Warum ist HappyHorse-1.0 plötzlich #1 auf dem Video-Leaderboard?
HappyHorse-1.0 hat Platz #1 bei Artificial Analysis erreicht – ohne öffentliches Team. Hier erfahren Sie, warum Elo Videoqualität über Markenbekanntheit stellt – und was das für Entwickler bedeutet.

Hey Leute. Hier ist Dora. Ich habe diese Woche gezählt, wie oft jemand in meinem Feed irgendetwas in der Art gefragt hat: „Was zum Teufel ist HappyHorse?” Sechs Mal. Sechs separate Threads. Und jeder hatte ein leicht anderes Gerücht dabei — es sei WAN 2.7, ein ByteDance-Stealth-Drop, irgendetwas von Alibaba. Niemand weiß es genau. Was alle bestätigen: Es tauchte um den 7.–8. April 2026 auf dem Artificial Analysis Video Leaderboard auf und übernahm sofort den ersten Platz in Text-to-Video und Image-to-Video.
Das sind die Fakten. Alles danach — wer es gebaut hat, wann die Gewichte erscheinen, ob es auf Platz 1 bleibt — ist noch ungeklärt.
Dieser Artikel geht darum, was das Leaderboard tatsächlich misst, warum ein unbekanntes Modell legitimerweise ganz oben landen kann, und was du als Entwickler mit diesen Informationen anfangen solltest — und was nicht.
So funktioniert die Artificial Analysis Video Arena
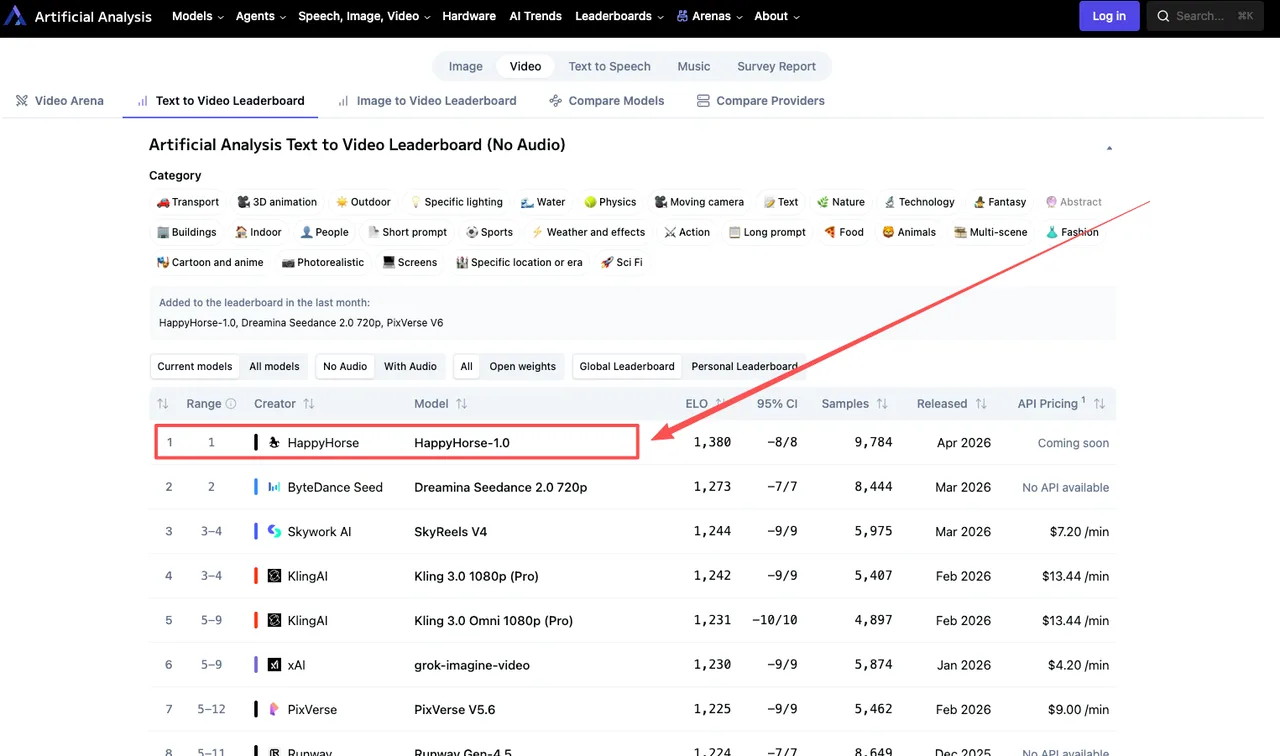
Bevor du einem Ranking vertraust, musst du verstehen, was das Ranking misst. Die Artificial Analysis Video Arena ist kein Benchmark, bei dem Modellentwickler ihre eigenen Werte einreichen — es ist ein blindes Nutzerabstimmungssystem.
