Claude Mythos vs Claude Opus 4.6: Lo que la Filtración Revela para los Desarrolladores
Claude Mythos vs Opus 4.6: lo que la filtración sugiere sobre la brecha de capacidades, y si los desarrolladores deberían esperar o construir ahora.

Mientras estaba en medio de un sprint trabajando en una integración de Claude Code la semana pasada, la filtración de Mythos apareció en mi feed. Tres mensajes de Slack en diez minutos, todos variaciones de la misma pregunta: “¿Deberíamos pausar el desarrollo?” Esta es Dora, entusiasta de la IA, que ha estado siguiendo la historia de cerca desde entonces — y creo que la respuesta es más matizada de lo que el hype sugiere.
Disponible en WaveSpeedAI — precios transparentes por token, endpoint compatible con OpenAI. Claude Opus 4.6 API → · Claude Opus 4.7 API → · Abrir Playground →
Déjame explicarte qué dice realmente la filtración, qué ofrece actualmente Opus 4.6 y cómo tomar una decisión real sobre el momento adecuado.
Base: Lo que Claude Opus 4.6 ofrece actualmente a los desarrolladores
Antes de entrar en la especulación sobre Mythos, anclemos en lo que está disponible y documentado hoy.
Rendimiento en codificación y tareas agénticas
Claude Opus 4.6 logra 65,4% en Terminal-Bench 2.0 y 72,7% en OSWorld, lo que lo convierte en el modelo públicamente disponible más potente de Anthropic para tareas de codificación y uso de computadora. Ese número de Terminal-Bench no es solo un trofeo de benchmark — representa capacidad agéntica real: depuración de múltiples pasos, refactorización a gran escala y encadenamiento autónomo de herramientas en flujos de trabajo extensos.
El modelo está construido para agentes que operan a través de flujos de trabajo completos en lugar de indicaciones únicas, lo que lo hace especialmente efectivo para bases de código grandes, refactorizaciones complejas y depuración de múltiples pasos que se desarrolla con el tiempo. Si estás construyendo agentes de codificación o pipelines agénticos, este es el modelo que realmente cierra issues y entrega código a calidad de producción.
Lo que importa operacionalmente: Opus 4.6 divide las tareas complejas en subtareas independientes, ejecuta herramientas y subagentes en paralelo, e identifica bloqueos con precisión real. Ese es el comportamiento que marca la diferencia en automatizaciones adyacentes a CI/CD reales, no solo en entornos de demostración.
Disponibilidad de la API, precios y documentación
Esta es la parte que importa para tu línea de tiempo de toma de decisiones. Claude Opus 4.6 ofrece razonamiento de vanguardia a $5 de entrada / $25 de salida por millón de tokens — una reducción del 67% respecto a la era de Opus 4.1 a $15/$75. La documentación completa de la API de Claude es pública, con versiones y estable. Puedes acceder a ella mediante claude-opus-4-6 hoy mismo.
Una característica destacada de la generación 4.6 es que la ventana de contexto completa de 1 millón de tokens está incluida a precios estándar, eliminando los recargos premium de contexto largo que se aplicaban a modelos anteriores. Para equipos que trabajan con ingesta de bases de código grandes o flujos de trabajo de investigación extensos, eso representa una reducción de costos significativa en comparación con generaciones anteriores.
