LTX-2.3 API-Leitfaden: 7 Endpunkte, Zugriffsoptionen & Produktionseinsatz
LTX-2.3 bietet 7 Endpunkte: Text-zu-Video, Bild-zu-Video, Audio-zu-Video, Erweitern und Neuaufnahme (Standard- und Schnellvarianten). Dieser Leitfaden behandelt jeden Modus und verwaltete API-Zugriffsoptionen.

Hey, ich bin Dora. Ein kleiner Auslöser hat mich letzte Woche zur LTX-2.3 API gebracht: Ich baute immer wieder dieselben 6–10s-Erklärclips von Hand nach. Nichts Dramatisches – nur der Frust, dasselbe immer wieder zu tun. Ich hatte Erwähnungen von „Fast”-Varianten und „Retake”-Endpunkten gesehen, also reservierte ich mir ein paar Morgen im März 2026, um die ltx-2.3-API in echter Arbeit auszuprobieren. Kein großes Aufheben. Nur eine Handvoll Prompts, einige Produkt-Mockups und ein Podcast-Intro, an dem ich zu lange festhielt.
Was folgt, ist keine Funktionsübersicht. Es geht darum, wie sich die ltx-2.3-API-Endpunkte für mich verhalten haben, was die Arbeit beschleunigt hat und wo die Grenzen noch sichtbar sind.
Die 7 Endpunkte von LTX-2.3 auf einen Blick
Das ist die mentale Karte, die ich nach einer Woche Probeläufe verwendet habe. Das Wichtigste, was mir auffiel: Das sind keine eigenständigen „Features” – sie sind Regler in einer Sequenz. Ich skizzierte oft mit schnellem Text-to-Video, fixierte Prompts, wechselte dann zu Standard – oder ich startete einen Image-to-Video-Clip und verlängerte ihn für das Timing. Die Plattform bietet all das über ein standardisiertes REST-API-Design, was verhinderte, dass der Workflow über mehrere Tabs zersplitterte.
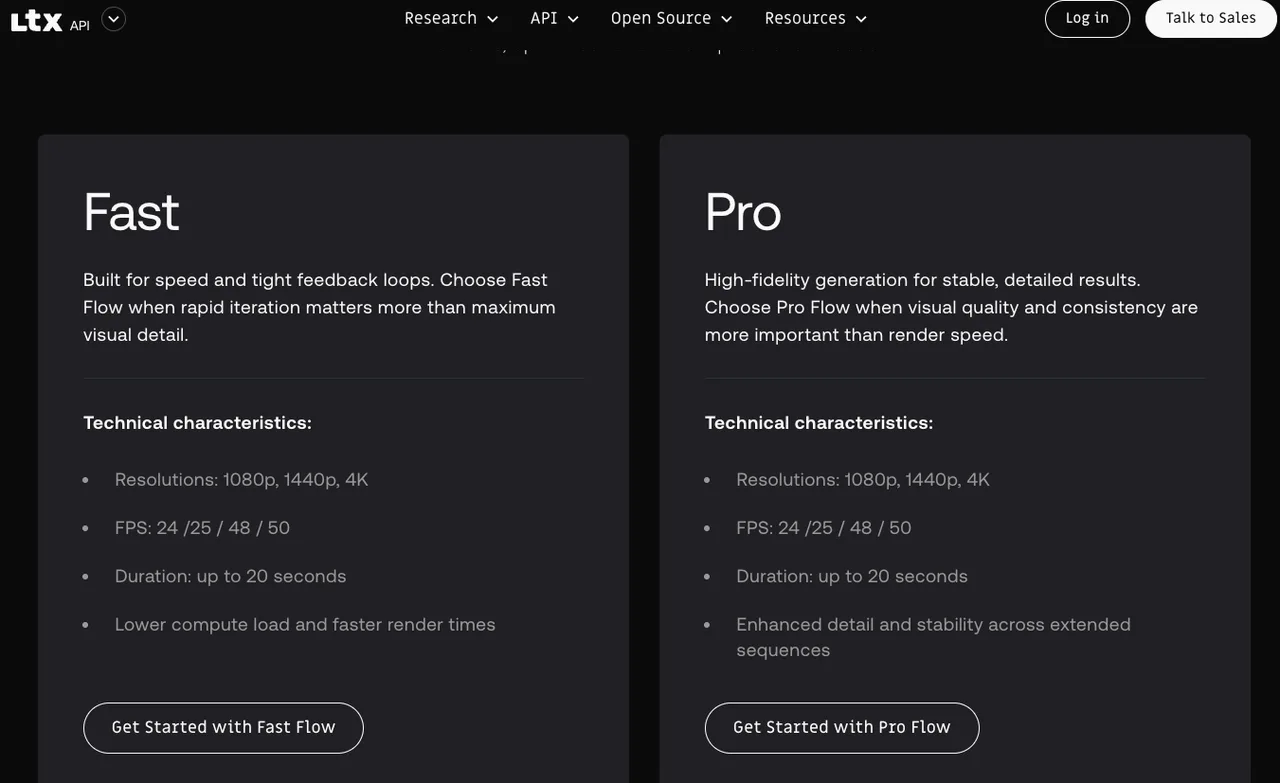
- Text-to-Video (Standard): der Qualitätsdurchlauf. Langsamer, bessere Bewegungskonsistenz, sauberere Texturen. Ich griff darauf zurück, wenn der Clip wichtig war und ich warten konnte.
