Capacidades de Ciberseguridad de Claude Mythos: Lo que los Equipos de Desarrollo y Seguridad Necesitan Saber
Claude Mythos ha generado serias preocupaciones de ciberseguridad. Esto es lo que significan las afirmaciones filtradas para los equipos de desarrollo y seguridad que evalúan este modelo.

“¿Deberíamos preocuparnos por esto?” El mensaje del equipo de seguridad del cliente llegó a Slack mientras revisaba opciones internas de herramientas de IA y la historia de la filtración de Anthropic apareció en mi feed.
Disponible en WaveSpeedAI — precios transparentes por token, endpoint compatible con OpenAI. Claude Opus 4.7 API → · Abrir Playground →
Esa pregunta siguió surgiendo durante las siguientes 48 horas. No de entusiastas de la IA, sino de CISOs, responsables de seguridad y desarrolladores que construyen sobre infraestructura de IA y de repente se encontraron en una conversación para la que no estaban preparados.
La historia de Mythos no es solo un anuncio de producto de IA. Es una señal sobre hacia dónde se dirige el entorno de amenazas, y entender qué está confirmado frente a qué es especulación importa más de lo habitual cuando aparece un nuevo modelo. Y en este artículo, vamos a profundizar juntos en la respuesta a esta pregunta.
Lo que el Borrador Filtrado Reveló sobre las Capacidades de Ciberseguridad de Mythos
El borrador del post de blog filtrado — parte de casi 3.000 activos internos expuestos — contenía dos afirmaciones llamativas sobre ciberseguridad que han sido ampliamente citadas. Las propias palabras de Anthropic, escritas internamente antes de cualquier anuncio público, describían el modelo no publicado (vinculado internamente al nivel “Capybara” y denominado Claude Mythos) como “actualmente muy por delante de cualquier otro modelo de IA en capacidades cibernéticas”. Además advertía que el modelo “presagia una próxima ola de modelos que pueden explotar vulnerabilidades de formas que superan con creces los esfuerzos de los defensores”.
Un segundo párrafo clave mostraba una cautela inusual: “Al prepararnos para lanzar Claude Mythos, queremos actuar con especial precaución y comprender los riesgos que plantea — incluso más allá de lo que aprendemos en nuestras propias pruebas. En particular, queremos comprender los riesgos potenciales a corto plazo del modelo en el ámbito de la ciberseguridad — y compartir los resultados para ayudar a los defensores cibernéticos a prepararse.”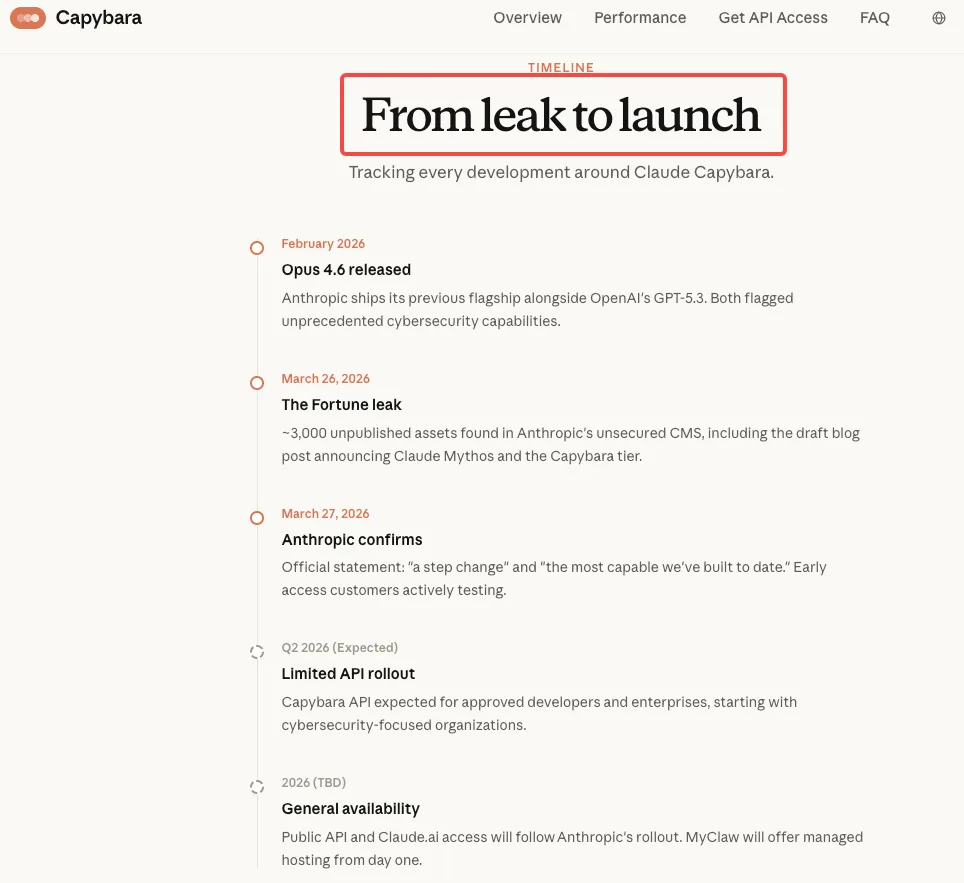
Este enfoque trata el riesgo de ciberseguridad no como una limitación manejable, sino como una externalidad significativa que requiere compartir de forma proactiva con los defensores. Es una postura notablemente diferente a las versiones anteriores de Anthropic.
