Muse Spark vs. Llama 4: Metas strategischer Wandel
Meta wechselte von Open-Weight-Llama zu geschlossenem Muse Spark. Was sich geändert hat, warum das für Entwickler wichtig ist und ob zukünftige Open-Source-Versionen realistisch sind.

Meta hat gerade eine neue Modellserie veröffentlicht. Wenn du in den letzten Monaten etwas auf Llama 4 aufgebaut hast, fragst du dich wahrscheinlich, ob du weitermachen oder mit der Planung einer Migration beginnen solltest.
Ich bin Dora. Ich habe gestern jeden veröffentlichten Dokumentationsartikel von Meta gelesen, Drittanbieter-Benchmarks gegenübergestellt und versucht herauszufinden, was das tatsächlich für Menschen mit Llama im Stack bedeutet. Dieser Beitrag erklärt, was sich geändert hat, was gleich geblieben ist und wo Entwickler gerade stehen.
Was sich zwischen Llama 4 und Muse Spark verändert hat
Architektur: Neun Monate, von Grund auf neu
Meta Superintelligence Labs – die Einheit, die nach Alexandr Wangs Einstieg als Chief AI Officer Mitte 2025 gegründet wurde – hat den gesamten KI-Stack von Grund auf neu aufgebaut. Neue Infrastruktur, neue Architektur, neue Datenpipelines. Das ist kein Marketingtext; das ist was Metas eigener technischer Blog beschreibt. Muse Spark ist das erste Modell aus diesem Neuaufbau.
