Was ist SkyReels V4? Das erste vereinheitlichte Video-Audio-KI-Modell erklärt
SkyReels V4 ist die erste Open-Source-KI, die Video und Audio gemeinsam generiert – in 1080p/32FPS. Hier erfahren Sie, was es kann, wie es funktioniert und warum es wichtig ist.

Hallo, ich bin Dora. An jenem Tag habe ich mein erstes **SkyReels V4**-Video generiert. Fünfzehn Sekunden einer Katze, die in der Abenddämmerung durch eine regengetränkte Gasse läuft. Das Video sah gut aus – 1080p, fließende Bewegung, schöne Beleuchtung. Aber was mich innehalten ließ, war der Ton. Schritte, die in Pfützen spritzen. Ferner Verkehr. Das leise Echo der Gassenwände. All das wurde gemeinsam generiert, perfekt synchronisiert, ohne dass ich auch nur ein einziges Audiobearbeitungstool angerührt hatte.
Das war der Teil, der sich anders anfühlte.
Das Problem, das jedes Video-KI-Tool vor V4 hatte
Warum reine Videogenerierung sich immer unvollständig anfühlte
Die meisten Video-KI-Tools generieren stumme Clips. Runway, Pika, sogar die früheren SkyReels-Versionen – sie erzeugen Bilder und hören dort auf. Man bekommt eine wunderschöne 10-Sekunden-Aufnahme von Wellen, die an einem Strand brechen, aber sie ist völlig lautlos. Die Wellen brechen nicht hörbar. Der Wind weht nicht. Es gibt überhaupt keinen Umgebungsklang.
Das ist keine technische Unachtsamkeit. Synchronisierten Ton zusammen mit Video zu generieren ist wirklich schwierig. Der Ton muss nicht nur zur allgemeinen Szene passen, sondern zu spezifischen visuellen Ereignissen – Schritte, die landen, wenn Füße den Boden berühren, Türen, die schließen, wenn sie zuschwingen, Stimmen, die sich mit Lippenbewegungen synchronisieren.
Der „Audio in der Nachbearbeitung hinzufügen”-Engpass
Der Standardworkflow wurde zu: Video generieren, exportieren, einen Audio-Editor öffnen, Soundeffekte oder Musik manuell hinzufügen, alles von Hand synchronisieren, erneut exportieren. Für einen 15-Sekunden-Clip konnte das 20–30 Minuten dauern.
Letzten Monat habe ich das mit Pika-Outputs ausprobiert. Das Video sah professionell aus. Aber die richtigen Umgebungsgeräusche zu finden, sie zeitlich auf visuelle Hinweise abzustimmen und das offensichtlich nachträglich hinzugefügte Gefühl zu vermeiden, kostete mehr Zeit als die eigentliche Videogenerierung. Der Workflow fühlte sich kaputt an – wie ein Auto zu kaufen, aber den Motor separat einbauen zu müssen.
Was SkyReels V4 eigentlich ist
Entwickelt von SkyworkAI (die V1/V2/V3-Linie erklärt)
SkyworkAI veröffentlichte SkyReels V1 Anfang 2025 als einfaches Text-zu-Video-Modell. V2 folgte mit Diffusion-Forcing-Architektur, die durch autoregressive Sequenzen eine unbegrenzte Generierungslänge ermöglichte. V3 wurde im Januar 2026 gestartet mit multimodalem In-Context-Learning – man konnte Referenzbilder, Audioclips oder vorhandene Videos einspeisen, und es würde kohärente Fortsetzungen generieren.

V4, das am 25. Februar 2026 live ging, stellt einen anderen Sprung dar. Während V3 Funktionen hinzufügte, hat V4 die gesamte Architektur um ein Dual-Stream-System herum neu strukturiert, das Video und Audio gleichzeitig generiert.
Was „unified video-audio foundation model” wirklich bedeutet
Das technische Paper beschreibt V4 als einen Multimodal Diffusion Transformer (MMDiT) mit zwei parallelen Zweigen. Ein Zweig synthetisiert Videoframes. Der andere generiert zeitlich ausgerichtetes Audio. Beide Zweige teilen einen Textencoder, der auf multimodalen großen Sprachmodellen basiert, was bedeutet, dass sie dasselbe semantische Verständnis des Prompts verarbeiten und während der gesamten Generierung synchron bleiben.