Palancas de optimización de costos que están completamente documentadas y disponibles ahora mismo:
Lo que dice la filtración de Claude Mythos sobre la brecha
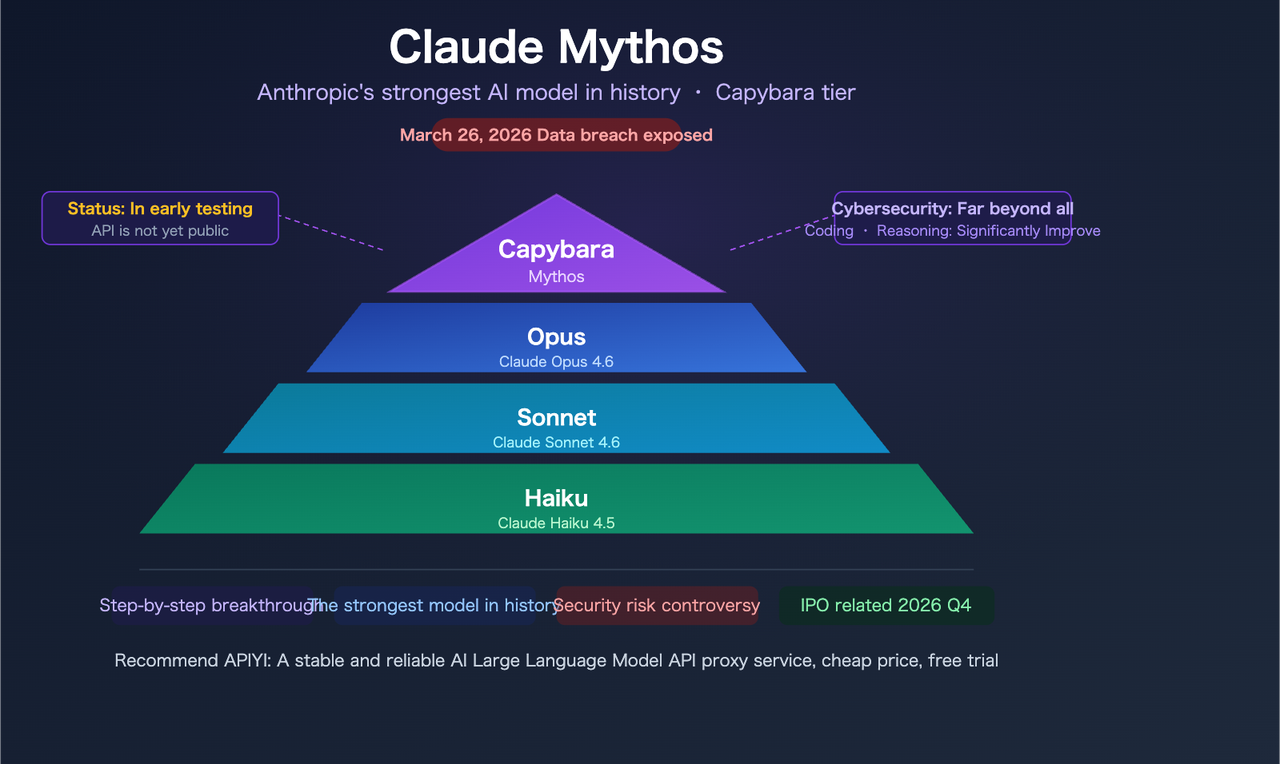
A principios de este mes, Fortune informó que Anthropic había expuesto accidentalmente casi 3.000 archivos internos en un almacén de datos mal configurado y con búsqueda pública. Entre ellos: un borrador de publicación de blog sobre un modelo llamado Claude Mythos — también conocido internamente como “Capybara.”
Encuadre importante antes de profundizar: todo lo que sigue proviene de un documento borrador no verificado, no de un lanzamiento oficial. No hay benchmarks públicos, no hay acceso a la API, no hay página de precios. Anthropic ha confirmado que el modelo existe y está en pruebas limitadas. Todo lo demás sigue siendo un borrador.
Codificación — “Puntuaciones dramáticamente más altas” desglosadas
El blog filtrado afirma: “En comparación con nuestro mejor modelo anterior, Claude Opus 4.6, Capybara obtiene puntuaciones dramáticamente más altas en pruebas de codificación de software, razonamiento académico y ciberseguridad, entre otros.” Ese es un lenguaje significativo de un documento interno — “dramáticamente más altas” no es una copia de marketing con matices, es una afirmación interna fuerte.
Lo que no tenemos: números específicos. No se han publicado puntuaciones específicas más allá del lenguaje cualitativo en el borrador. Cualquiera que cite cifras exactas de benchmarks de Mythos en este momento las está fabricando. La lectura honesta aquí es que la evaluación interna de Anthropic mostró una brecha lo suficientemente grande como para justificar un nuevo nivel de producto — lo cual es en sí mismo una señal significativa, pero no lo mismo que tener datos verificados.

Mejoras en razonamiento académico
El borrador filtrado agrupa el razonamiento académico junto con la codificación como una capacidad diferenciada clave. Anthropic describe a Mythos como “un modelo de propósito general con avances significativos en razonamiento, codificación y ciberseguridad.” Para los desarrolladores que construyen asistentes de investigación, pipelines de análisis de documentos o flujos de trabajo de razonamiento legal/financiero, esto merece atención — Opus 4.6 ya logra 90,2% en BigLaw Bench, y si Mythos amplía ese límite, el área de superficie de casos de uso se expande considerablemente.
Capacidades de ciberseguridad: Territorio nuevo
Esta es la dimensión de capacidad que está recibiendo más cobertura — y por una buena razón. El borrador filtrado describe el modelo como “actualmente muy por delante de cualquier otro modelo de IA en capacidades cibernéticas” y advierte que “presagia una próxima ola de modelos que pueden explotar vulnerabilidades de maneras que superan con creces los esfuerzos de los defensores.”
Los documentos internos filtrados advierten que el modelo podría aumentar significativamente los riesgos de ciberseguridad al encontrar y explotar rápidamente vulnerabilidades de software, potencialmente acelerando una carrera armamentista cibernética. Por eso el lanzamiento inicial de Anthropic está restringido a organizaciones enfocadas en la ciberdefensa — un movimiento inusual que señala una preocupación genuina sobre el mal uso, no solo teatro de seguridad estándar.
