy Dora — la persona que hace que los equipos esperen dos semanas antes de aprobar un cambio de modelo. La API está activa. Esa es la parte que la mayoría de la cobertura acierta y donde se detiene. Lo que quiero escribir es sobre los diez días después del lanzamiento, cuando “disponible” se convierte en “realmente integrado,” y dónde la mayoría de los equipos con los que trabajo están tropezando.
Esto es una nota de planificación, no un tutorial. Si viniste buscando ejemplos de curl, la documentación oficial los maneja mejor de lo que yo lo haría.
Dónde Está Disponible GPT-5.5 Hoy
Estado del lanzamiento en ChatGPT y Codex
GPT-5.5 se lanzó el 23 de abril de 2026 para usuarios de Plus, Pro, Business y Enterprise dentro de ChatGPT y Codex, con GPT-5.5 Pro restringido a los niveles Pro, Business y Enterprise. En Codex específicamente, el modelo viene con una ventana de contexto de 400K y un modo Rápido que funciona 1.5x más rápido a 2.5x el costo — detalles que el anuncio oficial de lanzamiento de GPT-5.5 en OpenAI describe claramente. El lanzamiento cubrió solo las superficies de consumidor el primer día. Quiero señalar esto porque la mitad de los tickets que vi la semana pasada asumían paridad de API desde el principio.
Lo que OpenAI dice sobre la disponibilidad de la API
La parte que el ciclo de prensa inicial pasó por alto: el acceso a la API llegó un día después, el 24 de abril de 2026. Tanto gpt-5.5 como gpt-5.5-pro están ahora expuestos en las APIs de Responses y Chat Completions, confirmado en la documentación oficial del modelo GPT-5.5 de OpenAI. La ventana de contexto es de 1M tokens en la superficie de la API, distinta del límite de 400K de Codex. Dos superficies, dos límites — fácil de confundir, y vale la pena escribirlo antes de que lo hagan tus ingenieros. Así que la pregunta ya no es “¿cuándo puede usarlo mi equipo?” Sino “¿deberíamos hacerlo, y qué verificamos primero?”
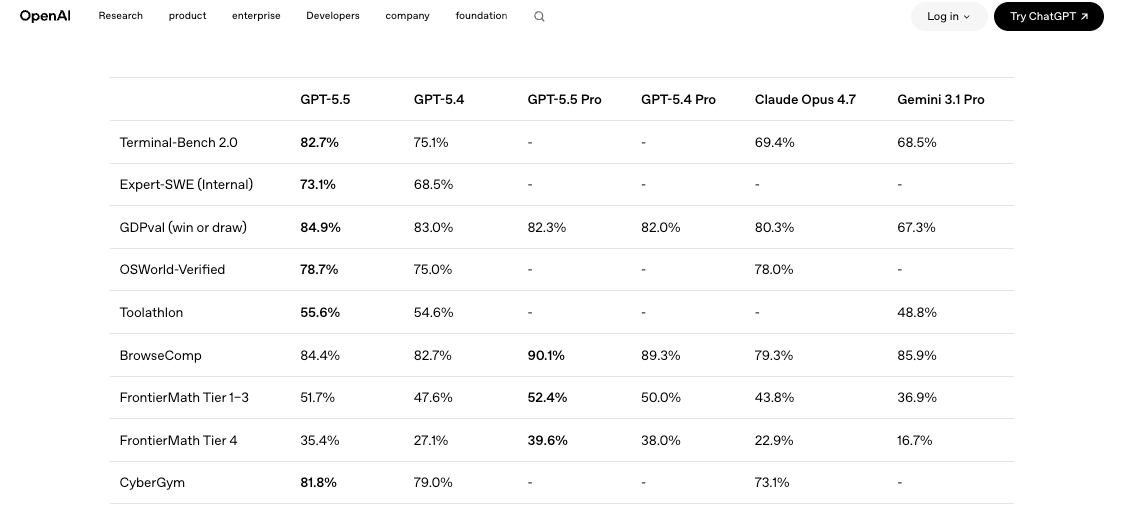
Qué Pueden Planificar los Equipos con Seguridad Antes de la Integración de la API
Criterios de evaluación y preparación para la migración
No recomiendo una migración el mismo día. Esto es lo que bloquearía primero.
