Claude Mythos vs Claude Opus 4.6: Was der Leak für Entwickler enthüllt
Claude Mythos vs Opus 4.6: Was der Leak über den Leistungsunterschied vermuten lässt und ob Entwickler jetzt warten oder bauen sollten.

Während ich letzte Woche mitten in einem Claude Code-Integration-Sprint war, tauchte der Mythos-Leak in meinem Feed auf. Drei Slack-Nachrichten in zehn Minuten, alle Variationen derselben Frage: “Sollen wir den Build pausieren?” Hier ist Dora, die KI-Enthusiastin, die die Geschichte seitdem genau verfolgt — und ich denke, die Antwort ist nuancierter als der Hype vermuten lässt.
Auf WaveSpeedAI verfügbar — Pro-Token-Abrechnung, OpenAI-kompatibler Endpunkt. Claude Opus 4.6 API → · Claude Opus 4.7 API → · Playground öffnen →
Lass mich durchgehen, was der Leak tatsächlich sagt, was Opus 4.6 dir derzeit bietet und wie du eine fundierte Entscheidung über das Timing treffen kannst.
Ausgangspunkt: Was Claude Opus 4.6 Entwicklern derzeit bietet
Bevor wir uns mit Mythos-Spekulationen befassen, lass uns bei dem verankern, was heute tatsächlich verfügbar und dokumentiert ist.
Leistung bei Coding- und Agenten-Aufgaben
Claude Opus 4.6 erreicht 65,4 % auf Terminal-Bench 2.0 und 72,7 % auf OSWorld und ist damit Anthropics stärkstes öffentlich verfügbares Modell für Coding- und Computer-Use-Aufgaben. Die Terminal-Bench-Zahl ist nicht nur ein Benchmark-Trophy — sie repräsentiert echte agentische Fähigkeit: mehrstufiges Debugging, groß angelegte Refaktorierungen und autonomes Tool-Chaining in erweiterten Workflows.
Das Modell ist für Agenten konzipiert, die über gesamte Workflows hinweg operieren und nicht nur auf einzelne Prompts reagieren, was es besonders effektiv für große Codebasen, komplexe Refaktorierungen und mehrstufiges Debugging macht, das sich über Zeit entfaltet. Wenn du Coding-Agenten oder agentische Pipelines baust, ist dies das Modell, das tatsächlich Issues schließt und Code in Produktionsqualität liefert.
Was operativ wichtig ist: Opus 4.6 zerlegt komplexe Aufgaben in unabhängige Teilaufgaben, führt Tools und Sub-Agenten parallel aus und identifiziert Blocker mit echter Präzision. Das ist das Verhalten, das den Unterschied in realen CI/CD-nahen Automatisierungen ausmacht — nicht nur in Demo-Umgebungen.
API-Verfügbarkeit, Preisgestaltung und Dokumentation
Hier ist der Teil, der für deinen Entscheidungszeitraum wichtig ist. Claude Opus 4.6 bietet State-of-the-Art-Reasoning zu $5 Input / $25 Output pro Million Tokens — eine Reduzierung von 67 % gegenüber der Opus 4.1-Ära bei $15/$75. Die vollständige Claude API-Dokumentation ist öffentlich, versioniert und stabil. Du kannst heute über claude-opus-4-6 darauf zugreifen.
Ein herausragendes Merkmal der 4.6-Generation ist, dass das vollständige Kontextfenster von 1 Million Token im Standardpreis enthalten ist, was die Premium-Langkontext-Aufschläge früherer Modelle eliminiert. Für Teams, die mit großer Codebasis-Aufnahme oder langen Recherche-Workflows arbeiten, ist das eine bedeutende Kostenreduzierung im Vergleich zu früheren Generationen.
