WAN 2.7 Erstes & Letztes Bild Steuern: Builder-Leitfaden
So nutzen Sie WAN 2.7's Steuerung für erstes und letztes Bild zur vorhersehbaren Videogenerierung — Eingabevorbereitung, API-Parameter und Tipps für den Produktions-Workflow.

Hey, Leute, Dora kommt. Immer wieder beschrieben Teams die First/Last-Frame-Steuerung als „man lädt einfach zwei Bilder hoch.” Das ist so, als würde man asynchrone Job-Queues beschreiben als „man wartet einfach.” Die Mechanik ist nicht schwer – aber die Entscheidungen beim Input-Design sind der Bereich, in dem die meisten Produktions-Workflows stillschweigend scheitern.
Dieser Leitfaden richtet sich an Entwickler, die reproduzierbare Ergebnisse brauchen – nicht nur eine Demo, die einmal funktioniert hat.
Was First-Frame- & Last-Frame-Steuerung wirklich macht
Das Problem, das sie löst – im Vergleich zu Standard-I2V
Standard Image-to-Video (I2V) verankert den Eröffnungsframe und lässt das Modell dann improvisieren. Das Ergebnis ist das, was die Community oft als „Drift” bezeichnet – Motiv, Kameraposition oder Beleuchtung weichen schrittweise von einem angestrebten Zielzustand ab. Für Produkt-Demos oder narrative Sequenzen mit einem vorgeschriebenen Endpunkt ist das in der Nachbearbeitung teuer zu korrigieren.
WANs FLF2V-Ansatz verwendet einen zusätzlichen Steuerungsanpassungsmechanismus: First- und Last-Frame werden als Steuerbedingungen behandelt, und semantische Merkmale beider Bilder werden in den Generierungsprozess eingespeist. Dadurch bleiben Stil, Inhalt und Struktur konsistent, während das Modell dynamisch zwischen ihnen transformiert.
Wie beide Frames während der Generierung genutzt werden
Das Modell interpoliert nicht einfach Pixelwerte. Es nutzt CLIP-Semantikmerkmale und Cross-Attention-Mechanismen, um das Video stabil zu halten – dieses Design wurde als weniger jitteranfällig im Vergleich zu Single-Anchor-Ansätzen nachgewiesen. Ihr erster Frame definiert den Ausgangszustand; Ihr letzter Frame beschränkt das Ziel. Der Bewegungspfad dazwischen wird erschlossen, nicht vorgegeben – das ist sowohl die Stärke als auch die hauptsächliche Fehlerquelle.
Was das Modell über den Pfad dazwischen erschließt
Ihr Text-Prompt leitet wie der Übergang stattfindet – nicht nur dass er stattfindet. Wenn Ihr Prompt lautet „das Produkt dreht sich langsam und zeigt seine Vorderseite”, formt diese Bewegungsbeschreibung den erschlossenen Pfad. Ohne Prompt wird das Modell trotzdem einen plausiblen Übergang versuchen, aber Sie haben weitaus weniger Kontrolle über Richtungswechsel, Kamerabewegung oder Tempo.