Construye un pequeño arnés de evaluación contra tu modelo actual. Cinco a diez prompts representativos de tu carga de trabajo real, puntuados en las dimensiones que realmente te importan: corrección, costo de tokens, latencia, tasa de reintentos. Ejecuta GPT-5.4 y GPT-5.5 en paralelo, los mismos prompts, la misma configuración de temperatura, las mismas definiciones de herramientas. Los benchmarks independientes como la comparación publicada en LLM Stats muestran que GPT-5.5 gana en 9 de 10 benchmarks compartidos pero obtiene victorias solo marginales en SWE-Bench Pro. Traducción: la actualización es real, pero no es uniformemente mejor. Tu carga de trabajo decide.
Decide tu ruta de respaldo ahora, no después del primer 429. Los nuevos lanzamientos de modelos históricamente se publican con límites de velocidad más estrictos durante los primeros 30 días. Ten GPT-5.4 configurado como respaldo antes de redirigir una sola solicitud de producción. He visto dos equipos saltarse este paso en el pasado y pagarlo durante un pico de tráfico el día del lanzamiento.
Preguntas para adquisiciones, seguridad e ingeniería
Algunas que he tenido que responder esta semana:
- El precio se ha duplicado. La tarifa estándar es $5 por 1M tokens de entrada y $30 por 1M de salida, según la página oficial de precios de OpenAI. Pro es $30 / $180. Las afirmaciones de eficiencia de tokens compensan parcialmente esto en las cargas de trabajo de Codex, pero en la mayoría de otras cargas de trabajo, espera que tu factura suba materialmente.
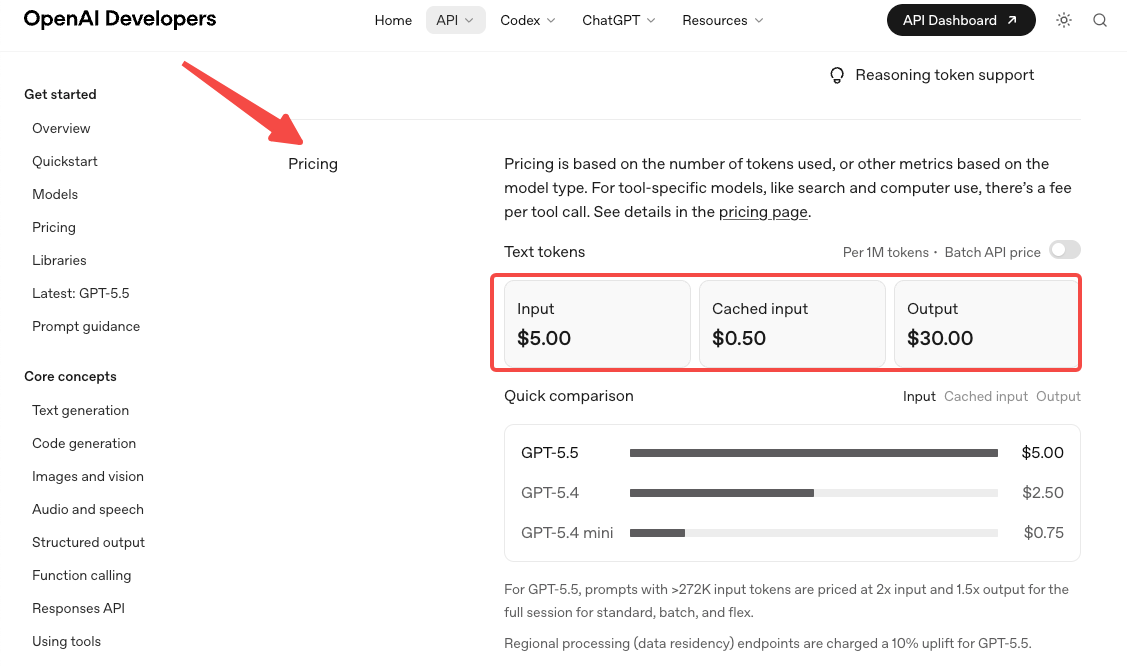
- El precio de contexto largo cambia a 272K. Por encima de ese umbral, la entrada es 2x y la salida es 1.5x para toda la sesión. Si tu flujo de trabajo cruza regularmente los 272K tokens, modela tu costo dos veces — una por debajo del umbral, una por encima. Esto atrapa a los equipos que construyeron alrededor de la estructura de niveles de GPT-5.4 y asumieron que el nuevo modelo la heredaría.