Kostoptimierungshebel, die vollständig dokumentiert und jetzt verfügbar sind:
Was der Claude Mythos-Leak über die Lücke sagt
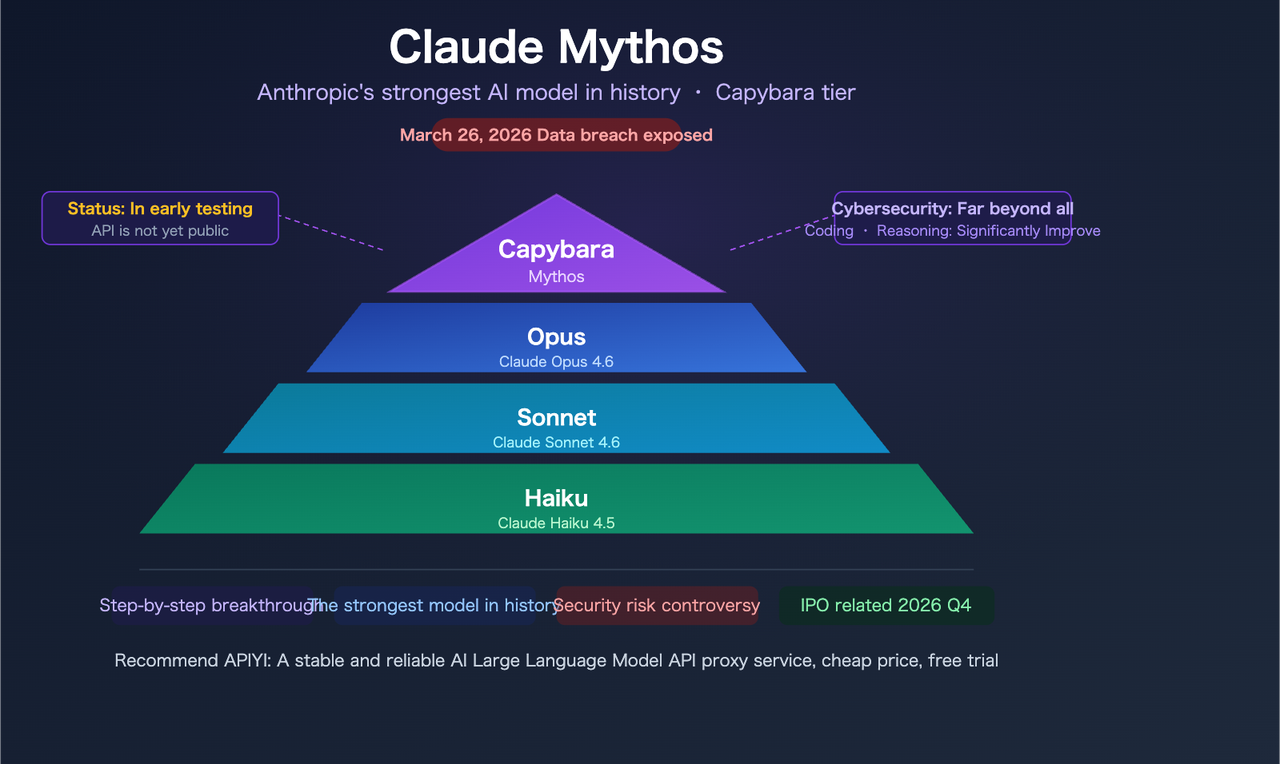
Anfang dieses Monats berichtete Fortune, dass Anthropic versehentlich fast 3.000 interne Dateien in einem falsch konfigurierten, öffentlich durchsuchbaren Datenspeicher exponiert hatte. Darunter: ein Entwurf eines Blog-Beitrags über ein Modell namens Claude Mythos — intern auch unter dem Codenamen “Capybara” bekannt.
Wichtige Einordnung vor dem Eintauchen: Alles Folgende stammt aus einem unverifiziertem Entwurfsdokument, nicht aus einer offiziellen Veröffentlichung. Keine öffentlichen Benchmarks, kein API-Zugang, keine Preisseite. Anthropic hat bestätigt, dass das Modell existiert und sich in begrenzten Tests befindet. Alles andere ist noch ein Entwurf.
Coding — “Dramatisch höhere Werte” entschlüsselt
Der geleakte Blog besagt: “Im Vergleich zu unserem bisherigen besten Modell, Claude Opus 4.6, erzielt Capybara dramatisch höhere Werte bei Tests von Software-Coding, akademischem Reasoning und Cybersicherheit, unter anderem.” Das ist bedeutungsvolle Sprache aus einem internen Dokument — “dramatisch höher” ist kein abgeschwächter Marketing-Text, sondern eine starke interne Aussage.