- Text-to-Video (Fast): der Scout. Schnelle Einschätzungen zu Framing- und Bewegungsideen, nützlich für Prompt-Entwicklung und Batch-Ideenfindung.
- Image-to-Video: animiert ein einzelnes Frame. Wenn ich einen Logo-Bump oder ein Mockup wollte, das auf dem Bildschirm „atmet”, reichte das aus, ohne zu weit abzudriften.
- Audio-to-Video: Bewegung mit einem Audiotrack konditionieren. Kein Lippensync-Zauber – eher wie dem Modell ein Metronom geben.
- Extend-Video: hängt weitere Sekunden ans Ende. Die Kontinuität ist ordentlich, wenn Prompts und Seeds stabil sind.
- Retake-Video: regeneriert ein Segment mit beibehaltenen Einschränkungen. Hilfreich, um eine zittrige Hand oder eine seltsame Kamerabewegung zu korrigieren, ohne von vorne anzufangen.
- System/Utility: Job-Polling. Nicht glamourös, aber notwendig.
Text-to-Video: Kompromisse zwischen Standard- und Fast-Variante
Ich wechselte ständig zwischen beiden. Die Unterscheidung ist auf dem Papier einfach – Geschwindigkeit vs. Qualität – aber sie zeigt sich in konkreten Details, die beim Liefern wichtig sind.
- Fast war auf verwalteten Hosts 2–4× schneller pro Clip. Großartig für Skizzen und die Wahl einer Richtung – nicht so gut für feine Texturen oder kleine Typografie.
- Standard reduzierte „schmelzende Kanten” an Händen und Mikrobewegungs-Schimmern und hielt die Beleuchtungsrichtung über Frames hinweg konsistenter.
- Bei komplexen Prompts (Menschenmengen, Wasser, Laub) verarbeitete Standard temporales Rauschen besser. Fast sah beim ersten Ansehen manchmal gut aus, wirkte dann aber „unruhig”, wenn es neben echtem Filmmaterial geschnitten wurde.
Die nüchterne Wahrheit: Ich sparte mehr Zeit, indem ich die Varianten zum richtigen Zeitpunkt wechselte, als durch das Erhöhen einer einzelnen Einstellung.
Wichtige Parameter und Prompt-Hinweise
Einige Parameter haben wirklich etwas bewirkt:
- Dauer und Frames: Kürzer ist freundlicher. 4–8s bei 16–24 fps war der Sweet Spot für stabile Bewegung und vernünftige Wartezeiten.
- Seed: Einmal fixieren, wenn eine Richtung sich richtig anfühlt. Seeds machten Retakes und Verlängerungen deutlich weniger chaotisch.
- Guidance/CFG: Niedrigere Werte (4–6) ließen das Modell atmen; höhere Werte (7–9) klemmten den Stil fest, erhöhten aber die Gleichförmigkeit von Frame zu Frame.
- Negative Cues: Auf Bewegung ausrichten, nicht nur auf Visuales – „keine schnellen Zooms”, „keine Kameradrehung”, „ruhiges Stativ”. Das zügelte Rucken besser als das Beschreiben von Objekten.
Prompt-Form, die zuverlässig funktionierte: ein Satz für Szene und Subjekt, einer für Kamera und Bewegung, einer für Licht und Textur. Ich hörte auf, Adjektive zu überladen, sobald ich bemerkte, dass sie sich gegenseitig behindern.