¿Qué falta en la filtración? Números de benchmarks específicos, categorías de exploits o metodología detallada. Las afirmaciones de “puntuaciones dramáticamente más altas en pruebas de ciberseguridad” representan el alcance total de las capacidades divulgadas. Cualquier cosa más específica que circule en línea es extrapolación.
Por qué Anthropic Trata Esto como un Riesgo Sin Precedentes
Lo que Realmente Significa “Muy por Delante de Cualquier Otro Modelo de IA en Capacidades Cibernéticas”
Esta afirmación aterriza de manera diferente si entiendes de lo que ya es capaz Opus 4.6 — la línea base actual. Mythos no supera un listón bajo.
Usando Claude Opus 4.6, el Equipo Rojo de Frontera de Anthropic encontró y validó más de 500 vulnerabilidades de alta gravedad en bases de código de código abierto en producción — errores que habían pasado desapercibidos durante décadas, a pesar de años de revisión por expertos. El equipo no utilizó instrucciones especializadas ni un entorno personalizado, confiando únicamente en las capacidades predeterminadas del modelo.
Un caso notable: Opus 4.6 identificó una inyección SQL ciega en Ghost CMS (una plataforma con más de 50.000 estrellas en GitHub y un historial de seguridad previamente impecable) en aproximadamente 90 minutos.
La diferencia estructural entre el descubrimiento de vulnerabilidades impulsado por IA y el fuzzing tradicional es un contexto importante aquí. Los fuzzers introducen entradas en el código hasta que algo falla. Claude razona sobre el código: rastrea la lógica entre componentes, lee historiales de commits para encontrar variantes no parcheadas de errores corregidos, y evalúa qué rutas de código son intrínsecamente arriesgadas en lugar de estudiar cada entrada posible. Mythos, según la propia evaluación interna de Anthropic, hace esto mejor que cualquier otra cosa disponible actualmente — por un margen significativo.
El Problema de la Brecha del Defensor: Por qué el Ataque Puede Superar a la Defensa
La perspectiva más importante del borrador no era catalogar nuevos tipos de ataques. Era articular por qué existe en primer lugar la asimetría atacante-defensor. Los atacantes necesitan encontrar una debilidad. Los defensores necesitan cubrirlo todo. Un modelo de IA que puede razonar sobre código, identificar patrones de vulnerabilidades potenciales y ayudar con el refinamiento de exploits comprime el tiempo desde “idea” hasta “ataque funcional”.
Según se informa, Anthropic ha advertido a altos funcionarios gubernamentales que Mythos podría hacer más probables los ciberataques a gran escala en 2026 al habilitar agentes autónomos altamente sofisticados. Una encuesta de Dark Reading de principios de 2026 encontró que el 48% de los profesionales de ciberseguridad ahora clasifican la IA agéntica como el principal vector de ataque del año — por delante de los deepfakes y la ingeniería social.
Este no es un problema que Mythos crea desde cero; es un acelerador. Los adversarios ya utilizan la IA sin dudarlo ni tener fricciones de cumplimiento. Los defensores que restringen el acceso a modelos de frontera corren el riesgo de ceder terreno crítico.