Was wir nicht haben: spezifische Zahlen. Über die qualitative Sprache im Entwurf hinaus wurden keine spezifischen Werte veröffentlicht. Wer jetzt genaue Mythos-Benchmark-Zahlen zitiert, erfindet sie. Die ehrliche Lesart hier ist, dass Anthropics interne Bewertung eine Lücke zeigte, die groß genug war, um eine neue Produktstufe zu rechtfertigen — was an sich ein bedeutendes Signal ist, aber nicht dasselbe wie verifizierte Daten.

Verbesserungen beim akademischen Reasoning
Der geleakte Entwurf gruppiert akademisches Reasoning zusammen mit Coding als eine wichtige differenzierte Fähigkeit. Anthropic beschreibt Mythos als “ein Allzweckmodell mit bedeutenden Fortschritten in Reasoning, Coding und Cybersicherheit.” Für Entwickler, die Forschungsassistenten, Dokumentenanalyse-Pipelines oder rechtliche/finanzielle Reasoning-Workflows bauen, lohnt es sich, das zu beobachten — Opus 4.6 erreicht bereits 90,2 % auf BigLaw Bench, und wenn Mythos diese Grenze weiter verschiebt, erweitert sich das Anwendungsflächenangebot erheblich.
Cybersicherheitsfähigkeiten: Neues Territorium
Dies ist die Fähigkeitsdimension, die die meiste Aufmerksamkeit bekommt — und das aus gutem Grund. Der geleakte Entwurf beschreibt das Modell als “derzeit weit vor jedem anderen KI-Modell in Cyber-Fähigkeiten” und warnt, es “kündigt eine bevorstehende Welle von Modellen an, die Schwachstellen auf eine Weise ausnutzen können, die die Bemühungen der Verteidiger bei weitem übertrifft.”
Geleakte interne Dokumente warnen, dass das Modell Cybersicherheitsrisiken erheblich erhöhen könnte, indem es Software-Schwachstellen schnell findet und ausnutzt, was potenziell einen Cyber-Rüstungswettlauf beschleunigt. Deshalb ist Anthropics anfänglicher Rollout auf Organisationen beschränkt, die sich auf Cyber-Verteidigung konzentrieren — ein ungewöhnlicher Schritt, der echte Bedenken über Missbrauch signalisiert und nicht nur Standard-Sicherheitstheater.
Die Dual-Use-Spannung hier ist real. Anthropics aktuelles Opus 4.6 demonstrierte bereits die Fähigkeit, bisher unbekannte Schwachstellen in Produktions-Codebasen aufzudecken — eine Fähigkeit, die das Unternehmen als dual-use anerkannte, da sie sowohl Hackern als auch Verteidigern hilft. Mythos scheint diese Fähigkeit erheblich weiterzuentwickeln, was den vorsichtigen Rollout erklärt.
Dies ist eine neue Stufe, kein Versions-Bump — warum das wichtig ist
Capybara strukturell über Opus
Der geleakte Entwurf besagt: “Capybara ist ein neuer Name für eine neue Modellstufe: größer und intelligenter als unsere Opus-Modelle — die bis jetzt unsere leistungsstärksten waren.” Das ist strukturell anders als Opus 4.5 → Opus 4.6. Anthropic hat derzeit drei Stufen: Haiku, Sonnet, Opus. Capybara würde eine vierte über allen hinzufügen.
Das hat Auswirkungen darauf, wie du deine Systeme architektierst. Wenn du gegen die Annahme baust, dass Opus immer die Obergrenze ist, bedeutet eine neue Stufe darüber potenzielle Fähigkeits-Upgrades, die nicht nur inkrementelle Fine-Tune-Bumps sind — sie repräsentieren eine andere Klasse von Task-Erfolgsraten.
Preisgestaltung: Teurer by Design
Noch gibt es keine offiziellen Preise, aber das strukturelle Signal ist klar. Der Entwurfs-Blog merkt an, dass das Modell teuer im Betrieb ist und noch nicht für die allgemeine Veröffentlichung bereit ist. Da Capybara in einer neuen Stufe über Opus sitzt, ist mit Preisen über den aktuellen $5/$25 pro Million Token für Opus 4.6 zu rechnen. Wie viel darüber ist wirklich unbekannt — aber plane dafür, dass es bedeutend höher ist, nicht nur ein kleines Inkrement.
