Claude Code Agent Harness: Desglose de Arquitectura
Cómo Claude Code conecta herramientas, gestiona permisos y orquesta sesiones de agentes — un análisis técnico para desarrolladores.

Seguía encontrándome con la misma pregunta mientras construía mi propio sistema de llamadas a herramientas: ¿por qué conectar todo parece mucho más difícil que escribir prompts?
La parte del modelo se entendió rápido. Pero en el momento en que necesitaba que hiciera cosas — leer archivos, ejecutar comandos de shell, comunicarse con servicios externos — cada decisión parecía poder romper algo. Límites de permisos. Límites de contexto. Despacho de herramientas.
Luego, a finales de marzo de 2026, el código fuente de Claude Code quedó expuesto accidentalmente a través de un mapa de fuente npm en la versión 2.1.88. Más de 500.000 líneas de TypeScript, replicadas en pocas horas. Anthropic confirmó que fue un error de empaquetado — sin datos de clientes involucrados — y comenzó a emitir notificaciones DMCA.
Pero la arquitectura se convirtió en conocimiento público. Y lo que reveló no era el modelo. Era el harness.
Una nota sobre las fuentes: Los detalles aquí provienen de análisis de la comunidad, reproducciones de código abierto y la documentación pública y el blog de ingeniería de Anthropic — no del código filtrado en sí. Los detalles inciertos están marcados.
¿Qué es un Harness de Agente?
Definición y rol en sistemas agénticos
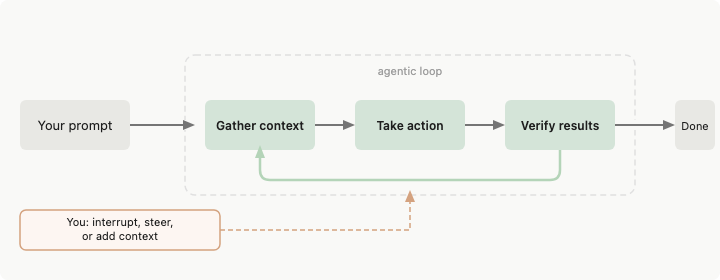
Un harness de agente es todo lo que existe entre el modelo de lenguaje y el mundo real. El modelo genera texto. El harness decide qué puede tocar ese texto.
La documentación de Anthropic para Claude Code lo describe directamente: Claude Code “proporciona las herramientas, la gestión de contexto y el entorno de ejecución que convierten un modelo de lenguaje en un agente de codificación capaz.” El modelo razona. El harness actúa.
Cuando tu agente lee un archivo, el harness decide si la lectura está permitida, qué sucede con el resultado y cuánto de la respuesta cabe en el siguiente prompt. El modelo nunca toca directamente el sistema de archivos.
Por qué el diseño del harness importa en producción
La mayoría de las demos de agentes omiten esta parte. Ves un modelo llamando a una función, obteniendo un resultado, llamando a otra. Se ve limpio. Luego lo ejecutas durante 45 minutos en una base de código real, y las cosas se desmoronan silenciosamente — el contexto se desborda, los permisos son demasiado laxos o demasiado molestos, los resultados de las herramientas se truncan sin que el modelo lo sepa.
El equipo de ingeniería de Anthropic ha escrito sobre esto: incluso un modelo de frontera ejecutándose en un bucle a través de múltiples ventanas de contexto tendrá un rendimiento inferior sin un harness bien diseñado. El agente intenta hacer demasiado a la vez, o declara el trabajo terminado prematuramente. El harness impone estructura a esa tendencia.

La Superficie de Herramientas de Claude Code
Categorías principales de herramientas
Basándose en la documentación oficial de Claude Code y los análisis públicos, Claude Code expone aproximadamente 19 herramientas con control de permisos. Las categorías principales: lecturas y ediciones de archivos, ejecución de shell (Bash), operaciones de Git, obtención web, edición de notebooks y llamadas a herramientas MCP. Los análisis de la comunidad sugieren que el número puede acercarse a 40 cuando se incluye la integración LSP, la generación de subagentes y las herramientas de coordinación interna.