- Seguridad necesita leer la tarjeta del sistema. GPT-5.5 viene con clasificadores de ciberseguridad más estrictos, documentados en la tarjeta del sistema de GPT-5.5. Algunas cargas de trabajo legítimas serán bloqueadas inicialmente mientras OpenAI las ajusta. Vale la pena señalárselo a cualquiera que ejecute herramientas de seguridad, pipelines de análisis de código o flujos de trabajo de red team a través de la API.
Qué Aún Necesita Verificación Antes del Uso en Producción
IDs de modelo, límites de velocidad, precios y compatibilidad de herramientas
Verificaría esto en este orden:
1.IDs de modelo y snapshots. Bloquea a un snapshot, no al alias. Los alias cambian; los snapshots no. Verifica la lista disponible en la página del modelo GPT-5.5 antes de codificar nada en tu cliente.
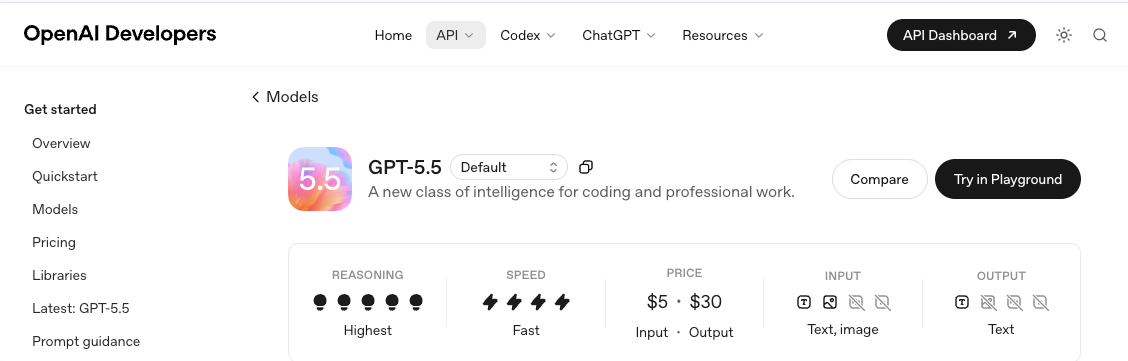
2.Los límites de velocidad de tu nivel. El sistema de niveles de OpenAI promueve automáticamente según el gasto, pero los límites del día del lanzamiento pueden ser más estrictos que los que disfruta GPT-5.4 hoy. La documentación de límites de velocidad de OpenAI es donde empezaría, y vale la pena ejecutar una prueba de ráfaga sintética contra tu nivel actual antes de asumir que el margen está ahí.
3.Comportamiento de herramientas y salida estructurada. La llamada a funciones, la búsqueda web y las salidas estructuradas funcionan, pero los esquemas exactos y las interacciones del modo de razonamiento necesitan una prueba de humo contra tus definiciones de herramientas reales. He visto configuraciones de esfuerzo de razonamiento cambiar el comportamiento de reintento de maneras que no aparecen hasta que alcanzas el tráfico de producción.
Rendimiento y detalles de implementación empresarial
Para cualquiera que maneje volumen serio: Batch y Flex funcionan a la mitad de la tarifa estándar, Priority a 2.5x. Traducción: si tu trabajo tolera la asincronía, Batch en GPT-5.5 cuesta lo mismo por token que GPT-5.4 en estándar. Ese es el arbitraje real oculto en este lanzamiento, y casi nadie con quien he hablado lo ha tenido en cuenta todavía. El desglose de precios de GPT-5.5 en apidog explica los ejemplos trabajados mejor de lo que yo lo haría aquí.