La tensión de uso dual aquí es real. El actual Opus 4.6 de Anthropic ya demostró la capacidad de detectar vulnerabilidades previamente desconocidas en bases de código de producción, una capacidad que la empresa reconoció era de uso dual — ayudando tanto a hackers como a defensores. Mythos parece impulsar esa capacidad significativamente más, lo que explica el lanzamiento cauteloso.
Este es un nivel nuevo, no una actualización de versión — Por qué importa
Capybara por encima de Opus estructuralmente
El borrador filtrado afirma: “Capybara es un nombre nuevo para un nuevo nivel de modelo: más grande y más inteligente que nuestros modelos Opus — que eran, hasta ahora, los más potentes.” Esto es estructuralmente diferente de Opus 4.5 → Opus 4.6. Anthropic actualmente tiene tres niveles: Haiku, Sonnet, Opus. Capybara añadiría un cuarto por encima de todos ellos.
Eso importa en cómo arquitectes tus sistemas. Si estás construyendo bajo el supuesto de que Opus siempre es el techo, un nuevo nivel por encima significa posibles actualizaciones de capacidad que no son solo incrementos de ajuste fino — representan una clase diferente de tasas de éxito de tareas.
Precios: Más caro por diseño
Aún no existe un precio oficial, pero la señal estructural es clara. El borrador del blog señala que el modelo es costoso de ejecutar y aún no está listo para el lanzamiento general. Dado que Capybara se ubica por encima de Opus en un nivel nuevo, espera precios superiores al actual $5/$25 por millón de tokens para Opus 4.6. Cuánto más alto es genuinamente desconocido — pero planifica que sea significativamente más alto, no solo un pequeño incremento.
Esto no es necesariamente una mala noticia. La reducción del 67% en el precio de Opus 4.1 a Opus 4.6 muestra que Anthropic ha aprendido a bajar los precios insignia con cada generación. Un lanzamiento de Capybara a precios premium hoy no significa que se mantenga así en 12 meses. El patrón sugiere que la pregunta real de ROI es si el salto de capacidad justifica el costo en tu distribución específica de tareas.

¿Debería tu equipo esperar a Claude Mythos?
Esta es la decisión real por la que estás aquí. Este es el marco honesto.
Si estás construyendo agentes de codificación o flujos de trabajo agénticos
Construye ahora con Opus 4.6. La brecha de capacidad puede ser real, pero esperar un modelo no lanzado sin cronograma público no es una estrategia de producto. Opus 4.6 ya es el modelo públicamente disponible más potente para codificación agéntica — Terminal-Bench 2.0 al 65,4% es una línea base significativa que soporta casos de uso de producción hoy.
El punto más importante: las decisiones arquitectónicas que tomes ahora — estrategia de caché de prompts, orquestación de subagentes, patrones de uso de herramientas — se transferirán directamente a Mythos cuando se lance. Construye sobre Opus 4.6, diseña para enrutamiento agnóstico al modelo, y estarás en una posición mucho mejor para migrar que los equipos que esperaron y comenzaron desde cero.
Si tu prioridad es la eficiencia de costos a escala
Definitivamente construye ahora. Se espera que Mythos sea más caro que Opus 4.6, y no hay indicios de un nivel económico equivalente en el lanzamiento. Si estás ejecutando cargas de trabajo de alto volumen donde $5/$25 por millón de tokens ya requiere una optimización cuidadosa con procesamiento por lotes y caché de prompts, es poco probable que Mythos sea tu modelo predeterminado — incluso después de que esté disponible públicamente. Usa el tiempo para optimizar tus flujos de trabajo de Opus 4.6; esos ahorros son reales y están disponibles hoy.
Los cálculos que vale la pena hacer: un equipo que gasta $2.500/mes en Opus 4.6 estándar puede llegar realísticamente a ~$250/mes con mezcla de modelos, procesamiento por lotes y caché. Esa reducción del 90% se compone significativamente durante los meses que pasarías esperando.
Si tu caso de uso involucra investigación de vulnerabilidades o seguridad
Este es el único caso donde esperar tiene sentido — pero es posible que no puedas elegir. El grupo de acceso inicial para Mythos está enfocado en investigadores de seguridad y defensores — el objetivo es preparar las defensas antes de que las capacidades ofensivas del modelo estén ampliamente disponibles. Si tu equipo trabaja en investigación de seguridad ofensiva o herramientas defensivas, el movimiento correcto es solicitar acceso anticipado a través de los canales de Anthropic y continuar construyendo sobre Opus 4.6 mientras tanto.