Was Nutzer sehen (und was nicht)
Du gehst zur Arena, siehst zwei Videos, die aus demselben Textprompt oder Eingabebild generiert wurden, und wählst aus, welches du bevorzugst. Du weißt nicht, welches Modell welches Video erstellt hat. Keine Labels. Kein Kontext. Nur zwei Clips.
So beschreibt Artificial Analysis es direkt: „Nutzer vergleichen zwei Videos, die aus demselben Textprompt generiert wurden, ohne zu wissen, welches Modell welches Video erstellt hat.” Das ist der entscheidende Punkt. Es gibt keine Selbstmeldungen, keine vom Entwickler bereitgestellten Benchmarks, keine Marketingseite, die das Ergebnis beeinflusst.
Elo: signalzuverlässig, aber nicht unfehlbar
Das Ranking verwendet ein Elo-System — denselben Ansatz, der vom Schachturnier entlehnt wurde. Jedes Mal, wenn zwei Modelle in einer Abstimmung gegeneinander antreten, gewinnt der Gewinner Elo-Punkte und der Verlierer verliert einige. Ein Modell mit einem hohen Elo hat in Summe mehr Duelle gegen andere Modelle gewonnen als verloren.
Höhere Elo-Werte zeigen, dass ein Modell öfter bevorzugt wird. Das ist ein echtes Signal. Es basiert auf Tausenden realer menschlicher Entscheidungen, nicht auf synthetischen Tests, nicht auf handverlesenen Beispielen, nicht auf einer Modellkarte.
Stimmzahl und Stichprobengröße: der Teil, den die Leute überspringen
Hier ist das Problem mit Elo bei neuen Teilnehmern. Etablierte Modelle wie Seedance 2.0 haben Tausende von Stimmen hinter ihren Werten — Seedance 2.0 hat über 7.500 Abstimmungsproben in der T2V-Kategorie. HappyHorses Stimmzahl ist noch nicht öffentlich aufgeschlüsselt. Mehr Stimmen = stabilerer Wert. Ein neueres Modell mit weniger Duellen kann mit jeder neuen Stimme stärker schwanken.

Diese Zahlen werden sich mit mehr eingehenden Stimmen verschieben. Die Richtung dieser Verschiebung ist unbekannt. Behalte das im Hinterkopf, bevor du Pipeline-Entscheidungen auf Basis einer Zahl triffst, die zwei Tage alt ist.
Was HappyHorse-1.0 tatsächlich bewertet wird
Die aktuellen Zahlen, gezogen vom Live-Leaderboard Anfang April 2026:
T2V (ohne Audio): HappyHorse-1.0 führt mit einem Elo-Wert von 1357, vor Dreamina Seedance 2.0 mit 1273, SkyReels V4 mit 1244 und Kling 3.0 Pro mit 1243.
I2V (ohne Audio): HappyHorse-1.0 führt mit einem Elo von 1402, mit Seedance 2.0 bei 1355 und Grok Imagine Video bei 1331.