Cada herramienta está aislada de forma independiente. No es “el agente tiene acceso al sistema de archivos” — es “el agente puede usar la herramienta Read, y Read tiene su propia compuerta de permisos que verifica un pipeline de reglas antes de que se ejecute cualquier cosa.”
Cómo se registran y despachan las herramientas
El modelo decide qué intentar. El sistema de herramientas decide qué está permitido. Arquitectónicamente separados.
Cada llamada a una herramienta pasa por una verificación de permisos antes de la ejecución. Los análisis profundos de la comunidad describen una función central que evalúa las reglas de denegar/preguntar/permitir en ese orden — denegar siempre gana. Tres posibles resultados: proceder silenciosamente, solicitar al usuario o bloquear.
Un modelo comprometido no puede eludir las verificaciones de seguridad siendo persuasivo. Al harness no le importa el argumento del modelo. Las reglas son las reglas.
Niveles de permisos
El modelo de permisos de Claude Code ha sido descrito por múltiples analistas de la comunidad como aproximadamente tres niveles:
Nivel 1 — Aprobación automática: Acciones de solo lectura o inherentemente seguras. Lecturas de archivos, búsqueda de texto, navegación de código. Estas no cambian el estado, por lo que se ejecutan sin interrupciones.
Nivel 2 — Solicitar confirmación: Acciones que modifican el estado de formas controladas. Ediciones de archivos, ciertos comandos de shell. En el modo automático (introducido en marzo de 2026), un clasificador en segundo plano que se ejecuta en Sonnet 4.6 evalúa si estos pueden proceder sin preguntar. El clasificador ve la solicitud del usuario y la llamada a la herramienta, pero no el texto en prosa del modelo — una elección de diseño deliberada para evitar que el modelo convenza a la compuerta para que lo deje pasar.
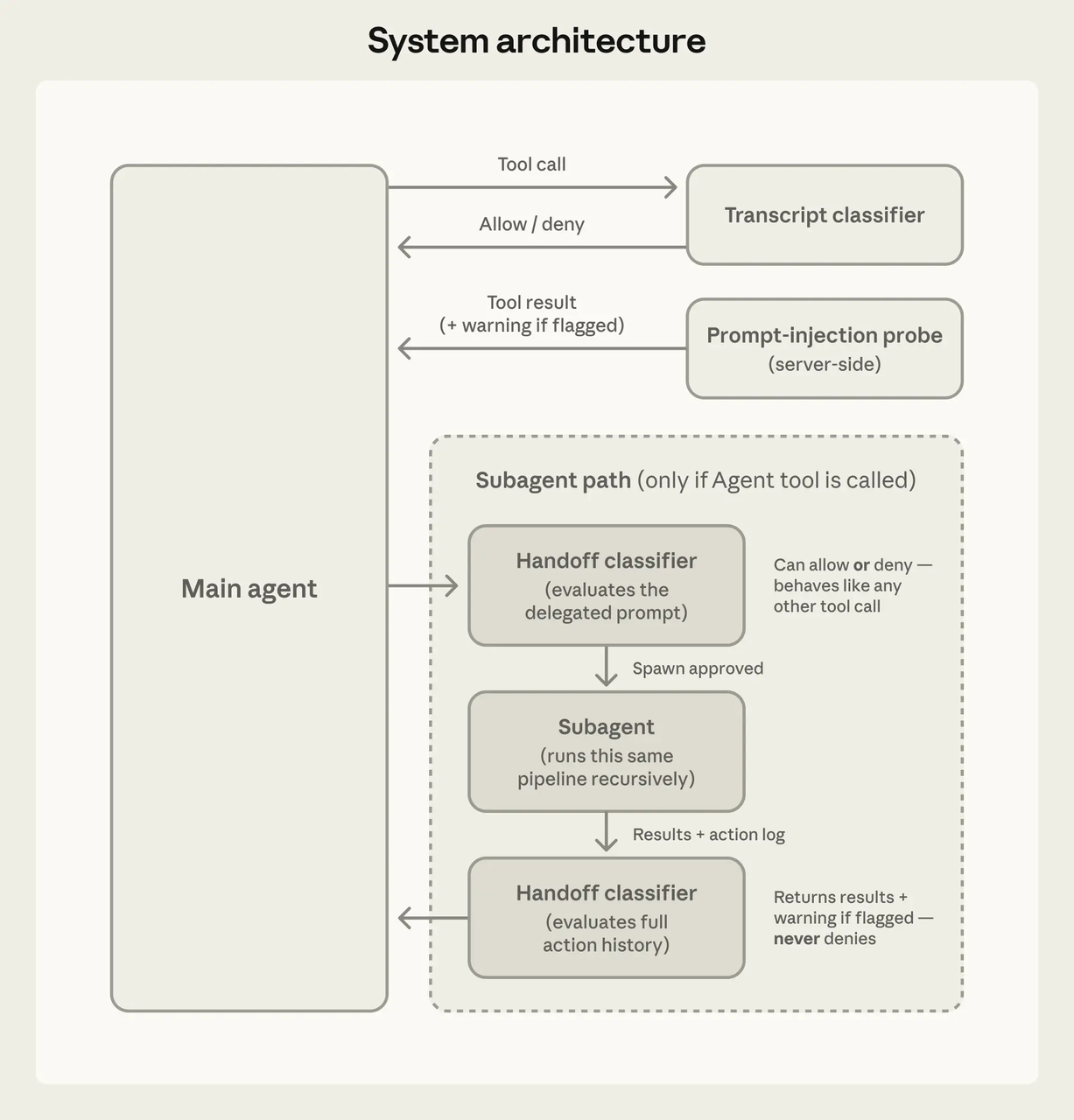 Nivel 3 — Requieren aprobación explícita o se bloquean: Operaciones de alto riesgo. Comandos de shell que podrían modificar el estado del sistema de forma impredecible, operaciones fuera del directorio de trabajo, cualquier cosa que parezca exfiltración de datos.
