GPT Image 2 API-Leitfaden für Generierung und Bearbeitung
Ein praktischer GPT Image 2 API-Leitfaden für Entwickler, der Generierung, Bearbeitung, Workflow-Design und häufige Implementierungsüberlegungen abdeckt.

Letzte Woche habe ich ein kleines Produktfeature geliefert, das Bildgenerierung hinter einem Button benötigte. Zwei Tage nach Beginn des Builds wurde mir klar, dass die Integrationsentscheidungen, die ich am ersten Tag getroffen hatte, bestimmen würden, wie viel Schmerz ich die nächsten sechs Monate tragen würde. Genau davor warnt einen niemand bei der GPT Image 2 API. Das Hello-World ist einfach. Die Produktionspositionierung – das ist der interessante Teil.
Ich bin Dora. Ich schreibe Arbeitsnotizen, nachdem ich Dinge geliefert habe, nicht davor. Das ist, was ich beim Verdrahten von OpenAIs gpt-image-2 in ein echtes Produkt gelernt habe – und was ich einem anderen Entwickler oder KI-Engineering-Team mitgeben würde, bevor die erste Anfrage rausgeht.
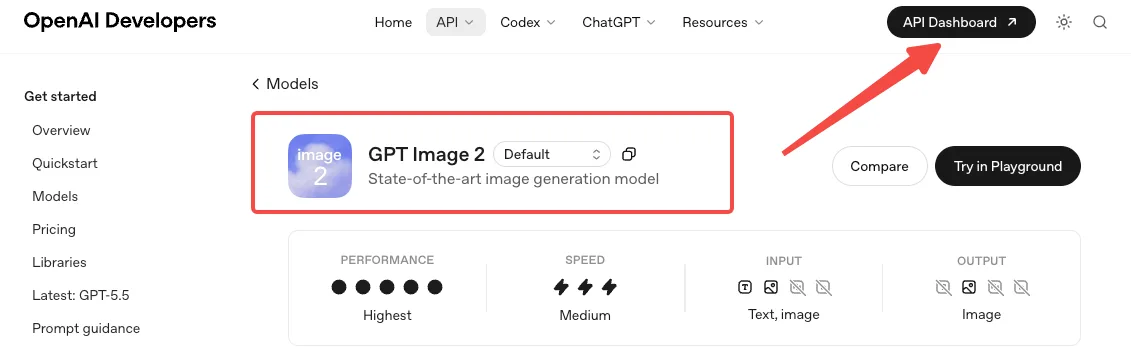
Was man braucht, bevor man die GPT Image 2 API nutzt
Modellzugang, Endpunkte und wichtige Dokumentation
GPT Image 2 wurde am 21. April 2026 veröffentlicht. Die Modell-ID lautet gpt-image-2. Vor dem ersten Aufruf muss man möglicherweise die API Organization Verification in der Entwicklerkonsole abschließen – OpenAI sperrt die GPT-Image-Familie dahinter.
Es stehen drei Oberflächen zur Auswahl. Die Image API stellt zwei Endpunkte bereit: images.generate für Text-zu-Bild und images.edit zum Modifizieren bestehender Bilder mit einem Prompt und einer optionalen Maske. Die dritte Oberfläche ist die Responses API, die Bildgenerierung als eingebautes Tool für konversationelle oder mehrstufige Abläufe bereitstellt.
Wählen nach Aufgabe, nicht nach Neuheit. Wenn das Produkt „Nutzer gibt Prompt ein, bekommt Bild” ist, nimmt man die Image API. Wenn das Produkt „Nutzer führt einen Hin-und-Her-Dialog, der manchmal Bilder produziert” ist, nimmt man die Responses API. Beide zu mischen, weil eine schicker aussieht als die andere, ist eine Wartungsfalle.
Was GPT Image 2 heute unterstützt
Zwei Dinge, die man früh verinnerlichen sollte.
Transparente Hintergründe werden nicht unterstützt. Anfragen mit background: "transparent" schlagen fehl. Wer transparente PNGs benötigt, leitet diese Aufgaben an gpt-image-1.5 weiter und akzeptiert, dass man jetzt zwei Modellpfade pflegt.
Input-Fidelity ist festgelegt. Der Parameter input_fidelity existiert bei älteren Modellen, aber gpt-image-2 verarbeitet Eingaben immer mit hoher Fidelity. Den Parameter weglassen, sonst schlägt die Anfrage fehl. Die Kostenimplikation: Edit-Anfragen mit Referenzbildern verbrauchen mehr Input-Token, als man von den gpt-image-1-Zeiten her erwarten würde.
Wie man Bilder mit GPT Image 2 generiert
Grundlegende Anfragestruktur und Ausgabeoptionen
Eine Generierungsanfrage nimmt einen Prompt, eine Größe, eine Qualität und ein Ausgabeformat entgegen. Das Format ist standardmäßig PNG; JPEG oder WebP können angefordert werden, wobei JPEG bei zeitkritischen Anfragen schneller als PNG ist. Die Größe akzeptiert Voreinstellungen oder benutzerdefinierte Abmessungen, mit der Einschränkung, dass beide Kanten Vielfache von 16 sein müssen, eine einzelne Kante maximal 3840 Pixel lang sein darf, das Seitenverhältnis unter 3:1 liegen muss und die Gesamtpixelzahl zwischen 655.360 und 8.294.400 liegt.