Llama 4 verwendete eine Mixture-of-Experts-Architektur mit offenen Gewichten. Muse Spark ist ein nativ multimodales Reasoning-Modell – das bedeutet, dass Vision nicht nachträglich hinzugefügt wurde, sondern von Anfang an integriert war. Es unterstützt Tool-Use, visuelles Chain-of-Thought und Multi-Agent-Orchestrierung. Llama 4 hatte keine dieser Fähigkeiten als native Funktionen.
Das Modell führt außerdem abgestufte Reasoning-Modi ein: Instant für einfache Anfragen, Thinking für schrittweise Arbeit und einen Contemplating-Modus, der mehrere Sub-Agenten parallel ausführt. Letzterer ist Metas Antwort auf Gemini Deep Think und GPT Pros erweitertes Reasoning.
Effizienz: Metas Behauptung, keine unabhängige Schlussfolgerung
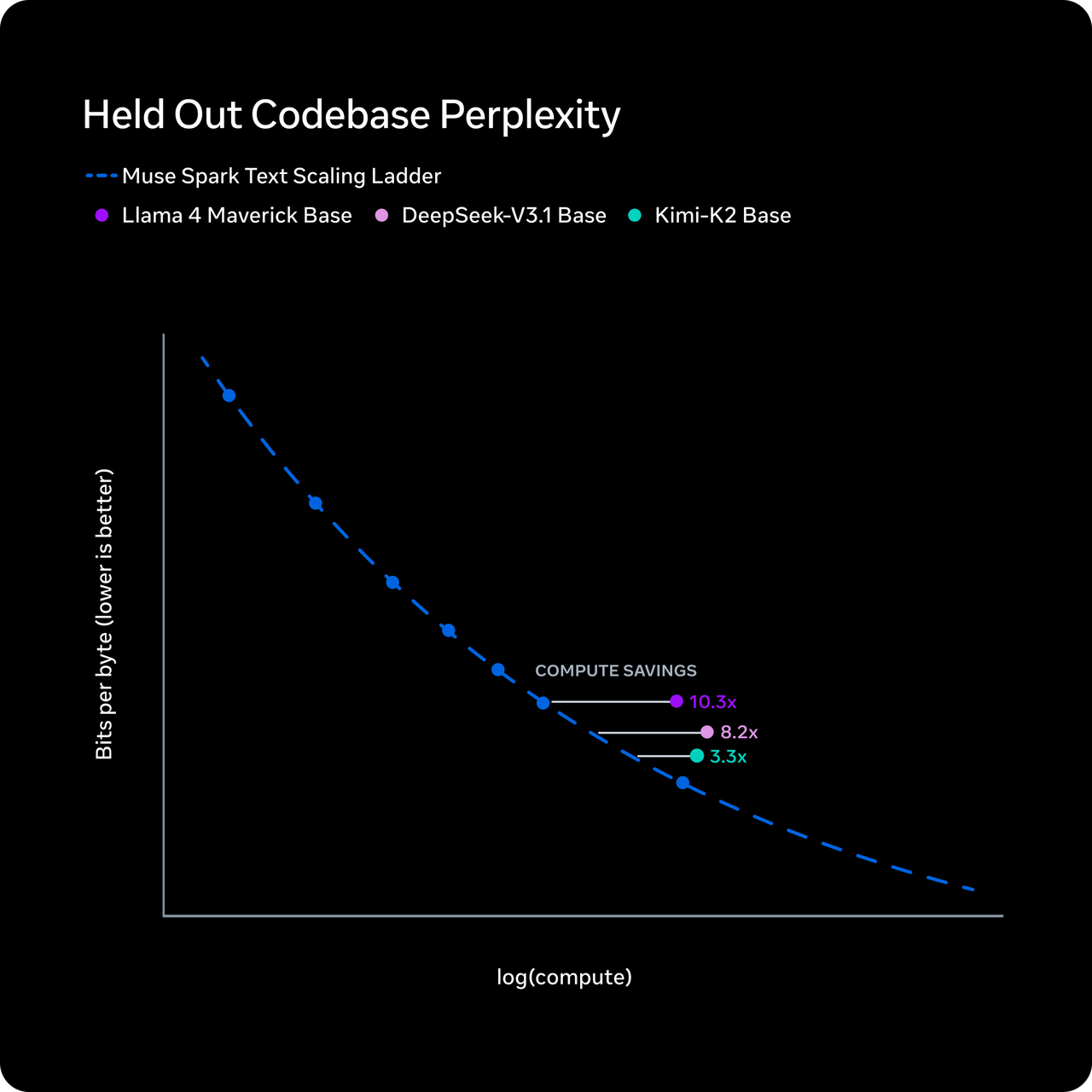
Meta sagt, Muse Spark erreiche das Fähigkeitsniveau von Llama 4 Maverick mit über zehnmal weniger Rechenaufwand. Der beschriebene Mechanismus heißt „Thought Compression” – beim Reinforcement Learning wird das Modell für übermäßige Denkzeit bestraft, was es zwingt, mit weniger Tokens zu schlussfolgern, ohne an Genauigkeit einzubüßen.
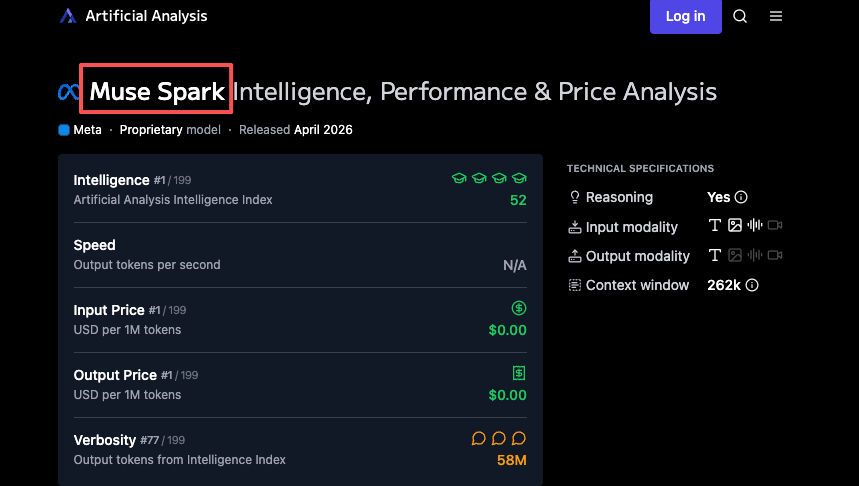
Ich möchte hier präzise sein: Das ist Metas Behauptung. Sie wurde nicht unabhängig repliziert. Die Token-Effizienz-Zahlen von Artificial Analysis zeigen tatsächlich, dass Muse Spark 58 Millionen Output-Tokens verwendet hat, um deren vollständigen Intelligence Index zu durchlaufen – vergleichbar mit Gemini 3.1 Pros 57 Millionen und weit unter Claude Opus 4.6’s 157 Millionen oder GPT-5.4’s 120 Millionen. Die Effizienzgeschichte hat also zumindest auf der Output-Seite eine gewisse unabhängige Bestätigung.