Planificación Directa con el Proveedor vs Preparación Basada en Plataforma
Trabajo en una plataforma que agrega acceso a modelos, así que mi sesgo está sobre la mesa. Pero el argumento estructural es el mismo independientemente de qué plataforma uses: cuando un solo proveedor lanza un modelo con precio 2x el primer día, el caso para la lógica de enrutamiento se fortalece, no se debilita.
La integración directa con el proveedor se ve así: reescribe tu cliente, vuelve a probar tus prompts, rehace tu modelo de costos, repite por proveedor. Las plataformas multimodelo — WaveSpeedAI incluida, pero también otras — te permiten cambiar modelos con un cambio de configuración. La compensación es que estás agregando una capa entre tú y la fuente. Para equipos de alta frecuencia que publican diariamente, esa capa generalmente vale la abstracción. Para un equipo que ejecuta un modelo en una carga de trabajo a bajo volumen, no lo es.
Planificaría una configuración de enrutamiento de todas formas. Consultas premium a GPT-5.5, tráfico rutinario a GPT-5.4 u otro modelo de frontera — este patrón por sí solo tiende a reducir las facturas un 40–60% frente a los valores predeterminados de un solo modelo, independientemente de qué proveedor utilices como centro.
Preguntas Frecuentes
¿Ya se ha lanzado GPT-5.5 en la API?
Sí, a partir del 24 de abril de 2026. El lanzamiento del 23 de abril cubrió solo ChatGPT y Codex; la API siguió un día después. Tanto gpt-5.5 como gpt-5.5-pro son accesibles en los endpoints de Responses y Chat Completions con una ventana de contexto de 1M tokens.
¿Qué deben verificar los equipos antes de que comience el trabajo de integración?
El impacto en el precio con tu mezcla real de tokens, los límites máximos de velocidad en tu nivel actual, el respaldo a GPT-5.4 configurado y probado, y un breve arnés de evaluación comparando los dos modelos en tu carga de trabajo real. Bloquea a un ID de snapshot, no al alias.
¿Vale la pena esperar en lugar de usar GPT-5.4?
Depende de la carga de trabajo. Para tareas de codificación agéntica y uso de computadora, GPT-5.5 muestra ganancias significativas, como se documenta en la cobertura del lanzamiento de TechCrunch. Para cargas de trabajo donde GPT-5.4 ya cumple con tu barra de calidad, el precio por token duplicado es difícil de justificar sin un aumento medible.
¿Cómo deben prepararse los equipos para una implementación rápida de la API?
Construye el arnés de evaluación ahora, enruta a través de una capa de abstracción si aún no lo haces, y asume que los límites de velocidad se ajustarán antes de que se amplíen. No prepagues grandes saldos de crédito — los precios de esta generación todavía están cambiando.
¿El precio duplicado realmente significa facturas duplicadas?
No, pero cerca. Las ganancias en eficiencia de tokens en cargas de trabajo de Codex llevan las facturas del mundo real por debajo de 2x. En otras cargas de trabajo, espera algo más cercano al precio de lista. El procesamiento por lotes a mitad de tarifa es la palanca que vale la pena usar primero.
Conclusión
La API está activa. Los precios cambiaron. Los límites de velocidad todavía se están estabilizando. Nada de eso significa que debas apresurarte. Lo que significa es que la ventana de planificación que la mayoría de los equipos esperaba se cerró más rápido de lo previsto, y el trabajo ahora es verificación en lugar de espera.
Estoy ejecutando mi propia migración durante las próximas dos semanas. Si GPT-5.5 permanece en mi enrutamiento predeterminado después de ese punto — aún no lo sé. Para eso es la evaluación.
Más información próximamente.
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado

API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción

Precios de GPT-5.4 Mini: Costos de entrada, caché y salida

API de MAI-Image-2.5: Lo que los desarrolladores deben saber