Nivel 3 — Requieren aprobación explícita o se bloquean: Operaciones de alto riesgo. Comandos de shell que podrían modificar el estado del sistema de forma impredecible, operaciones fuera del directorio de trabajo, cualquier cosa que parezca exfiltración de datos.
Una advertencia: el enfoque de tres niveles proviene del análisis de la comunidad, no de los documentos oficiales de Anthropic. El sistema oficial usa reglas de permitir/preguntar/denegar y seis modos de permisos (predeterminado, acceptEdits, plan, auto, dontAsk, bypassPermissions). Los “tres niveles” es un modelo mental útil, pero una simplificación.
Gestión de Sesión y Contexto
Cómo Claude Code rastrea el estado de la sesión
Claude Code acumula contexto a lo largo de una sesión — archivos leídos, comandos ejecutados, resultados de grep, diffs, salida de errores. Todo se apila en un prompt creciente. A diferencia de una interfaz de chat donde cada mensaje es algo independiente, una sesión de Claude Code es una memoria de trabajo continua.
Las sesiones se guardan localmente. Cada mensaje, uso de herramienta y resultado se almacena, lo que permite rebobinar, reanudar y bifurcar. Antes de los cambios de código, el harness toma instantáneas de los archivos afectados para que puedas revertirlos.
Truncación de salida y manejo del costo de tokens
Las salidas grandes de herramientas son un problema real. Claude Code establece un máximo predeterminado de 25.000 tokens para la salida de herramientas MCP, con una advertencia a los 10.000 tokens. Los autores de servidores pueden anotar herramientas para permitir resultados más grandes (hasta 500.000 caracteres), que se persisten en disco en lugar de mantenerse en contexto.
Este es el tipo de cosa en la que no piensas hasta que tu agente pierde silenciosamente el rastro de información porque el resultado de una herramienta fue truncado. Límites explícitos y configurables con respaldos basados en disco — vale la pena adoptarlo.
Comportamiento de compactación
Este me afectó antes de entenderlo. Cuando el uso de tokens alcanza aproximadamente el 98% de la ventana de contexto, Claude Code compacta automáticamente: resume el historial anterior para liberar espacio. Los metadatos críticos se preservan. Las imágenes y los PDFs se eliminan.