Image-to-Video: Eingabespezifikationen und Artefaktrisiken
Ich nutzte das hauptsächlich, um Standbilder zu animieren – UI-Mockups, Produkt-Hero-Frames, einfache Logos. Die Eingabe mochte saubere Quellen: scharfe PNGs, kein Kompressionsrauschen. Quadratische oder nahezu quadratische Formate verhielten sich am besten.
- Sanfte Kameraanweisungen („subtiler Parallax, leichte Handkamera-Schwankung”) erzeugten Leben, ohne das Bild auseinanderzureißen.
- Text-Ebenen groß halten – kleine UI-Labels wurden in Bewegung unleserlich. Kritischen Text bettete ich stattdessen als Overlays in der Nachbearbeitung ein.
- Feine Linienzeichnungen flimmerten an den Kanten. Leichte Unschärfe bei der Vorverarbeitung half.
- Logos blieben lesbar, wenn ich schnelle Rotationen vermied. Für Enthüllungen ließ ich das Modell eine 10–15°-Neigung machen und schnitt dann.
Wenn ein Artefakt in Frame 1–2 auftaucht, bleibt es in der Regel bestehen. Mit einem neuen Seed neu generieren, bevor man versucht, es in der Nachbearbeitung zu beheben.
Audio-to-Video: Wie das Konditionieren wirklich funktioniert
Ich ging mit der Hoffnung auf Lippensync hinein. Das ist nicht, was dieser Endpunkt leistet. Denk stattdessen an Tempo, Energie und breite Bewegungshinweise. Bei Drum-Tracks fing das Modell die Downbeats als sanfte Kameranudges auf. Bei Ambient-Audio verlangsamte es sich – weniger Zucken, mehr Drift.
In der Praxis behandelte ich Audio wie eine Tempo-Karte. Für ein 20s-Ambient-Bett schnitt ich zwei 8s-Clips und einen 4s-Clip, jeden auf demselben Track konditioniert, und wählte dann den besten für die Kontinuität aus. Selbst niederfrequente Grummler formten die Bewegung – wenn die Kamera nicht bei jedem Bass-Hit „atmen” soll, füge „no rhythmic camera pulsing” als negativen Prompt hinzu.
Wo es half: Foley-Betten, Musik-Tempo für B-Roll, Ton-Matching. Wo nicht: Lippensync, präzise Beat-Schnitte oder Dialogszenen.

Extend und Retake: Längere oder korrigierte Sequenzen aufbauen
Diese beiden sind stille Gewinne. Ich kettete zwei 6s-Clips zu einem 12s-Shot, indem ich den Schwanz des ersten Clips mit demselben Prompt, Seed und denselben Kameraanweisungen verlängerte. Der Übergang war nicht perfekt, aber der Schnittpunkt versteckte sich gut unter einem Atemzug im Soundtrack. Wenn der erste Frame der Verlängerung falsch aussieht – dort stoppen. Schlechte Anfänge erholen sich selten.
Retake korrigierte einen schnellen Schwenk, der in die letzten 2s eines ansonsten guten Clips gerutscht war. Ich behielt die negativen Anweisungen zur Bewegung, nicht zum Inhalt, und benötigte durchschnittlich 1–3 Versuche. Beide Endpunkte profitieren von Disziplin: Seed, Dauer und Kamerasprache festlegen, bevor man Mikrokorrekturen verfolgt.
Self-Hosted vs. Managed API: Kompromisse
Ich probierte einen verwalteten Host (fal.ai-ähnliche Oberfläche) und eine lokale Maschine für einen Tag aus. Die verwaltete API gewinnt, wenn man schnell zehn Varianten braucht und sich nicht um Treiber kümmern möchte – aber Rate-Limits und Kosten pro Minute summieren sich bei längeren Läufen. Self-Hosting bietet niedrigere Grenzkosten und volle Batch-Kontrolle, auf Kosten von Einrichtungsaufwand und Treiberproblemen.
Eine einfache Faustregel: Ein Dutzend kurze Erkundungsclips – verwaltete API gewinnt. Hunderte von Sekunden mit fixierten Prompts – Self-Hosting beginnt sich zu rechnen.
Für Hardware war 24 GB VRAM der komfortable Boden für 8–10s-Clips bei 768p im März 2026. Die CUDA-12.x-Toolkit-Dokumentation deckt die Treiberanforderungen ab, wenn man eine lokale Inferenz-Box einrichtet – ich pinnte Treiber, um unerwartete Verlangsamungen zu vermeiden.