Input-Vorbereitung
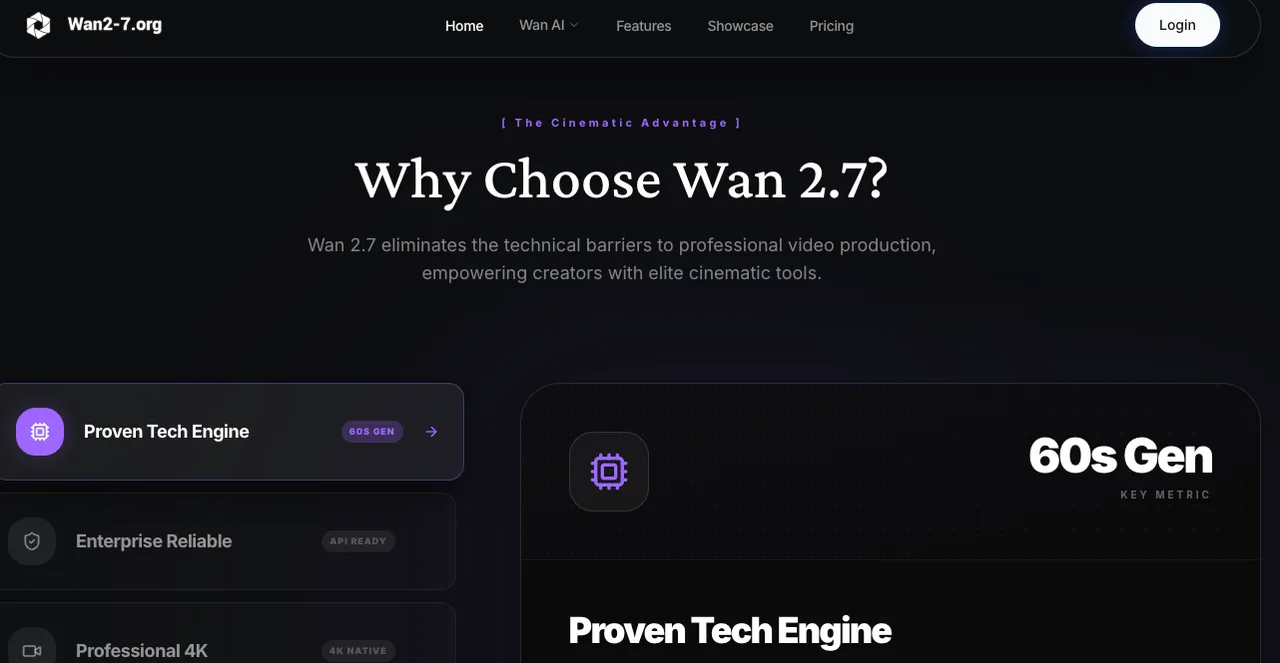
Bild-Spezifikationsanforderungen
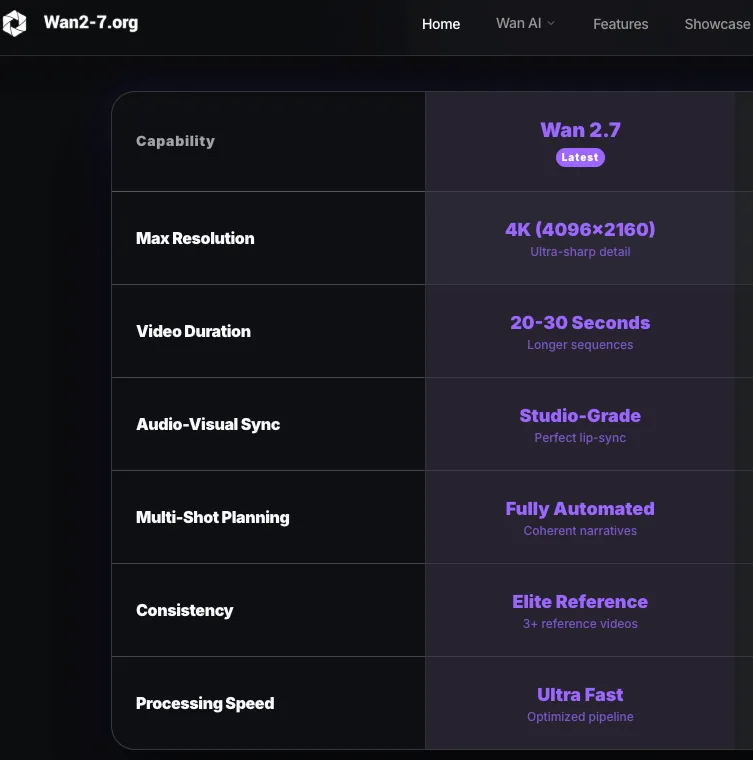
Das Modell verwendet das Seitenverhältnis Ihres ersten Frames so nah wie möglich am Ziel-Output. Für einen 3:4-Input (750×1000) erzeugt eine 720P-Ausgabeeinstellung etwas um 816×1104 – nicht exakt 3:4. Wenn Sie exakte Verhältnisse benötigen, planen Sie das Zuschneiden oder Letterboxing in der Nachbearbeitung ein. Für die WAN-Serie generell ist 720p (1280×720 oder Hochformat-Äquivalent) die empfohlene Auflösung für qualitativ hochwertige Ausgabe; kleinere Auflösungen sind eine valide Strategie für Test-Iterationen, aber nicht für Endprodukte.