La parte complicada: la compactación puede perder detalles importantes. La solución práctica: pon todo lo crítico en CLAUDE.md, que el harness vuelve a leer en cada turno.
La investigación de Anthropic sobre el diseño de harness encontró que los reinicios completos de contexto — donde una nueva instancia de agente recoge desde un artefacto de transferencia — a veces funcionan mejor que la compactación para sesiones extendidas. Más complejidad de orquestación, pero mejor fidelidad del contexto.
Capa de Integración MCP
Cómo Claude Code se conecta a servidores MCP
 MCP (Model Context Protocol) es un estándar abierto para conectar herramientas de IA a servicios externos. Claude Code soporta tres modos de transporte: HTTP (recomendado para servidores remotos), stdio (para procesos locales) y SSE.
MCP (Model Context Protocol) es un estándar abierto para conectar herramientas de IA a servicios externos. Claude Code soporta tres modos de transporte: HTTP (recomendado para servidores remotos), stdio (para procesos locales) y SSE.
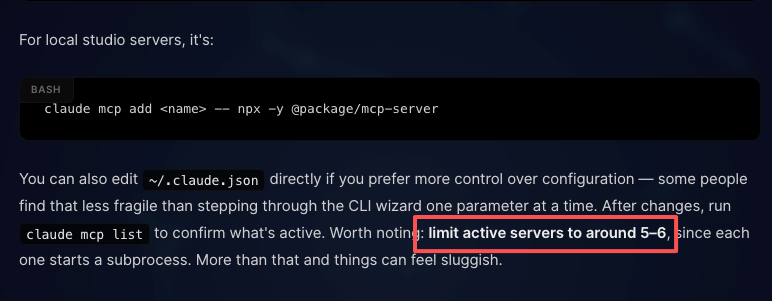
Agregar un servidor es un comando: claude mcp add server-name --transport http "URL". Después de eso, las herramientas del servidor aparecen como herramientas invocables en la sesión, sujetas al mismo pipeline de permisos que las herramientas integradas.
Descubrimiento de herramientas y flujos de autenticación
Un detalle que me impresionó: la búsqueda de herramientas. Cuando conectas servidores MCP, Claude Code no carga todos sus esquemas de herramientas en el contexto de antemano. Carga solo los nombres de las herramientas al inicio de la sesión, luego usa un mecanismo de búsqueda para descubrir las herramientas relevantes cuando una tarea realmente las necesita. Solo las herramientas que Claude usa entran en el contexto.
Esto mantiene bajo el overhead de MCP. Los flujos de autenticación dependen del servidor — OAuth, claves de API, encabezados. Claude Code requiere aprobación explícita del usuario para nuevos servidores MCP.
Qué está listo para producción vs. qué sigue evolucionando
La integración MCP es funcional y se usa activamente. Pero algunos límites prácticos que vale la pena conocer:
El límite recomendado es alrededor de 5–6 servidores MCP activos, ya que cada uno inicia un subproceso. La búsqueda de herramientas ayuda con el overhead de contexto, pero la latencia sigue aumentando más allá de eso.
 Las respuestas MCP grandes necesitan un manejo cuidadoso. El límite predeterminado de 25K tokens funciona para la mayoría de los casos de uso, pero se queda corto para esquemas de bases de datos. El respaldo de persistencia en disco ayuda, aunque el modelo solo obtiene una referencia en lugar del resultado completo en el contexto.
Las respuestas MCP grandes necesitan un manejo cuidadoso. El límite predeterminado de 25K tokens funciona para la mayoría de los casos de uso, pero se queda corto para esquemas de bases de datos. El respaldo de persistencia en disco ayuda, aunque el modelo solo obtiene una referencia en lugar del resultado completo en el contexto.
Y los servidores MCP construidos por la comunidad varían en calidad. Los documentos de Anthropic señalan explícitamente que los servidores de terceros pueden ser vectores de inyección de prompts. El sistema de permisos ayuda, pero la confianza sigue siendo tu responsabilidad.