Das ist nicht notwendigerweise eine schlechte Nachricht. Die 67-prozentige Preissenkung von Opus 4.1 zu Opus 4.6 zeigt, dass Anthropic gelernt hat, Flaggschiff-Preise über Generationen hinweg zu senken. Ein Capybara-Launch zu Premium-Preisen heute bedeutet nicht, dass es in 12 Monaten dabei bleibt. Das Muster legt nahe, dass die eigentliche ROI-Frage ist, ob der Fähigkeitssprung die Kosten für deine spezifische Task-Verteilung rechtfertigt.

Sollte dein Team auf Claude Mythos warten?
Das ist die eigentliche Entscheidung, weshalb du hier bist. Hier ist der ehrliche Rahmen.
Wenn du Coding-Agenten oder agentische Workflows baust
Baue jetzt mit Opus 4.6. Die Fähigkeitslücke mag real sein, aber auf ein unveröffentlichtes Modell ohne öffentlichen Zeitplan zu warten, ist keine Produktstrategie. Opus 4.6 ist bereits das stärkste öffentlich verfügbare Modell für agentisches Coding — Terminal-Bench 2.0 bei 65,4 % ist eine bedeutungsvolle Baseline, die heute Produktions-Use-Cases unterstützt.
Der wichtigere Punkt: Die Architekturentscheidungen, die du jetzt triffst — Prompt-Caching-Strategie, Sub-Agenten-Orchestrierung, Tool-Use-Muster — werden direkt auf Mythos übertragen, wenn es startet. Baue auf Opus 4.6, designe für modell-agnostisches Routing, und du wirst in einer viel besseren Position sein, um zu migrieren als Teams, die gewartet haben und von vorne anfangen müssen.
Wenn deine Priorität Kosteneffizienz im großen Maßstab ist
Baue definitiv jetzt. Mythos wird voraussichtlich teurer sein als Opus 4.6, und es gibt keinen Hinweis auf eine gleichwertige Budget-Stufe beim Launch. Wenn du hochvolumige Workloads betreibst, bei denen $5/$25 pro Million Token bereits sorgfältige Optimierung mit Batch-Verarbeitung und Prompt-Caching erfordert, ist Mythos wahrscheinlich nicht dein Standardmodell — auch nach der öffentlichen Verfügbarkeit. Nutze die Zeit, um deine Opus 4.6-Workflows zu optimieren; diese Einsparungen sind real und heute verfügbar.
Die lohnenswerte Mathematik: Ein Team, das $2.500/Monat für Standard-Opus 4.6 ausgibt, kann realistischerweise mit Model-Mixing, Batch-Verarbeitung und Caching auf ~$250/Monat kommen. Diese 90-prozentige Reduzierung akkumuliert sich erheblich über die Monate, die man mit Warten verbringen würde.
Wenn dein Use Case Schwachstellenforschung oder Sicherheit umfasst
Dies ist der eine Fall, wo Warten sinnvoll ist — aber du hast möglicherweise keine Wahl. Die anfängliche Zugriffsgruppe für Mythos konzentriert sich auf Sicherheitsforscher und Verteidiger — das Ziel ist es, Verteidigungen vorzubereiten, bevor die offensiven Fähigkeiten des Modells weit verbreitet werden. Wenn dein Team in der offensiven Sicherheitsforschung oder der Entwicklung von Verteidigungstools arbeitet, ist der richtige Schritt, sich über Anthropics Kanäle für frühen Zugang zu bewerben und in der Zwischenzeit weiterhin auf Opus 4.6 zu bauen.
Für allgemeine Unternehmens-Sicherheits-Tools (Code-Scanning, Compliance, Schwachstellen-Triage) ist Opus 4.6 bereits leistungsfähig und vollständig verfügbar. Mythos erweitert wahrscheinlich die Obergrenze, nicht die Untergrenze.