Format: PNG oder hochqualitatives JPEG. Vermeiden Sie komprimierte Thumbnails als First/Last-Frames – Komprimierungsartefakte führen Rauschen ein, das das Modell als absichtliche visuelle Information interpretieren muss.
Frame-Paarungs-Strategien, die funktionieren
Die stärksten Paare teilen drei Dinge: konsistente Lichtquellenrichtung, übereinstimmende Tiefenschärfe-Eigenschaften und ein Motiv, das räumlich in beiden Positionen plausibel ist. Eine Produktaufnahme in diffusem Studiolicht, gepaart mit einem Endframe des gleichen Produkts in einem leicht anderen Winkel, funktioniert gut. Ein Packshot zu einem Lifestyle-Hero-Shot funktioniert, wenn das Beleuchtungssetup ähnlich ist.
Denken Sie für narrative Sequenzen bei dem Paar als Definition eines Verbs: offen → geschlossen, vorher → nachher, zusammenbauen → fertig. Je klarer die semantische Beziehung, desto kohärenter der erschlossene Pfad.
Was ein schlechtes Frame-Paar ausmacht
Drei häufige Übeltäter:
Inkonsistente Beleuchtungsrichtung. Wenn Ihr erster Frame das Hauptlicht bei 45° links hat und Ihr letzter Frame mit Oberlicht aufgenommen wurde, wird das Modell versuchen, zwischen zwei verschiedenen Schattenumgebungen zu übergehen. Das Ergebnis ist meist ein Lichtquellen-Sprung in der Clip-Mitte, der wie ein Render-Fehler aussieht.
Räumliche Diskrepanz. Eine breite Einstellungsaufnahme, gepaart mit einer engen Nahaufnahme, zwingt das Modell dazu, eine Kamerabewegung zu erfinden. Manchmal ist das beabsichtigt; meistens nicht. Halten Sie die Brennweite ungefähr konsistent, es sei denn, Sie prompten explizit für einen Zoom oder Pull.
Widersprüchliche Tiefenhinweise. Bokeh im ersten Frame, alles scharf im letzten – das Modell wird dies als Tiefenschärfe-Änderung interpretieren und versuchen, sie zu animieren. Das ist nicht immer falsch, aber selten beabsichtigt.
API-Implementierung
Das Folgende spiegelt das dokumentierte FLF2V-Muster für die WAN-Serie wider. Überprüfen Sie aktuelle Parameternamen und Endpunkt-Pfade in der Alibaba Cloud Model Studio Dokumentation vor dem Produktionseinsatz. WAN 2.7 API-Spezifika sollten beim Launch bestätigt werden.
Payload-Struktur
Das Kernmuster umfasst zwei Bild-Inputs – einer über öffentliche URL oder lokalen Dateipfad – übergeben als first_frame_url und last_frame_url, zusammen mit einem Text-Prompt und einer Auflösungseinstellung.
Python-Request-Muster (Pseudocode)
# Modellnamen und Endpunkt beim Launch verifizieren — Namen ändern sich über Versionen
import os
from dashscope import VideoSynthesis
response = VideoSynthesis.async_call(
model="wan2.x-flf2v-<beim-launch-verifizieren>", # exakten Modell-String bestätigen
first_frame_url="https://your-cdn.com/start.png",
last_frame_url="https://your-cdn.com/end.png",
prompt="Feste Kamera. Beginne mit erstem Bild, ende beim letzten Bild. [Bewegung beschreiben]",
negative_prompt="flicker, warping, blur",
resolution="720P", # akzeptierte Werte verifizieren
# seed-Parameter: einmal sperren, wenn Sie ein gutes Ergebnis haben
)
task_id = response.output.task_idAsync-Handling für längere Jobs
Image-to-Video-Generierungsaufgaben laufen typischerweise 1–5 Minuten. Die API verwendet ein zweistufiges Async-Muster: Aufgabe einreichen, Task-ID erhalten, dann auf das Ergebnis pollen. Bauen Sie Polling von Anfang an in Ihre Pipeline ein. Gehen Sie nicht von synchronem Verhalten auch bei Test-Aufrufen aus – Timeouts lassen Ergebnisse in naiven Implementierungen stillschweigend fallen.