Lecciones para Desarrolladores
Lo que esta arquitectura revela sobre los sistemas agénticos de nivel de producción
Algunos patrones del diseño de Claude Code que creo que se generalizan:
Separa el razonamiento de la aplicación de permisos. El modelo decide qué quiere hacer. Un sistema diferente decide si está permitido. Un modelo comprometido no puede anular las verificaciones de seguridad porque literalmente es una ruta de código diferente.
Haz explícita la gestión del contexto. Compactación, límites de truncación, búsqueda de herramientas, persistencia en disco — todos estos son mecanismos para gestionar activamente lo que ve el modelo. La mayoría de las implementaciones de agentes hobby tratan el contexto como una bolsa sin fondo. No lo es.
Diseña para la continuidad de la sesión. Instantáneas, cambios de archivos revertibles, CLAUDE.md como ancla persistente. Los agentes de larga duración necesitan memoria que sobreviva a la compresión del contexto.
La granularidad de permisos vale la pena. Reglas por herramienta, por patrón, por directorio con evaluación primero-denegar. Más trabajo que una bandera de “permitir todo”, pero es la diferencia entre una demo y un sistema desplegable.
Cuándo construir tu propio harness vs. usar una capa administrada
Tarea estrecha y bien definida — un bot de CI que ejecuta pruebas y publica resultados — puedes conectar un harness mínimo tú mismo. Unas pocas herramientas, una verificación de permisos simple, una ventana de contexto fija.
Sesiones extendidas, estado a través de reinicios de contexto, salida de herramientas no confiable, docenas de herramientas — construye sobre un harness existente o estúdialo de cerca. El Claude Agent SDK, la arquitectura Codex de OpenAI y LangGraph han resuelto problemas que eventualmente encontrarás.
La mayoría de los equipos subestiman la complejidad del harness. Yo ciertamente lo hice. El modelo es la parte fácil.
Preguntas Frecuentes
¿Qué es el harness de agente de Claude Code?
La capa de infraestructura entre el modelo Claude y el mundo real — despacho de herramientas, permisos, gestión de contexto, estado de sesión, conexiones MCP. Anthropic lo describe como lo que “convierte un modelo de lenguaje en un agente de codificación capaz.”
¿Cómo maneja Claude Code los permisos de herramientas?
Un pipeline basado en reglas evalúa cada llamada a herramienta: permitir, preguntar o denegar, con denegar siempre ganando. En modo automático, un clasificador en segundo plano en una instancia de modelo separada evalúa los casos ambiguos — y deliberadamente no ve la salida en prosa del agente para prevenir la inyección de prompts.
¿Está la integración MCP de Claude Code lista para producción?
Funcional y usada activamente, pero con límites prácticos en torno al conteo de servidores, el tamaño de las respuestas y la confianza en terceros. Está evolucionando rápidamente.
¿Puedo construir mi propio harness usando los mismos patrones?
Sí. El Claude Agent SDK expone los mismos modos de permisos, hooks y gestión de contexto. Proyectos de la comunidad como Everything Claude Code también han documentado patrones reutilizables.
¿Cuál es la diferencia entre paridad de especificaciones y paridad de comportamiento?
La paridad de especificaciones significa soportar las mismas herramientas y configuraciones. La paridad de comportamiento significa manejar los casos extremos de la misma manera — la compactación descartando una regla crítica, una herramienta devolviendo 100K tokens, un modelo intentando eludir permisos. Igualar la especificación es sencillo. Igualar el comportamiento lleva meses.
Algo que se ha quedado conmigo: el harness es la parte difícil. Todos asumen que el modelo es la ventaja competitiva. Y lo es — hasta que intentas hacer que haga cosas de manera confiable durante más de cinco minutos. Ahí es donde vive la ingeniería.
Publicaciones anteriores:
Artículos relacionados
Presentamos ByteDance Seedance 2.0 Mini en WaveSpeedAI

Claude Fable 5 con Fallback a Opus 4.8 Explicado

API de GLM-5.2: Precios, Contexto de 1M y Enrutamiento en Producción

Precios de GPT-5.4 Mini: Costos de entrada, caché y salida

API de MAI-Image-2.5: Lo que los desarrolladores deben saber