Para herramientas de seguridad empresarial general (escaneo de código, cumplimiento normativo, triaje de vulnerabilidades), Opus 4.6 ya es capaz y está completamente disponible. Mythos probablemente extiende el techo, no el suelo.
Qué hacer mientras Mythos no está disponible públicamente
Concretamente, aquí te explicamos cómo evitar esfuerzo desperdiciado mientras te mantienes posicionado para adoptar Mythos eficientemente:
Diseña para enrutamiento agnóstico al modelo. Abstrae tus llamadas al modelo detrás de una capa de enrutamiento para que intercambiar claude-opus-4-6 por una futura cadena de modelo claude-capybara-* sea un cambio de configuración, no una reescritura arquitectónica. Esta es una buena práctica independientemente de Mythos — también te permite enrutar tareas sensibles al costo a Sonnet 4.6 hoy.
# Ejemplo: wrapper de enrutamiento agnóstico al modelo
import anthropic
MODEL_CONFIG = {
"flagship": "claude-opus-4-6", # cambia aquí cuando se lance Mythos
"balanced": "claude-sonnet-4-6",
"fast": "claude-haiku-4-5-20251001"
}
def call_claude(task_tier: str, messages: list, **kwargs):
client = anthropic.Anthropic()
return client.messages.create(
model=MODEL_CONFIG[task_tier],
max_tokens=1024,
messages=messages,
**kwargs
)Implementa la caché de prompts ahora. Según la documentación de caché de prompts de Anthropic, las escrituras en caché incurren en un recargo del 25% en el primer acceso, luego se leen con un descuento del 90% en los accesos posteriores. Para flujos de trabajo agénticos con prompts de sistema repetidos o bloques de contexto grandes, esta es la optimización de costos de mayor impacto disponible — y funcionará de la misma manera en Mythos.
Sigue el cadence de lanzamiento oficial. Anthropic ha confirmado las pruebas con clientes de acceso anticipado. El modelo de lanzamiento escalonado que Anthropic está usando — primero socios de seguridad, luego acceso más amplio — sugiere que la disponibilidad general de la API probablemente esté a semanas o meses de distancia, no a días.
Evalúa tu distribución de tareas honestamente. Si el 80% de tus llamadas a la API son resumen de documentos, preguntas y respuestas, o extracción estructurada, los avances de Mythos en codificación y ciberseguridad pueden no mover mucho tu aguja. Opus 4.6 ya es lo suficientemente potente en esas cargas de trabajo. Guarda tu evaluación de Mythos para las tareas donde actualmente estás alcanzando el límite de Opus.
Preguntas frecuentes
P: ¿Puedo usar Claude Mythos hoy?
No. A finales de marzo de 2026, Claude Mythos (Capybara) solo está disponible para un pequeño grupo de clientes de acceso anticipado, específicamente aquellos que trabajan en aplicaciones de ciberdefensa. No hay API pública, no hay documentación y no hay fecha de lanzamiento anunciada. Claude Opus 4.6, accesible mediante claude-opus-4-6 en la API de Anthropic, sigue siendo el modelo públicamente disponible más potente.
P: ¿Opus 4.6 sigue siendo el mejor modelo público de Claude?
Sí. Claude Opus 4.6 y Sonnet 4.6 siguen siendo los modelos de Claude públicamente disponibles más capaces — y ya son notablemente potentes para codificación, razonamiento y tareas complejas. Opus 4.6 lidera los rankings públicos para codificación agéntica y está completamente documentado con acceso estable a la API en la plataforma de Anthropic, AWS Bedrock, Google Vertex AI y Microsoft Foundry.
P: ¿Cuánto más caro será Claude Mythos?
Desconocido. El borrador filtrado confirma que el modelo es “costoso de ejecutar,” y el nuevo nivel Capybara ubicado por encima de Opus estructuralmente implica una prima de precio por encima del actual $5/$25 por millón de tokens para Opus 4.6. No se ha publicado ningún precio oficial. El precedente histórico muestra que Anthropic reduce el precio insignia con el tiempo en las generaciones de modelos, por lo que el precio de lanzamiento temprano puede no reflejar el costo a largo plazo.
Publicaciones anteriores:
- Claude Sonnet 4.6: Un modelo de trabajo que “no acapara el protagonismo”
- GLM-5 vs DeepSeek V3 vs GPT-5: Velocidad y costo para desarrolladores
- GLM-5 vs GLM-4.7: ¿Deberías actualizar? (Benchmarks)
- ¿Qué es GLM-5? Arquitectura, velocidad y acceso a la API
- Inicio rápido de la API GLM-5 en WaveSpeed (Ejemplos de código)
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado

API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción

Precios de GPT-5.4 Mini: Costos de entrada, caché y salida

API de MAI-Image-2.5: Lo que los desarrolladores deben saber