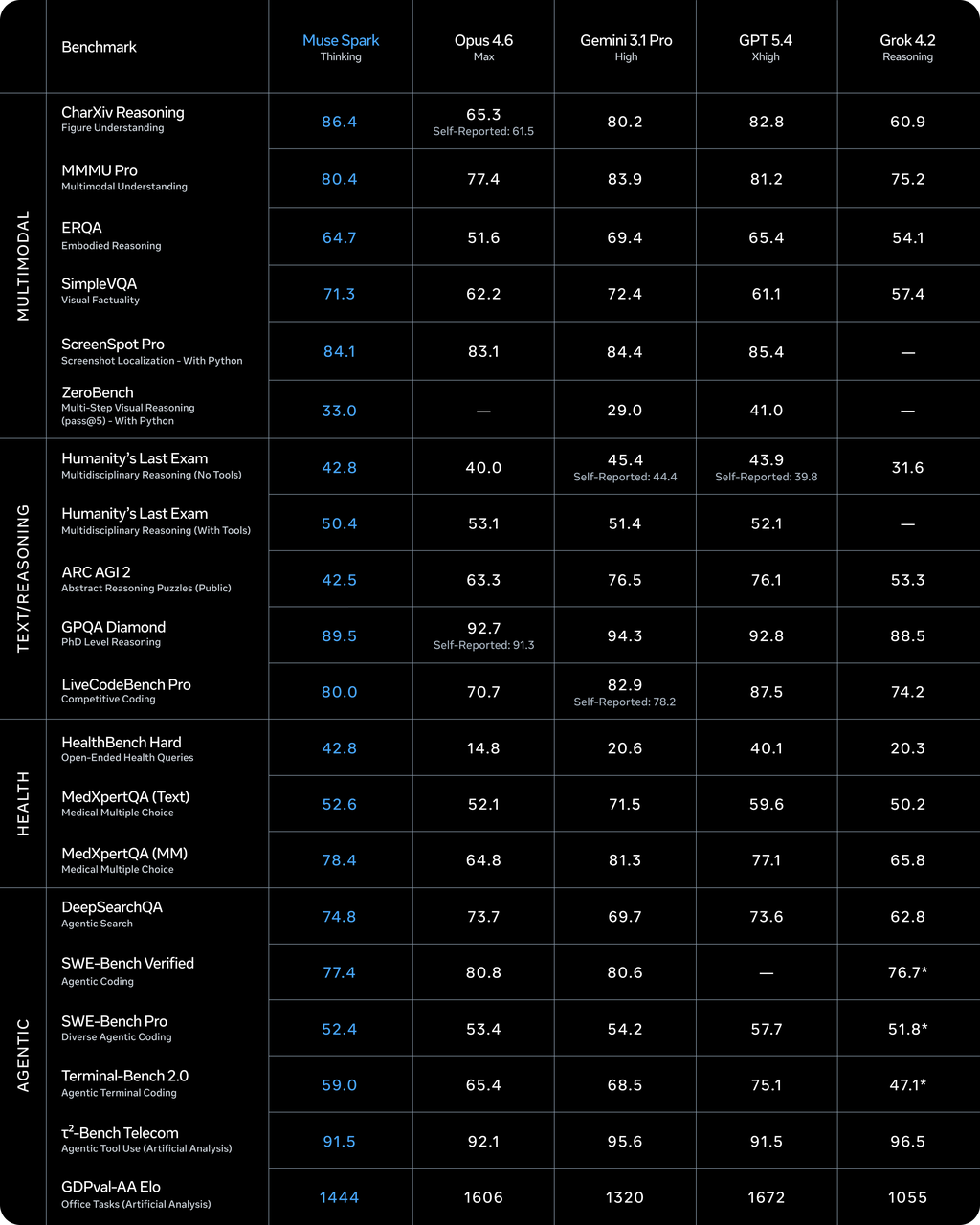
Benchmark-Lücke: 18 zu 52
Laut Artificial Analysis erzielte Llama 4 Maverick beim Launch 18 Punkte auf dem Intelligence Index. Muse Spark erzielte 52. Das setzt es auf Platz vier insgesamt – hinter Gemini 3.1 Pro Preview und GPT-5.4 (beide bei 57) sowie Claude Opus 4.6 (53).