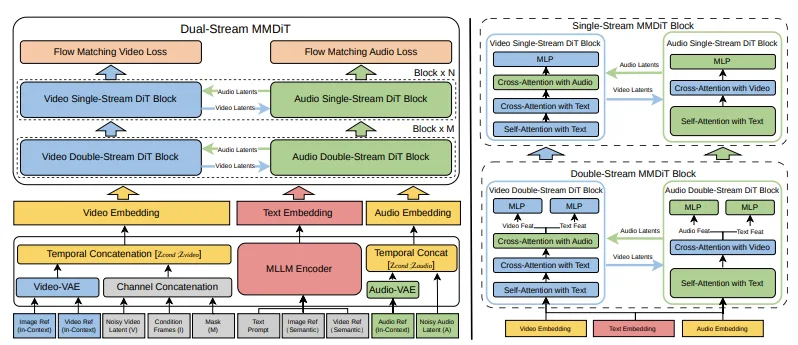
Das ist keine Videogenerierung mit nachträglich hinzugefügtem Ton. Es ist ein einziges Modell, das Bild und Ton als gleich wichtige Ausgaben behandelt, die gemeinsam aus demselben latenten Verständnis der Szene generiert werden.
In der Praxis bedeutet das: Wenn man „eine Frau, die an einem Rednerpult spricht” eingibt, generiert das Modell sowohl das Bild ihrer sich bewegenden Lippen als auch das tatsächliche Sprachaudio, auf Frame-Ebene synchronisiert. Wenn man „starker Regen auf einem Metalldach” generiert, erhält man sowohl das Bild von Regen, der herabläuft, als auch das charakteristische metallische Trommelgeräusch – nicht annähernd abgestimmt, sondern als einheitliches audiovisuelles Ereignis generiert.
Wesentliche Fähigkeiten auf einen Blick
Gemeinsame Video- + Audiogenerierung aus einem Prompt
Einzelprompt-Generierung ist die Kernfähigkeit. Man schreibt „Donner, der über eine Wüstenlandschaft rollt”, und V4 produziert 15 Sekunden, in denen sich Wolken zusammenziehen, Blitze aufleuchten und synchrones Donnergrollen erschallt, das zum visuellen Timing passt. Kein separater Audiogenerierungsschritt. Keine manuelle Synchronisierungsarbeit.
Ich habe das mit Dialogszenen getestet. Den Prompt „zwei Menschen, die sich in einem belebten Café streiten” eingegeben und nicht nur das Bild des Gesprächs bekommen, sondern auch Hintergrundgeplapper, klirrendes Geschirr und die Stimmen der Sprecher, die mit der Intensität ihrer Gesten stiegen und fielen. Die Lippensynchronisation war nicht perfekt – ich bemerkte einige Momente, wo das Timing leicht abwich – aber sie war besser als alles, was ich manuell synchronisiert hatte.
1080p / 32FPS / 15-Sekunden-Ausgabe
Technische Spezifikationen: bis zu 1080p-Auflösung, 32 Frames pro Sekunde, maximale Dauer von 15 Sekunden. Zum Vergleich: Die meisten konkurrierenden Tools haben eine Obergrenze von 720p oder benötigen deutlich längere Generierungszeiten für HD-Ausgabe.
Das 15-Sekunden-Limit ist wichtiger als es klingt. Die meisten Social-Media-Inhalte leben in 10–15-Sekunden-Blöcken. YouTube Shorts ist auf 60 Sekunden begrenzt. Instagram Reels auf 90. Für diesen Anwendungsfall sind 15 Sekunden mit synchronisiertem Ton nützlicher als 30 Sekunden stilles Video, das Nachbearbeitung erfordert.
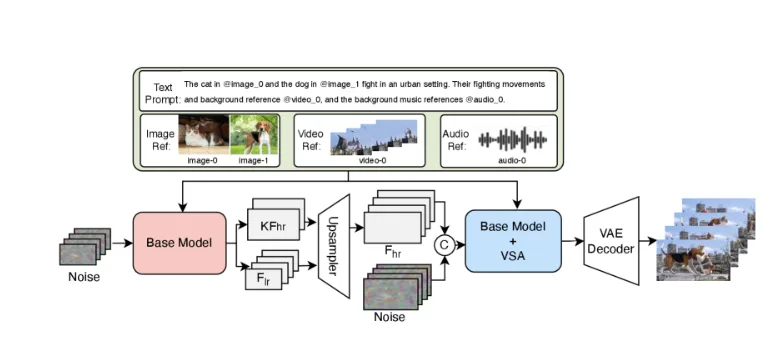
Multimodale Eingaben: Text, Bild, Video, Maske, Audioreferenz
V4 akzeptiert fünf Eingabetypen: Textprompts, Referenzbilder, Videoclips, binäre Masken für Inpainting und Audioreferenzen. Man kann sie kombinieren – ein Bild einer bestimmten Person hochladen, eine Audioaufnahme von Schritten auf Kies bereitstellen und „durch einen Wald bei Tagesanbruch gehen” eingeben. Das Modell nutzt alle drei Eingaben zur Steuerung der Generierung.