Aplicaciones Defensivas vs. Ofensivas: Dónde Está la Línea
Casos de Uso Legítimos: Escaneo de Vulnerabilidades, Red Teaming, Endurecimiento de Código
Las aplicaciones defensivas de las capacidades de Mythos son genuinamente significativas — y son la razón principal por la que Anthropic está construyendo y lanzando esto.
Claude Code Security, una nueva capacidad integrada en Claude Code, escanea bases de código en busca de vulnerabilidades de seguridad y sugiere parches de software específicos para revisión humana, permitiendo a los equipos encontrar y solucionar problemas de seguridad que los métodos tradicionales a menudo pasan por alto. Nada se aplica sin aprobación humana: Claude Code Security identifica problemas y sugiere soluciones, pero los desarrolladores siempre toman la decisión.
La capacidad de nivel Mythos aplicada a este flujo de trabajo significaría encontrar clases de vulnerabilidades que incluso Opus 4.6 pasa por alto — fallos dependientes del contexto en la lógica de negocio, patrones de interacción entre múltiples componentes, bypasses de autenticación que requieren comprender la arquitectura del sistema en lugar de los patrones de código. Para los equipos de seguridad que actualmente pagan por pruebas de penetración manuales en un ciclo trimestral, el escaneo continuo impulsado por IA con la calidad de razonamiento de nivel Mythos representa un cambio significativo en lo que es operativamente alcanzable.
Para los equipos de red teaming, el mismo poder requiere un alcance y autorización estrictos. El modelo en sí no distingue entre pruebas autorizadas y uso malicioso — esa responsabilidad recae en tus procesos y salvaguardas.
Lo que Anthropic Está Haciendo para Limitar el Uso Indebido
Junto con Opus 4.6, Anthropic desplegó sondas a nivel de activación para detectar y bloquear el uso indebido cibernético en tiempo real, reconociendo la posible fricción para la investigación de seguridad legítima. “Esto creará fricción para la investigación legítima y algo de trabajo defensivo, y queremos trabajar con la comunidad de investigación de seguridad para encontrar formas de abordarlo a medida que surja”, advirtió la empresa.
Para Mythos específicamente, los controles son estructurales en lugar de meramente técnicos. Según los documentos filtrados y las declaraciones públicas de Anthropic, el acceso inicial está restringido a investigadores de seguridad y defensores verificados — el objetivo es construir herramientas defensivas antes de que las capacidades ofensivas estén ampliamente disponibles. Esto refleja el manejo de Anthropic de versiones anteriores de alto riesgo y se alinea con las prácticas recomendadas por el Marco de Gestión de Riesgos de IA del NIST, que aboga por el despliegue por etapas con monitoreo continuo para sistemas de IA de doble uso.
Vale la pena revisar la sección de tácticas de IA adversarial del marco MITRE ATT&CK para cualquier equipo de seguridad que intente modelar la superficie de amenaza aquí. Las tácticas documentadas allí asumen modelos significativamente menos capaces que lo que representa Mythos.
Lo que los Clientes de Acceso Anticipado de Seguridad Están Evaluando
El borrador filtrado fue explícito sobre la prioridad de implementación de Anthropic: “Iremos expandiendo lentamente el acceso a Claude Mythos a más clientes que usan la API de Claude durante las próximas semanas. Dado que estamos particularmente interesados en los usos de ciberseguridad, es ahí donde pretendemos expandir el EAP inicialmente.”
El grupo de acceso anticipado está evaluando Mythos frente al problema específico para el que fue diseñado el modelo: encontrar vulnerabilidades en bases de código de producción endurecidas de manera más rápida y completa que las herramientas existentes. Los analistas señalan que podría comprimir la brecha ofensa-defensa en ambas direcciones — permitiendo un descubrimiento más rápido de vulnerabilidades, red teaming continuo y caza de amenazas, al mismo tiempo que reduce el listón para ataques sofisticados si se usa indebidamente.
Para los clientes de seguridad actualmente en el período de evaluación, las preguntas prácticas se centran en tres áreas: cómo Mythos se integra con los flujos de trabajo existentes de SIEM y gestión de vulnerabilidades, si los hallazgos del modelo pueden presentarse en formatos compatibles con los sistemas de tickets existentes, y cómo son los requisitos de revisión humana a escala.
En entrevistas con más de 40 CISOs de diversas industrias, VentureBeat encontró que los marcos de gobernanza formales para herramientas de escaneo basadas en razonamiento son la excepción, no la norma. Las respuestas más comunes fueron que el área se consideraba tan incipiente que muchos CISOs no pensaban que esta capacidad llegaría tan pronto en 2026. Los equipos dentro del programa de acceso anticipado están, en un sentido real, escribiendo el manual de gobernanza que seguirá el resto de la industria.