Der 84-Punkte-Abstand in I2V ohne Audio ist nicht gering. Ein 60-Punkte-Elo-Abstand bedeutet, dass ein Modell grob 58–59 % der blinden Duelle gewinnt — bedeutsam. Ein Abstand von 80+ Punkten ist noch stärker.
Die Audio-Geschichte kehrt sich um
Bei Image-to-Video mit Audio führt HappyHorse-1.0 aktuell mit einem Elo-Wert von 1160, mit Dreamina Seedance 2.0 bei 1158. Ein Abstand von 2 Punkten ist statistisches Rauschen. Und bei T2V mit Audio führt Seedance 2.0 mit 1220, HappyHorse liegt bei 1215.
Das Bild ist also differenzierter als „HappyHorse ist überall #1.” Es ist #1 mit einem signifikanten Vorsprung, wenn Audio ausgeschlossen ist. Wenn Audioqualität in die Gleichung einfließt, ist es im Wesentlichen gleichauf mit Seedance 2.0.
Was die Architekturaussagen behaupten (und was sie nicht beweisen)
Mehrere Seiten, die HappyHorse beschreiben, sagen, es laufe auf einer Single-Stream-Transformer-Architektur mit ungefähr 15 Milliarden Parametern, mit behaupteten Generierungsgeschwindigkeiten von etwa 38 Sekunden für einen 1080p-Clip auf einer einzelnen H100. Stand 8. April 2026 verweisen die GitHub- und Hugging-Face-Links auf diesen HappyHorse-Seiten auf „Demnächst verfügbar”-Seiten oder geben 404-Fehler zurück. Die Gewichte sind nicht öffentlich herunterladbar.
Diese Architekturaussagen sind plausibel — aber unbewiesen. Kein unabhängiges technisches Audit hat die Parameteranzahl, den Architekturtyp oder die Inferenzgeschwindigkeiten bestätigt. Behandle sie als behauptet, nicht als bestätigt.
Warum unbekannte Modelle bei Elo gewinnen können
Das ist das, was Menschen verwirrt, die annehmen, Leaderboards belohnen Markenbekanntheit.
Elo ist egal, wer das Modell gebaut hat. Es weiß nicht, ob du Google oder ein Drei-Personen-Labor bist. Artificial Analysis’ Video Arena verwendet das Elo-Bewertungssystem und verlässt sich vollständig auf echte, blinde Nutzerstimmen. Es ignoriert Parameter, Paper oder Hype — es interessiert sich nur für eine Frage: „Welches Video hast du nach dem Ansehen beider bevorzugt?”
Das ist eigentlich ein Feature. Es ist eines der wenigen Bewertungssysteme, bei dem eine finanzstarke Marke kein besseres Ergebnis erkaufen kann, indem sie ein günstiges Paper veröffentlicht.
Dieses Muster hat sich schon früher gezeigt
Anonyme Pre-Launch-Drops sind im chinesischen KI-Ökosystem zu einem Muster geworden. Die Pony-Alpha-Situation im Februar 2026 ist der deutlichste Präzedenzfall — ein Mysteriums-Modell tauchte auf OpenRouter auf, löste ein Ratespiel aus und stellte sich als Z.ais GLM-5 heraus, das einen stillen Stresstest durchführte. HappyHorse passt zu diesem Muster: unbekannter Name, keine Teamzuordnung beim Launch, Landingpage mit „Demnächst verfügbar”-GitHub-Links, starke Ergebnisse.
Ob es ein großes Labor ist, das einen stillen Fähigkeitscheck durchführt, oder ein wirklich neues Team — das ist noch ungeklärt. Aber der Elo-Wert selbst ist unabhängig davon real.