Produktions-Workflow: Entwurf-zu-Final-Methode
Schritt 1 – Referenzpaar erstellen und Test durchführen
Beginnen Sie mit einem einzelnen Paar. Führen Sie kein Batch-Processing durch, bis Sie ein Ergebnis von Anfang bis Ende gesehen haben. Verwenden Sie Ihre Zielinhalte – keine Platzhalter-Stockbilder – da räumliche und Beleuchtungseigenschaften Ihre tatsächliche Asset-Bibliothek repräsentieren müssen.
Schritt 2 – Bewegungspfad vor dem Batch validieren
Schauen Sie den vollständigen Clip einmal mit 0,5-facher Geschwindigkeit an. Achten Sie auf: Jitter in der Clip-Mitte, Motiv-Identitätsdrift um Frame 50–70% des Clips (hier konzentrieren sich die meisten Artefakte) und Beleuchtungsunterbrechungen. Wenn Sie eines davon sehen, korrigieren Sie das Input-Paar, bevor Sie den Prompt anfassen.
Schritt 3 – Besten Seed für Konsistenz sperren
Sobald Sie ein sauberes Ergebnis haben, notieren Sie den Seed-Wert. Das FLF2V-Modell akzeptiert einen optionalen Prompt zur Steuerung der Zwischen-Aktion und Transformationslogik. Ein gesperrter Seed plus ein gesperrter Prompt gibt Ihnen eine reproduzierbare Generierungseinheit, die Sie auf ähnliche Input-Paare anwenden können. Das macht die Batch-Produktion vorhersehbar statt probabilistisch.
Schritt 4 – Auf Batch-Generierung skalieren
Strukturieren Sie Ihren Batch als: ein kanonisches „Testpaar”, das als Qualitätsanker dient, dann Varianten-Paare, die aus demselben kontrollierten Aufnahme-Setup generiert werden. Die Hugging Face Modellseite für WAN FLF2V dokumentiert die Open-Weight-Version für Teams, die lokale Inferenz neben API-Aufrufen betreiben.
Wo diese Funktion passt (und wo nicht)
Am besten geeignet für: Produkt-Demo-Sequenzen, bei denen der Endpunkt wichtig ist (Packshot → Feature-Reveal), narrative Kontinuitätsaufnahmen mit einem definierten Vorher/Nachher, kontrollierte Kamerapfade, bei denen Sie räumliche Stabilität über mehrere Clips in einer Serie benötigen.
Nicht ideal für: stark dynamische Bewegungen mit scharfen Richtungswechseln (das Modell glättet diese aus und verliert dabei oft die Dramatik), mehrdeutige räumliche Übergänge, bei denen First- und Last-Frame keine klare semantische Beziehung teilen, oder Szenarien, die frame-genaues Timing erfordern – das Modell kontrolliert das Tempo, nicht Sie.
Häufige Fehlermuster & Korrekturen
Bewegungsartefakt in der Clip-Mitte. Wird normalerweise durch eine räumliche Diskrepanz im Input-Paar verursacht. Das Modell „committet” früh auf einen Interpolationspfad, und die Inkonsistenz zeigt sich um die Mitte. Korrektur: Beziehung zwischen Frames straffen, bevor der Prompt geändert wird.
Frame-Stil-Inkonsistenz. Wenn Ihr erster Frame ein stilisiertes Render ist und Ihr letzter eine Fotografie, wird das Modell versuchen, die visuellen Stile zu mischen. Das produziert selten saubere Ergebnisse. Passen Sie die Bildbehandlung an – beide Renders, beide Fotos, beide Illustrationen.