Ein wichtiger Vorbehalt: Artificial Analysis erhielt von Meta frühzeitigen Zugang zur Evaluierung des Modells. Sie führten ihre eigenen Evaluierungen unabhängig durch, aber der Zugang selbst kam über Meta. Das sind noch keine vollständig unabhängigen öffentlichen Benchmarks. Die Ergebnisse sind richtungsweisend nützlich, aber kein Evangelium.
Wo Muse Spark führt: Gesundheits-Benchmarks (42,8 auf HealthBench Hard, vor GPT-5.4’s 40,1), visuelles Reasoning (80,5 % auf MMMU-Pro, nur hinter Gemini 3.1 Pro) und Diagrammverständnis.
Wo es zurückliegt: Coding (Terminal-Bench Hard, hinter Claude Sonnet 4.6 und GPT-5.4), agentische Aufgaben (GDPval-AA 1.427 ELO gegenüber GPT-5.4’s 1.676) und abstraktes Reasoning (ARC-AGI-2 bei 42,5 gegenüber 76+ für Top-Konkurrenten). Meta hat diese Lücken explizit anerkannt in ihrem technischen Blog und erklärt, dass sie weiterhin in „langfristige agentische Systeme und Coding-Workflows” investieren.
Die Verschiebung von offen zu geschlossen
Llamas Modell: Offene Gewichte, Community-Ökosystem
Llamas Wertversprechen war unkompliziert. Gewichte herunterladen, auf eigener Hardware ausführen, für den eigenen Anwendungsfall fein-tunen, nur für Rechenleistung zahlen. Der Open-Weight-Ansatz baute ein Ökosystem auf – Tausende fein-getunte Varianten auf Hugging Face, selbst gehostete Deployments in Startups und Unternehmen, eine ganze Heimindustrie quantisierter Modelle, die auf Consumer-GPUs laufen. Llama 4 Scout passt auf eine einzelne H100. Maverick läuft auf einer RTX 5090 mit Quantisierung.
Dieses Ökosystem existiert noch. Diese Modelle wurden nicht entfernt.
Muse Sparks Modell: Geschlossen, nur private API-Vorschau
Muse Spark ist proprietär. Keine herunterladbaren Gewichte. Kein Self-Hosting. Derzeit betreibt es Meta AI in allen Apps des Unternehmens – die Meta AI-Website und bald WhatsApp, Instagram, Facebook, Messenger und Ray-Ban AI-Brillen. Externe Entwickler können sich für eine private API-Vorschau bewerben. Das war’s.
Das ist restriktiver als die Modelle von OpenAI oder Anthropic, die zumindest öffentlichen API-Zugang bieten. Wie Fortune in ihrer Berichterstattung anmerkte, ist Muse Spark „noch proprietärer als die kostenpflichtigen proprietären Modelle von Metas Konkurrenten.”

„Wir hoffen, zukünftige Versionen als Open Source zu veröffentlichen”
Metas Blogbeitrag enthält diesen Satz. Zuckerberg schrieb auf Threads über Pläne, „zunehmend fortschrittliche Modelle zu veröffentlichen, die die Frontier der Intelligenz und Fähigkeiten voranbringen, einschließlich neuer Open-Source-Modelle.” Wang erwähnte auf X die Open-Sourcing zukünftiger Versionen.
Kein Zeitplan. Keine konkrete Zusage über welches Modell oder wann. Kein Hinweis, ob „zukünftige Versionen” bedeutet, dass Muse Spark selbst irgendwann geöffnet wird, oder ob ein separater Open-Weight-Zweig parallel weiterläuft.
Vergleiche das mit Zuckerbergs Manifest von 2024 mit dem Titel „Open Source AI is the Path Forward”, in dem er argumentierte, dass das Öffnen von Llama Metas Einnahmen nicht untergräbt. Das war vor achtzehn Monaten. Die strategische Kalkulation hat sich eindeutig verschoben. Wie The Next Webs Analyse es formulierte, ist die Schließung ein Signal, dass Meta sich nun in einem Rennen sieht, bei dem das Verschenken architektonischer Innovationen mehr kostet als es einbringt.