Häufige API-Fehler und wie man sie behebt
- Nicht übereinstimmende Dimensionen: Einige Endpunkte erfordern Dimensionen, die durch 16 teilbar sind. Wenn ein Job sofort fehlschlägt, auf das nächste Vielfache von 16 heruntergehen.
- Zu lange Prompts: Verwaltete Hosts kürzen oder unterbrechen sehr lange JSON-Payloads. Style-Listen in kürzere Phrasen verschieben; Negative sparsam verwenden.
- Seed-Drift zwischen Endpunkten: Das Wechseln von Text-to-Video zu Extend-Video ignorierte manchmal den Seed, wenn ich vergaß, ihn durchzureichen. Seed und cfg mit jeder Anfrage protokollieren.
- Rate-Limit-Bursts: Batch-Einreichungen um 200–300 ms staffeln oder die vom Anbieter empfohlenen Concurrency-Header verwenden.
FAQ
Was ist die maximale Clip-Länge pro einzelnem API-Aufruf?
Die meisten verwalteten Hosts begrenzen auf 4–10s bei üblichen Bildraten, um die Warteschlangen handhabbar zu halten. Beim Self-Hosting habe ich bis zu ~12–16s gepusht, bevor die Qualität nachließ. Für alles Längere Erweiterungen mit gemeinsamen Seeds verketten.
Wie groß ist der Qualitätsunterschied zwischen Fast- und Standard-Variante?
Merklich, aber kein Tag-und-Nacht-Unterschied. Fast liefert 70–80% des Looks in einem Bruchteil der Zeit. Wenn ein Clip neben Live-Action-Material erscheinen soll, mit Standard abschließen.
Können LoRA-Adapter über die verwaltete API angewendet werden?
Das hängt vom Host ab. Manche bieten Modell-Presets oder Style-Adapter; andere behalten sie im Standardzustand. Der Hugging Face Model Hub ist der beste Ort, um verfügbare Adapter-Slots und Community-Fine-Tunes zu vergleichen, bevor man sich für einen Anbieter entscheidet. Lokal hat man mehr Freiheit – aber auch mehr Möglichkeiten, Dinge kaputtzumachen.
Was ist mit dem Betrieb mehrerer Modalitäten über einen einzigen API-Key?
Die meisten Multi-Modell-Plattformen rechnen per Credit ab und decken Bild- und Video-Endpunkte unter demselben Key ab. Es lohnt sich, die Preisseite des Anbieters zu prüfen, bevor man anfängt – die OpenAPI Specification ist eine nützliche Referenz, um zu verstehen, wie gut strukturierte API-Dokumentation Endpunkt-Abdeckung und Abrechnungsverhalten darstellen sollte.
Ein Hinweis zu Videoqualitätsstandards
Eine Sache, die man im Hinterkopf behalten sollte: „Hohe Qualität” bedeutet in verschiedenen Kontexten verschiedenes. Für B-Roll, der für Social Media bestimmt ist, ist der Fast-Modus oft gut genug. Für alles, was gegen Broadcast- oder Kinomaterial geschnitten wird, hilft es zu verstehen, welche Codecs und Farbwissenschaft die endgültige Abgabe erfordert. Die SMPTE-Standardbibliothek ist trockene Lektüre, aber die Basisspezifikationen für Bildrate, Bittiefe und Farbraum sind relevant, wenn man Clips an einen Koloristen oder ein Post-Haus übergibt.
Ich schließe mit einer kleinen Anmerkung: Je mehr ich diese Endpunkte als Teile eines Systems behandelte – Seed-Disziplin, kurze Läufe, beständige Kamerasprache – desto weniger rang ich später mit ihnen. Es ist kein Zauber. Aber ein paar kleine Regeln ließen die Arbeit leichter erscheinen.
Vorherige Beiträge:
- Schritt-für-Schritt-Schnellstart für die Integration von WAN 2.7 in deinen API-Workflow
- WAN 2.7 vs. WAN 2.6 vergleichen, um echte Upgrade-Kompromisse zu verstehen
- Erfahre, wie anweisungsbasierte Videobearbeitung in echten Produktionspipelines funktioniert
- Sieh, wie die Kontrolle über erstes und letztes Frame die Konsistenz der Videogenerierung verbessert
- Erkunde, wie KI-Video-Upscaler die Ausgabequalität nach der Generierung verbessern
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt
GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing
GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten
MAI-Image-2.5 API: Was Entwickler wissen sollten