Implicaciones para los Equipos de Desarrolladores que Construyen sobre Infraestructura de IA
Si tu equipo está construyendo productos sobre Claude o cualquier modelo de IA de frontera, la situación de Mythos crea dos categorías distintas de preocupación.
La primera es directa: eres un objetivo potencial para ataques asistidos por IA, y esos ataques son cada vez más capaces.
La segunda preocupación es arquitectónica: cómo está asegurada tu infraestructura de IA contra la inyección de prompts, el acceso no autorizado a herramientas y el uso indebido de agentes. Las organizaciones necesitan tratar cada agente, bot y servicio de IA como una identidad, aplicando el mismo nivel de controles, permisos y supervisión a las identidades no humanas que a los usuarios humanos — requiriendo inventario de acceso y eliminando credenciales codificadas que crean bots inseguros.
En la práctica, esto significa varias cosas para los equipos que construyen sobre Claude hoy:
Limita estrictamente el acceso al servidor MCP. Cada servidor MCP que conectas a un agente de Claude es una superficie de ataque potencial. Las capacidades agénticas ampliadas que hacen que Claude Code sea poderoso también hacen que los permisos de agente mal definidos sean un vector de riesgo significativo.
Trata CLAUDE.md como un documento de seguridad. Las instrucciones en CLAUDE.md que definen qué herramientas puede usar un agente, qué archivos puede leer y qué operaciones puede realizar son controles de seguridad, no solo ayudas de productividad. Un CLAUDE.md mal escrito que otorga amplio acceso a archivos o permisos de herramientas amplifica el riesgo.
Aplica revisión humana a los parches generados por IA, no solo al código generado por IA. El código generado por IA tiene 2,74 veces más probabilidades de introducir vulnerabilidades XSS y 1,91 veces más probabilidades de introducir referencias a objetos inseguras en comparación con el código escrito por humanos. La misma capacidad de razonamiento que encuentra vulnerabilidades puede introducirlas. La revisión humana de los cambios relevantes para la seguridad no es opcional.
Preguntas Frecuentes
¿Pueden los equipos de seguridad acceder a Claude Mythos ahora?
No a través de ningún canal público. El plan de implementación del modelo refleja la preocupación por la ciberseguridad: el acceso anticipado está restringido a organizaciones de ciberseguridad defensiva verificadas. Para los equipos de seguridad que quieran prepararse, Claude Code Security — construido sobre Opus 4.6, disponible ahora en vista previa de investigación limitada para clientes Enterprise y Team — es la herramienta más accesible públicamente, y una línea base útil para comprender lo que extendería la capacidad de nivel Mythos.
¿Qué salvaguardas está construyendo Anthropic?
Las medidas confirmadas incluyen sondas de detección de uso indebido en tiempo real, implementación por etapas priorizando a los defensores y requisitos de intervención humana para los parches. Para Mythos, el énfasis está en la gobernanza del despliegue, los límites de las herramientas y los registros de auditoría.
¿Estará Claude Mythos disponible para red teaming comercial?
No confirmado. El grupo de acceso anticipado está enfocado en casos de uso de seguridad defensiva. El red teaming comercial — donde las organizaciones contratan empresas de seguridad para sondear activamente sus sistemas — se encuentra en una zona ambigua: es ataque autorizado. Dado el interés declarado de la empresa sobre el uso indebido ofensivo, espera controles de acceso significativos en lugar de acceso abierto a la API para casos de uso de red teaming.
Artículos anteriores:
- Claude Mythos vs Claude Opus 4.6: Lo que la Filtración Revela para los Desarrolladores
- Claude Mythos (Opus 5) Filtrado: Lo que Sabemos Hasta Ahora
- ¿Qué es Claude Mythos? Filtración, Nivel Capybara y lo que Anthropic Confirmó
- Claude Sonnet 4.6: Un Modelo de Trabajo que “No Acapara el Protagonismo”
- Claude Opus 4.6 y Sonnet 4.6: Todo lo que Necesitas Saber
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado
API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción
Precios de GPT-5.4 Mini: Costos de entrada, caché y salida
API de MAI-Image-2.5: Lo que los desarrolladores deben saber