Modell ignoriert den letzten Frame. Das passiert, wenn der Prompt eine Bewegung beschreibt, die logischerweise nicht an Ihrem letzten Frame enden kann. Das Modell priorisiert Prompt-Kohärenz gegenüber Frame-Adhärenz, wenn sie in Konflikt geraten. Schreiben Sie Ihren Prompt so, dass er am letzten Frame ankommt, nicht nur vom ersten abweicht.
FAQ
- Kann ich First/Last-Frame mit Text-to-Video verwenden oder nur mit I2V? Der FLF2V-Modus ist eine Erweiterung von I2V. Beide Frame-Inputs sind erforderlich. Standard-T2V akzeptiert keine End-Frame-Beschränkungen per Design.
- Welches Bildformat funktioniert am besten für Frame-Inputs? PNG für alles, was saubere Kanten oder Transparenz-Handling erfordert. Hochqualitatives JPEG (>90 Qualität) ist für Fotografie in Ordnung. Vermeiden Sie WebP, wenn Ihre Plattform die Unterstützung nicht bestätigt hat.
- Kostet das mehr als Standard-I2V? Die Preisgestaltung ist auflösungsabhängig – 720p kostet pro Generierung ungefähr doppelt so viel wie 480p. FLF2V selbst trägt kein separates Premium in der dokumentierten Preisgestaltung, aber bestätigen Sie dies mit Ihrer spezifischen Plattform.
- Wie gehe ich mit Bewegungen um, die scharfe Richtungswechsel erfordern? Teilen Sie die Sequenz in mehrere Clips mit Zwischen-Frames als Endpunkte auf. Verketten Sie sie in der Nachbearbeitung, anstatt zu versuchen, eine einzelne Generierung diskontinuierliche Bewegung handhaben zu lassen.
- Kann ich dies mit dem 9-Grid-Input-Modus kombinieren? Das sind separate Input-Modi. WAN 2.7 unterstützt First/Last-Frame-Steuerung und 9-Grid Image-to-Video als unterschiedliche Features. Sie werden derzeit nicht in einem einzigen Aufruf kombiniert – verifizieren Sie beim Launch, ob sich das ändert.
Fazit
Der interessante Design-Raum bei der First/Last-Frame-Steuerung ist nicht der API-Aufruf – es ist das Input-Paar. Dort liegt der echte Produktionshebel, und dort investieren die meisten Teams zu wenig. Ein gut gestaltetes Frame-Paar mit einer klaren semantischen Beziehung wird konsistent besser abschneiden als ein perfekter Prompt, der mit einem nicht übereinstimmenden Input gepaart ist.
Für Teams, die Batch-Pipelines entwickeln: Behandeln Sie Ihre Input-Paar-Bibliothek als erstklassiges Asset, nicht als Nachgedanken. Sobald Sie einen gesperrten Seed und ein validiertes Paar-Format haben, wird die Generierungsseite zur Routine. Die ComfyUI-Community hat WAN FLF2V Workflow-Konfigurationen im Detail dokumentiert, wenn Sie auch lokale Inferenz neben API-Aufrufen betreiben – lesenswert für den Einblick auf Node-Ebene, wie Frame-Conditioning tatsächlich funktioniert.
Ich komme immer wieder zu etwas Stillem hier zurück: Die Einschränkung ist das Feature. Dem Modell ein Ziel zu geben, zwingt Sie dazu, präzise zu sein, was Sie tatsächlich wollen. Das ist keine Einschränkung – es ist eine Disziplin, die tendenziell bessere Ergebnisse produziert als offene Generierung es je tut.
KI-Video-Workflows weiter erkunden:
- Vergleichen Sie First/Last-Frame-Steuerung mit anderen Video-Generierungsmodellen
- Verstehen Sie, wie man Charakterkonsistenz über generierte Video-Clips hinweg aufrecht erhält
- Erkunden Sie reale Anwendungsfälle für KI-Videogenerierung in Produktions-Workflows
- Erfahren Sie, wie Multi-Bild-Referenz-Inputs die Generierungskontrolle verbessern
- Sehen Sie, wie Image-to-Video-Pipelines über verschiedene Tools hinweg verwendet werden
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt
GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing
GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten
MAI-Image-2.5 API: Was Entwickler wissen sollten