Hier enden meine Daten. Ob zukünftige Muse-Modelle tatsächlich geöffnet werden, ist Spekulation. Ich werde aktualisieren, wenn es etwas Konkretes gibt.
Was das für Entwickler bedeutet, die derzeit Llama verwenden
Self-Hosted Llama: Noch lebensfähig, nicht veraltet
Als VentureBeat Meta direkt fragte, ob die Llama-Entwicklung beendet sei, sagte ein Sprecher: „Unsere aktuellen Llama-Modelle werden weiterhin als Open Source verfügbar sein.” Dieser Satz ist sorgfältig formuliert. Er bestätigt, dass bestehende Modelle verfügbar bleiben. Er sagt nichts über zukünftige Llama-Entwicklung.
Wenn du heute Llama 4 Scout oder Maverick in der Produktion betreibst, hat sich operativ nichts geändert. Die Gewichte sind noch auf Hugging Face. Die Community-Fine-Tunes funktionieren noch. Deine Infrastruktur muss nicht umziehen.
Operative Abwägungen: Heute vs. Warten
Hier ist die praktische Situation. Wenn du ein funktionierendes Llama-Deployment hast – Inferenz-Pipeline optimiert, Kosten vorhersehbar, Team mit den Parametern vertraut – hast du eine bekannte Größe. Die API-Preisgestaltung von Muse Spark wurde nicht bekannt gegeben. Öffentlicher API-Zugang wurde nicht angekündigt. Die private Vorschau ist nur auf Einladung.
Der Wechsel von einem selbst gehosteten Open-Weight-Modell zu einer geschlossenen API bedeutet, die Kontrolle über Latenz, Betriebszeit, Kostenstruktur und Datenverarbeitung aufzugeben. Für manche Teams macht dieser Trade-off Sinn. Für andere nicht. Der Punkt ist, dass du den Trade-off noch nicht einmal evaluieren kannst, weil Muse Sparks API-Bedingungen öffentlich nicht existieren.
Coding-Workflows: Die anerkannte Lücke
Wenn dein Llama-Deployment Code-Generierung, Code-Review oder irgendwelche entwicklerorientierten Aufgaben übernimmt, gibt es keinen Grund, Muse Spark jetzt in Betracht zu ziehen. Meta hat es selbst gesagt – Coding ist eine aktuelle Schwäche. Auf Terminal-Bench Hard liegt Muse Spark hinter Claude Sonnet 4.6 und GPT-5.4. Auf GDPval-AA, das reale Arbeitsaufgaben misst, erzielt es 1.427 ELO gegenüber Claude Sonnet 4.6’s 1.648.
Das passt zu meiner Häufigkeit. Deine könnte anders sein. Aber die Daten sind in diesem Punkt eindeutig.
Warum Meta diesen Schritt gemacht hat
Llama 4: Der anerkannte Stolperstein
Llama 4 wurde im April 2025 mit gemischter Resonanz veröffentlicht. Die Benchmark-Kontroverse – Meta verwendete eine spezialisierte, unveröffentlichte „experimentelle Chat-Version”, um die Ergebnisse auf LMArena zu verbessern – beschädigte die Glaubwürdigkeit. Die Modelle selbst waren solide für ihre Gewichtsklasse, bewegten die Frontier aber nicht. Bis Mitte 2025 lautete die Erzählung, dass Meta hinter OpenAI, Anthropic und Google zurückgefallen war.
Wangs Mandat
Im Juni 2025 gab Meta 14,3 Milliarden Dollar aus, um eine 49%ige stimmrechtslose Beteiligung an Scale AI zu erwerben und holte Mitgründer Alexandr Wang als Chief AI Officer. Das Mandat war explizit: aufholen. Meta Superintelligence Labs wurde gegründet. Forscher wurden von OpenAI, Anthropic und Google mit Gehaltspaketen rekrutiert, die Berichten zufolge Hunderte von Millionen erreichten, wenn Eigenkapital einbezogen wurde.
Neun Monate später ist Muse Spark das erste Ergebnis. Ob es die Investition rechtfertigt, hängt davon ab, was als nächstes kommt – dieses Modell ist bewusst klein und schnell, mit größeren Versionen bereits in Entwicklung.