Der Parameter n ermöglicht die Generierung mehrerer Bilder in einer Anfrage. Nützlich, wenn man Varianten zum Vergleichen braucht. Weniger nützlich, wenn man pro Output-Token zahlt – was der Fall ist.
Größe, Qualität und Workflow-Kompromisse verwalten
Hier verbrennen die meisten Teams Geld, ohne es zu merken. GPT Image 2 wird pro Token abgerechnet, nicht pro Bild: Bild-Input 8 $ pro 1M Token, Bild-Output 30 $ pro 1M Token, Text-Input 5 $ pro 1M Token. Gecachte Eingaben sind günstiger. Batch-Verarbeitung halbiert die Standardpreise.
Was das in praktischen Zahlen bedeutet: Bei 1024x1024 schätzt OpenAIs Rechner ungefähr $0,006 für niedrige Qualität, $0,053 für mittlere, $0,211 für hohe**. Rechteckige Größen wie 1024x1536 sind etwas günstiger bei $0,005, $0,041 und $0,165. Das sind reine Output-Schätzungen. Input-Token und Edit-Referenz-Token kommen noch obendrauf.
Die Frage nach dem Kompromiss lautet also nicht, welche Qualität am besten aussieht. Sondern: Bei meinem Volumen – wie groß ist der Kostenunterschied zwischen mittlerer und hoher Qualität, und nimmt mein Nutzer diesen überhaupt wahr? Für eine Thumbnail-Oberfläche ist niedrige Qualität oft ausreichend. Für ein Hero-Image, das Nutzer intensiv betrachten, rechtfertigt Hoch seinen Preis. Ich habe Mittel als Standard gewählt und Hoch als Opt-in angeboten. Diese eine Entscheidung hat meine prognostizierte Monatsrechnung um etwa das 4-Fache verändert.
Wie Bildbearbeitung funktioniert
Eingabeanforderungen und häufige Bearbeitungsszenarien
Der Edits-Endpunkt nimmt ein Bild, eine optionale Maske und einen Prompt entgegen, der die Änderung beschreibt. Ein Bild übergeben, um es zu bearbeiten. Mehrere Bilder übergeben, um Motive, Stile oder Referenzen zu einem Output zu kombinieren. Das Modell verarbeitet Inpainting und Outpainting und bewahrt die unmaskierten Bereiche, während der Prompt auf den Rest angewendet wird.
Häufige Bearbeitungen, die ich validiert habe: Hintergrundtausch bei Produktfotos, Objektentfernung, Stiltransfer zwischen zwei Referenzbildern und Textübersetzung innerhalb eines Bildes. Die Behauptung der Charakterkonsistenz – gleicher Charakter in mehreren generierten Szenen – funktioniert bei mir bei einfachen Motiven. Bei wachsender Szenenkomplexität wird es weniger zuverlässig.
Fehler, die Kosten erhöhen oder die Konsistenz verringern
Überdimensionierte Eingaben senden. Da GPT Image 2 jede Bildeingabe mit hoher Fidelity verarbeitet, kostet ein 4K-Referenzfoto dieselben Input-Token, egal ob der Output ein Thumbnail oder ein Poster ist. Referenzen auf das herunterskalieren, was die Aufgabe tatsächlich benötigt.
Vage Edit-Prompts. „Mach es besser” produziert unvorhersehbare Änderungen und kostet oft einen Wiederholungsversuch. „Ändere den roten Hut in hellblauen Samt” bewahrt den Rest des Bildes und landet normalerweise in einem Versuch.
Unbegrenztes n. n=4 zu verlangen, um „Optionen zu sehen”, klingt harmlos, bis man merkt, dass man gerade das 4-Fache für eine Anfrage bezahlt hat, von der man nur einen Output verwenden wird.
Edits bei der Kostenschätzung wie Generierungen behandeln. Edits kosten oft mehr als Generierungen derselben Ausgabegröße, weil Referenzbilder Input-Token hinzufügen. Das in das Preismodell einplanen, bevor man launcht – nicht danach.
Produktionsüberlegungen für Teams
Wiederholungsversuche, Moderation und operative Leitplanken
Drei Dinge, die in der Produktion nicht optional sind.
Wiederholungsversuche mit exponentiellem Backoff. Bildgenerierung kann bei komplexen Prompts bis zu 2 Minuten dauern, und man wird auf Rate-Limits stoßen. OpenAIs Empfehlung ist, mit exponentiellem Backoff plus Jitter zu wiederholen – der Jitter ist wichtig, weil synchronisierte Wiederholungsversuche einer Flotte zur gleichen Zeit auf dieselbe Rate-Grenze treffen.