Die Einschränkung, die Elo nicht verbergen kann
Elo misst eine Sache: welches Video echte Nutzer in einem blinden Vergleich bevorzugten. Es misst nicht, wie das Modell in Batch-Läufen abschneidet. Es misst keine API-Verfügbarkeit, Latenz unter Last oder ob die Ausgabequalität konsistent bleibt, wenn du im Maßstab generierst statt Arena-Beispiele auszuwählen.
Ein Modell kann exzellente Blindtest-Ergebnisse haben und in der Produktion völlig unbrauchbar sein. Das sind separate Fragen.
Was „Leaderboard #1” für Entwickler nicht bedeutet
Hier würde ich verlangsamen, wenn du gerade eine Tool-Entscheidung auf Basis von HappyHorses aktuellem Ranking treffen willst.
Kein API, kein Produktionszugang
Drei Dinge würden HappyHorse von „Leaderboard-Eintrag” zu „echte Option” machen: ein GitHub-Repository mit tatsächlichen Gewichten und Inferenzcode, eine HuggingFace-Modellkarte mit überprüfbaren Details und einer Lizenz, oder ein API-Endpunkt mit dokumentierter Preisgestaltung. Nichts davon existiert zum Zeitpunkt dieses Schreibens.
Wenn du es nicht aufrufen kannst, kannst du es nicht benutzen. Die Leaderboard-Position ist eine Information über Ausgabequalität, nicht über Verfügbarkeit.
Audioleistung verändert die Kalkulation
Wenn dein Workflow Audio erfordert — Voiceover, Umgebungsgeräusche, Lippensynchronisation — verschwindet HappyHorses Vorsprung im Wesentlichen. Der Abstand zwischen ihm und Seedance 2.0 in den Mit-Audio-Kategorien beträgt 5 Punkte bei T2V und 2 Punkte bei I2V. Das sind Unentschieden innerhalb normaler Elo-Varianz.
Für Audio-erforderliche Anwendungsfälle sieht das praktische Feld gerade wie ein Seedance/HappyHorse-Unentschieden an der Spitze aus, mit SkyReels V4 einen bedeutsamen Schritt darunter.
Team-Verantwortlichkeit: unbekannt
Artificial Analysis beschrieb HappyHorse als „pseudonym”, als es das Modell zur Arena hinzufügte. Eine Reihe von Seiten, die mit dem Modell verbunden sind, behauptet, es wurde vom Future Life Lab-Team bei Taotian Group (Alibaba) gebaut, geleitet von Zhang Di, dem ehemaligen Leiter von Kling AI. Eine andere Analyse verband es mit einem Sand.ai-Open-Source-Projekt namens daVinci-MagiHuman, das nahezu identische Spezifikationen teilt. Keines davon wurde offiziell bestätigt.
Bei einem Produktionstool ist Team-Verantwortlichkeit wichtig für Fehlerbehebungen, Modell-Updates und langfristigen Support. Bei pseudonymen Modellen hast du diese Klarheit nicht.
So liest du das Video-Leaderboard als Entwickler
Konkretes Framework, keine Abstraktionen.
Nutze Elo als Qualitätssignal, nicht als Beschaffungsentscheidung. Wenn ein Modell konsequent blinde Vergleiche gegen gut finanzierte Konkurrenten gewinnt, sagt dir das etwas Reales darüber, was es produziert. Das ist es wert, zu bemerken. Es sagt dir nichts über API-Bedingungen, Preisgestaltung, Latenz oder ob das Team auf Fehlermeldungen reagiert.
Das praktische Leaderboard beginnt bei #3. Die zwei Modelle mit der höchsten Qualität nach Elo — HappyHorse und Seedance 2.0 — sind beide über öffentliche API nicht zugänglich. Die nächste Stufe — SkyReels V4, Kling 3.0, PixVerse V6 — ist, wo tatsächliche Integrationsentscheidungen gerade getroffen werden.