Wettbewerbsdruck
Die Rechnung ist einfach. OpenAI und Anthropic werden zusammen mit über 1 Billion Dollar bewertet. Googles Gemini hat sowohl im Consumer- als auch im Entwicklermarkt an Boden gewonnen. Meta gab 2025 72 Milliarden Dollar für KI-Infrastruktur aus, steigend auf einen geführten Wert von 115–135 Milliarden Dollar im Jahr 2026, und hatte kein frontier-kompetitives Modell vorzuweisen. Etwas musste sich ändern.
Entscheidungsrahmen für Entwickler
Bei Llama bleiben, wenn:
Du offene Gewichte brauchst – für Self-Hosting, Fine-Tuning, On-Premises-Compliance oder Kostenkontrolle. Du Coding-intensive Workflows betreibst, bei denen Muse Spark anerkannte Lücken hat. Du vorhersehbare, selbstverwaltete Infrastruktur brauchst, die nicht von einer privaten API-Warteliste abhängt. Du bereits in Llama-spezifische Tools investiert hast (Quantisierungs-Pipelines, LoRA-Adapter, benutzerdefinierte Evaluierungen).
Muse Spark beobachten, wenn:
Du innerhalb von Metas Produkt-Ökosystem baust – alles, was sich mit Instagram, WhatsApp, Facebook oder Messenger integriert. Du starkes multimodales Verständnis brauchst, insbesondere visuelles Reasoning oder gesundheitsbezogene Aufgaben. Du bereit bist, auf öffentlichen API-Zugang zu warten und kannst evaluieren, sobald Preisgestaltung und Bedingungen verfügbar sind.
Was keines abdeckt:
Bildgenerierung. Videogenerierung. Das sind separate Modellkategorien. Muse Spark gibt nur Text aus, und Llama 4 gibt nur Text aus. Wenn du Generierungsfähigkeiten brauchst, schaust du auf ganz andere Tools.
FAQ

Kann ich Llama 4 noch verwenden, nachdem Muse Spark veröffentlicht wurde?
Ja. Llama 4 Scout und Maverick sind weiterhin auf Hugging Face und über Metas API-Partner verfügbar. Nichts wurde als veraltet markiert oder entfernt.
Wird Meta die Muse Spark-Gewichte veröffentlichen?
Meta sagte, es „hofft, zukünftige Versionen des Modells als Open Source zu veröffentlichen.” Es gibt keinen Zeitplan, keine konkrete Zusage über Muse Spark selbst und keinen Hinweis, was „zukünftige Versionen” in der Praxis bedeutet. Behandle das als Aspiration, nicht als Plan.
Ist Muse Spark besser als Llama 4 für Coding?
Nein. Meta erkennt Coding explizit als aktuelle Lücke an. Bei coding-spezifischen Benchmarks liegt Muse Spark hinter Claude Sonnet 4.6 und GPT-5.4. Wenn Coding dein primärer Anwendungsfall ist, ist Llama 4 Maverick mit Fine-Tuning oder ein zweckgebundenes Coding-Modell heute eine bessere Wahl.
Wann kommt das nächste Muse-Modell?
Meta beschrieb Muse Spark als „ersten Schritt” mit „größeren Modellen bereits in Entwicklung.” Keine Termine. Keine Namen. Keine Spezifikationen über die Bestätigung hinaus, dass sie existieren.
Beeinflusst das das breitere Open-Source-KI-Ökosystem?
Es ist ein Signal, kein Todesstoß. Metas Open-Weight-Llama-Modelle bleiben verfügbar. Andere Organisationen – Mistral, DeepSeek, Alibabas Qwen – veröffentlichen weiterhin offene Modelle. Aber Meta war der mit Abstand größte korporative Unterstützer offener Frontier-Modelle mit Gewichten. Wenn ihre Frontier-Investition dauerhaft in Richtung geschlossener Modelle verschoben wird, verliert das Ökosystem seinen am besten finanzierten Beitragszahler. Das ist über Jahre relevant, nicht über Wochen.
Das war’s. Mehr folgt, wenn die API öffentlich wird.
Vorherige Beiträge:
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt

GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing

GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten

MAI-Image-2.5 API: Was Entwickler wissen sollten