Moderation, in zwei Schichten. Der Bildgenerierungs-Endpunkt hat einen eingebauten moderation-Parameter (auto ist Standard; low ist permissiv, aber immer noch gefiltert). Für nutzereingereichte Prompts diese durch den kostenlosen omni-moderation-latest-Endpunkt laufen lassen, bevor sie an gpt-image-2 gesendet werden – er akzeptiert sowohl Text als auch Bilder und stoppt die meisten richtlinienwidrigen Anfragen, bevor man für die Generierung zahlt. Die Moderations-API-Referenz enthält die genaue Anfragestruktur.
Logging in der richtigen Granularität. Modell-ID, Größe, Qualität, Prompt-Token-Anzahl, Output-Token-Anzahl, Latenz, Anfrage-ID und finale Kostenschätzung pro Anfrage protokollieren. Wenn etwas im großen Maßstab schiefläuft, sind das die Daten, mit denen man es diagnostizieren kann. Wenn etwas gut läuft, sind das die Daten, die einem ermöglichen zu entscheiden, ob man weiter skalieren soll. In der Produktion auf einen spezifischen Modell-Snapshot pinnen statt auf den wandernden Alias, damit sich das Verhalten nicht unbemerkt verändert. Der Leitfaden für Best Practices in der Produktion behandelt Key-Rotation, Monitoring und den Rest der operativen Schicht.
Wann direkte Integration einfach bleiben sollte vs. wann eine Plattformschicht hinzuzufügen ist
Das ist die Frage, mit der ich am längsten gesessen habe.
Direkte OpenAI-Integration ist die richtige Antwort, wenn das Produkt ein einziges Bildmodell verwendet, das Team API-Ops-Erfahrung hat und der Traffic vorhersehbar genug ist, dass Rate-Limit-Eigentümerschaft und erstklassige Abrechnung wichtiger sind als Bequemlichkeit.
Eine Plattformschicht – und ja, ich arbeite bei WaveSpeedAI an einer – verdient ihren Platz in anderen Situationen. Man routet über mehrere Bildmodelle (gpt-image-2 für Typografie, ein anderes Modell für transparente PNGs, ein weiteres für Video). Man braucht flache Pro-Call-Preise für Budgetvorhersagbarkeit statt Token-Mathematik. Man möchte eine einzige Integrationsoberfläche, die Provider-Wechsel übersteht, ohne dass man alle Call-Sites neu schreiben muss.
Keine Antwort ist universell. Der ehrliche Test: Zählen, wie viele Modell-Provider das Produkt heute aufruft, mit der Anzahl multiplizieren, die es in zwölf Monaten aufrufen wird, und fragen, ob man so viele Integrationen selbst pflegen möchte.
FAQ
Welchen Endpunkt sollten Entwickler für GPT Image 2 verwenden?
images.generate für Text-zu-Bild nutzen, images.edit zum Modifizieren eines bestehenden Bildes mit einem Prompt und einer optionalen Maske, und das Responses-API-Image-Tool, wenn Generierung in einem mehrstufigen Gespräch stattfinden muss.
Unterstützt GPT Image 2 Bildbearbeitungen?
Ja. Der images.edit-Endpunkt akzeptiert ein oder mehrere Referenzbilder plus einen Prompt und unterstützt maskiertes Inpainting und Outpainting. Alle Bildeingaben werden automatisch mit hoher Fidelity verarbeitet.
Was sollten Teams in der Produktion protokollieren und überwachen?
Mindestens: Modell-Snapshot-ID, Größe, Qualität, Input- und Output-Token-Anzahl, Latenz, Anfrage-ID, Wiederholungsanzahl, Moderationsergebnis und finale geschätzte Kosten pro Anfrage. Das ist das, was einem ermöglicht, jeden Vorfall zu rekonstruieren und Ausgaben zu prognostizieren.
Wann reicht eine einfache API-Integration nicht mehr aus?
Wenn man mehr als einen Bild-Provider aufruft, wenn Fehlermodi Cross-Provider-Fallback benötigen oder wenn die Finanzabteilung nach vorhersehbaren Pro-Call-Preisen statt tokenbasierter Variabilität fragt. Unterhalb dieser Schwellenwerte bleibt direkte Integration die sauberere Wahl.
Wie verhindere ich, dass Prompt-Injection und unsichere Ausgaben in die Produktion gelangen?
Nutzerprompts durch den Moderations-Endpunkt vor der Generierung laufen lassen, den moderation-Parameter der Image API auf auto setzen, jede markierte Anfrage protokollieren und OpenAIs Safety Best Practices befolgen – einschließlich menschlicher Überprüfung für hochriskante Oberflächen und Red-Teaming vor dem Launch.
Fazit
Die GPT Image 2 API ist nicht schwer zu verdrahten. Die erste Anfrage dauert einen Nachmittag. Die wichtigen Entscheidungen – Qualitätsstandards, Edit-Kostenmodellierung, Moderationsschichtung, Wiederholungsverhalten, ob eine Plattformschicht hinzuzufügen ist – sind diejenigen, die sich still für Monate nach dem Launch aufaddieren. Diese bewusst treffen. Zunächst den kleinen Piloten durchführen. Der Rest folgt.
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt
GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing
GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten
MAI-Image-2.5 API: Was Entwickler wissen sollten