Wann man früh bei einem neuen Leaderboard-Neuling handeln sollte. Wenn ein Modell mit einem bedeutsamen Elo-Abstand an der Spitze steht, ein verifiziertes GitHub-Release hat und Dokumentation existiert — sofort testen. Wenn es an der Spitze steht, aber GitHub „Demnächst verfügbar” sagt — erinnere dich in zwei Wochen, es zu prüfen. Strukturiere keine Pipeline um Dampf herum um.
Überprüfe das Live-Leaderboard direkt, nicht Artikel. Inklusive diesem hier. Elo-Werte bewegen sich täglich. Die Zahlen, die ich hier referenziert habe, spiegeln Anfang April 2026 wider und werden sich verschoben haben, wenn du das liest.
FAQ
Wie lange ist HappyHorse-1.0 schon auf dem Artificial Analysis Leaderboard?
Artificial Analysis gab es am 7. April 2026 bekannt und beschrieb es als neu hinzugefügtes pseudonymes Modell. Zum Zeitpunkt dieses Schreibens ist es seit etwa 48 Stunden live und Stimmzahlen akkumulieren sich noch.
Kann ein Modell auf Elo unbegrenzt #1 bleiben?
Normalerweise nicht. Mit dem Eintritt neuerer Modelle in die Arena und der Ansammlung weiterer Stimmen verschieben sich die Rankings. Ein Modell, das am zweiten Tag mit einer kleinen Stichprobe dominiert, kann sich niedriger stabilisieren, wenn der Stimmpool tiefer wird. Der Wert ist immer live — er spiegelt aktuelle Daten wider, kein dauerhaftes Urteil.
Verifiziert Artificial Analysis, wer Modelle zur Arena einreicht?
Artificial Analysis hat keine formale Verifizierungsrichtlinie für Modell-Einreichungen veröffentlicht. Sie beschrieben HappyHorse-1.0 als „pseudonym”, als sie es ankündigten, was darauf hindeutet, dass die Identität des Teams ihnen bekannt ist, aber nicht öffentlich offengelegt wird. Ob sie ein technisches Audit eingereichte Modelle durchführen, ist nicht dokumentiert.
Sollte ich ein Modell allein auf Basis des Elo-Werts wählen?
Nein. Elo sagt dir etwas über visuelle Präferenz in blinden Vergleichen. Es sagt nichts über API-Verfügbarkeit, Kosten pro Generierung, Latenz, Verfügbarkeit, Inhaltsrichtlinie oder ob das Modell in drei Monaten noch existiert. Es ist ein Signal unter mehreren.
Welche anderen Metriken sind neben Leaderboard-Rankings wichtig?
API-Zugang und Dokumentation; Preisgestaltung pro Generierung oder pro Minute; Latenz und Cold-Start-Verhalten bei deiner Nutzungsfrequenz; Stimmzahl hinter dem Elo-Wert (mehr Stimmen = stabiler); und ob das Team eine Erfolgsbilanz bei der Wartung und Aktualisierung des Modells hat. Die WaveSpeed-Modellvergleichsseite verfolgt mehrere dieser Dimensionen über zugängliche Modelle hinweg, wenn du einen Ausgangspunkt möchtest.
So steht es derzeit. Ein Modell mit einem unbekannten Team und ohne öffentliche Gewichte hat soeben den glaubwürdigsten Video-Benchmark übernommen, den wir haben — mit einem Vorsprung, der schwer zu ignorieren ist. Ob es zu einer echten Produktionsoption wird, hängt vollständig davon ab, was in den nächsten Wochen veröffentlicht wird.
Es lohnt sich, es im Auge zu behalten. Es lohnt sich noch nicht, darauf zu handeln.
Mehr folgt.
Probiere HappyHorse-1.0 auf WaveSpeedAI aus
HappyHorse-1.0 ist jetzt auf WaveSpeedAI verfügbar:
Vorherige Beiträge:
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt
GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing
GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten
MAI-Image-2.5 API: Was Entwickler wissen sollten