Was tun, solange Mythos nicht öffentlich verfügbar ist
Konkret: So vermeidest du verschwendeten Aufwand und bleibst gleichzeitig positioniert, um Mythos effizient zu übernehmen:
Designe für modell-agnostisches Routing. Abstrahiere deine Modellaufrufe hinter einer Routing-Schicht, sodass das Austauschen von claude-opus-4-6 durch einen zukünftigen claude-capybara-* Modell-String eine Konfigurationsänderung ist, kein architektonisches Rewrite. Das ist unabhängig von Mythos gute Praxis — es lässt dich auch heute kostensensitive Aufgaben an Sonnet 4.6 routen.
# Beispiel: modell-agnostischer Routing-Wrapper
import anthropic
MODEL_CONFIG = {
"flagship": "claude-opus-4-6", # hier austauschen, wenn Mythos startet
"balanced": "claude-sonnet-4-6",
"fast": "claude-haiku-4-5-20251001"
}
def call_claude(task_tier: str, messages: list, **kwargs):
client = anthropic.Anthropic()
return client.messages.create(
model=MODEL_CONFIG[task_tier],
max_tokens=1024,
messages=messages,
**kwargs
)Implementiere Prompt-Caching jetzt. Laut Anthropics Prompt-Caching-Dokumentation entstehen bei Cache-Schreibvorgängen ein Aufschlag von 25 % beim ersten Treffer, dann werden sie bei nachfolgenden Treffern mit 90 % Rabatt gelesen. Für agentische Workflows mit wiederholten System-Prompts oder großen Kontextblöcken ist dies die einzige kostenoptimierung mit dem höchsten Hebel — und sie wird auf Mythos genauso funktionieren.
Verfolge den offiziellen Release-Zeitplan. Anthropic hat Tests mit Early-Access-Kunden bestätigt. Das gestaffelte Rollout-Modell, das Anthropic verwendet — Sicherheitspartner zuerst, dann breiteren Zugang — legt nahe, dass die allgemeine API-Verfügbarkeit wahrscheinlich Wochen bis Monate entfernt ist, nicht Tage.
Bewerte deine Task-Verteilung ehrlich. Wenn 80 % deiner API-Aufrufe Dokumentzusammenfassung, Q&A oder strukturierte Extraktion sind, werden Mythos’ Coding- und Cybersicherheits-Fortschritte möglicherweise nicht viel bewegen. Opus 4.6 ist für diese Workloads bereits stark genug. Spar dir die Mythos-Bewertung für die Aufgaben auf, bei denen du derzeit an Opus’ Grenzen stößt.
FAQ
F: Kann ich Claude Mythos heute verwenden?
Nein. Stand Ende März 2026 ist Claude Mythos (Capybara) nur einer kleinen Gruppe von Early-Access-Kunden verfügbar, speziell denen, die an Cyber-Verteidigungs-Anwendungen arbeiten. Es gibt keine öffentliche API, keine Dokumentation und kein angekündigtes Launch-Datum. Claude Opus 4.6, erreichbar über claude-opus-4-6 auf der Anthropic API, bleibt das stärkste öffentlich verfügbare Modell.
F: Ist Opus 4.6 noch das beste öffentliche Claude-Modell?
Ja. Claude Opus 4.6 und Sonnet 4.6 bleiben die leistungsfähigsten öffentlich verfügbaren Claude-Modelle — und sie sind bereits bemerkenswert leistungsstark für Coding, Reasoning und komplexe Aufgaben. Opus 4.6 führt die öffentlichen Leaderboards für agentisches Coding an und ist vollständig dokumentiert mit stabilem API-Zugang auf Anthropics Plattform, AWS Bedrock, Google Vertex AI und Microsoft Foundry.
F: Wie viel teurer wird Claude Mythos sein?
Unbekannt. Der geleakte Entwurf bestätigt, dass das Modell “teuer im Betrieb” ist, und die neue Capybara-Stufe, die strukturell über Opus sitzt, impliziert einen Preisaufschlag über den aktuellen $5/$25 pro Million Token für Opus 4.6. Keine offiziellen Preise wurden veröffentlicht. Historische Präzedenzfälle zeigen, dass Anthropic die Flaggschiff-Preise über Modellgenerationen hinweg reduziert, sodass frühe Launch-Preise möglicherweise nicht die langfristigen Kosten widerspiegeln.
Vorherige Beiträge:
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt

GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing

GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten

MAI-Image-2.5 API: Was Entwickler wissen sollten