Ich habe multimodales Prompting mit einem Referenzbild eines bestimmten Architekturstils und einem Audioclip von Straßenambiente getestet. Das generierte Video behielt die architektonischen Details aus dem Bild bei und schichtete gleichzeitig die Umgebungsgeräusche aus der Audioreferenz ein. Nicht perfekt – einige Audioelemente wirkten generisch – aber die Funktion hat funktioniert.
Drei Aufgaben in einer: Generieren, Inpainting, Bearbeiten
Über die Generierung hinaus übernimmt V4 Inpainting und Bearbeitung durch Channel Concatenation. Man gibt ein Video und eine Maske an, die zeigt, welche Bereiche geändert werden sollen, und das Modell regeneriert nur diese Bereiche, während der Rest erhalten bleibt. Dies ermöglicht Aufgaben wie das Entfernen von Objekten, das Ändern von Hintergründen oder das Ersetzen bestimmter Elemente, ohne den gesamten Clip neu zu generieren.
Wie V4 mit dem Vorherigen verglichen werden kann
V4 vs. SkyReels V1/V2/V3-Evolution
V1 war nur Text-zu-Video. V2 fügte Länge durch Diffusion Forcing hinzu. V3 führte multimodale Eingaben ein, generierte aber noch Video ohne nativen Ton. V4 ist das erste Modell, das Audio als erstklassige Ausgabe behandelt, die gleichzeitig mit dem Video generiert wird.
Wer SkyReels V4 im Auge behalten sollte

Content-Creator und Filmemacher
Jeder, der Kurzinhalte für Social-Media-Plattformen produziert, profitiert sofort. Die Workflow-Komprimierung – vom Prompt zum fertigen audiovisuellen Clip – beseitigt den Engpass, der KI-Video-Tools so anfühlen ließ, als würden sie mehr Arbeit schaffen als einsparen.
Ich beobachtete, wie ein befreundeter Filmemacher V4 nutzte, um B-Roll für eine Dokumentation zu generieren. Prompts wie „Zeitraffer von Stadtlichtern, die in der Abenddämmerung aufgehen” oder „Nahaufnahme von Regen auf Fensterglas” mit passenden Umgebungsgeräuschen. Die Ergebnisse waren nicht von echtem Filmmaterial zu unterscheiden, aber sie waren gut genug für Hintergrundaufnahmen, und sie waren in jeweils unter 60 Sekunden fertig, anstatt Drehorte oder Stockmaterial-Lizenzen zu erfordern.
Entwickler, die Video-Pipelines bauen
Wenn man Anwendungen entwickelt, die Video generieren oder bearbeiten, vereinfacht V4s einheitliche Schnittstelle für Generierung, Inpainting und Bearbeitung den Stack. Anstatt separate Modelle für Videogenerierung, Audiosynthese und Synchronkorrektur zu verketten, übernimmt ein einziger API-Aufruf den gesamten Ablauf.
Die Modellarchitektur ist detailliert dokumentiert, und SkyworkAI hat eine Geschichte der Open-Source-Veröffentlichung früherer Versionen, was darauf hindeutet, dass der Entwicklerzugang erweitert wird. V3-Gewichte sind bereits auf Hugging Face und GitHub verfügbar.
Aktueller Zugangsstatus & Was kommt
Stand 2. März 2026 befindet sich V4 in einer begrenzten Vorschau. Die offizielle Website bietet ein kostenloses Kontingent mit täglichen Generierungslimits, aber noch keinen API-Zugang. Basierend auf V3s Zeitplan – der vom Paper-Release bis zur öffentlichen API etwa zwei Wochen dauerte – würde ich eine breitere Verfügbarkeit bis Mitte März erwarten.
Das technische Paper merkt an, dass zukünftige Arbeiten die Erweiterung über 15 Sekunden hinaus und die Verbesserung der feingranularen Audiosteuerung umfassen. Diese Einschränkungen fühlen sich gerade jetzt bedeutend an, besonders die Dauerbegrenzung. Aber für das spezifische Problem, das V4 löst – das Generieren kurzer, synchronisierter audiovisueller Clips ohne Nachbearbeitung – funktioniert es besser als alles andere, das ich getestet habe.
Ich habe V4 seit diesem ersten Test in meinem Workflow behalten. Nicht für alles – es gibt noch Aufgaben, bei denen gefilmtes Material oder Stockvideo mehr Sinn ergibt. Aber für schnelle B-Roll-Aufnahmen, Umgebungsszenen oder Social-Media-Snippets, bei denen synchronisierter Ton wichtig ist, hat V4 genug Reibung beseitigt, dass ich jetzt zuerst danach greife.
Die einheitliche Architektur fühlt sich weniger wie eine inkrementelle Funktion an und mehr wie die Behebung von etwas, das von Anfang an so hätte funktionieren sollen.
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt
GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing
GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten
MAI-Image-2.5 API: Was Entwickler wissen sollten