Claude Mythos Coding-Performance: Was das für KI-Entwickler-Workflows bedeutet
Claude Mythos soll beim Coding deutlich besser abschneiden als Opus 4.6. Was das für Entwickler bedeutet, die 2026 KI-Coding-Agenten entwickeln.

Alle konzentrierten sich auf die Cybersicherheits-Warnung, als Fortune eine kurze, fett gedruckte Schlagzeile veröffentlichte: Anthropic hatte versehentlich fast 3.000 interne Dateien offengelassen, darunter einen Entwurf eines Blog-Beitrags, der ihr unveröffentlichtes Modell anpries. Doch als jemand, der jeden Tag mit Claude arbeitet, fesselte mich nicht das Leck selbst — sondern die leisen, explosiven Behauptungen, die in diesem Entwurf über Coding-Leistung begraben lagen.
Auf WaveSpeedAI verfügbar — Pro-Token-Abrechnung, OpenAI-kompatibler Endpunkt. Claude Opus 4.7 API → · Claude Sonnet 4.6 API → · Playground öffnen →
In diesem Artikel werden wir, ihr und ich, Dora, nicht dem Hype oder der Sicherheitspanik nachjagen, sondern direkt auf das eingehen, was für Entwickler und Teams, die echte Produkte ausliefern, wirklich zählt — indem wir genau darlegen, was wir (und was wir nicht) über Claude Mythos / Capybaras Coding-Fähigkeiten wissen.
Was der durchgesickerte Entwurf über die Coding-Leistung von Claude Mythos sagt
Die genaue Aussage aus dem durchgesickerten Entwurf: „Verglichen mit unserem bisherigen besten Modell, Claude Opus 4.6, erzielt Capybara deutlich höhere Punktzahlen bei Tests zu Software-Coding, akademischem Denken und Cybersicherheit, unter anderem.”
Das ist alles, was Anthropic schriftlich über die Coding-Leistung festgehalten hat. Keine SWE-bench-Prozentangabe, kein Terminal-Bench-Score, keine Vergleichstabelle. Der Ausdruck „deutlich höher” ist das eigentliche Signal — vage, aber nicht bedeutungslos.

Zum Kontext: Opus 4.6 führt derzeit öffentlich verfügbare Modelle bei SWE-bench Verified (~80,8 %), Terminal-Bench 2.0 und Humanity’s Last Exam an. Anthropics offizieller Sprecher bestätigte, dass das Modell „bedeutende Fortschritte beim Denken, Coding und in der Cybersicherheit” darstellt. Das Training ist abgeschlossen, Tests mit frühem Zugang laufen, und Coding ist ausdrücklich eine der drei primären Fähigkeitsdimensionen. Alles andere ist Schlussfolgerung.
Warum Coding die wichtigste Fähigkeit für diese Modellklasse ist
Terminal-Bench 2.0 Kontext und aktuelle Opus 4.6 Scores
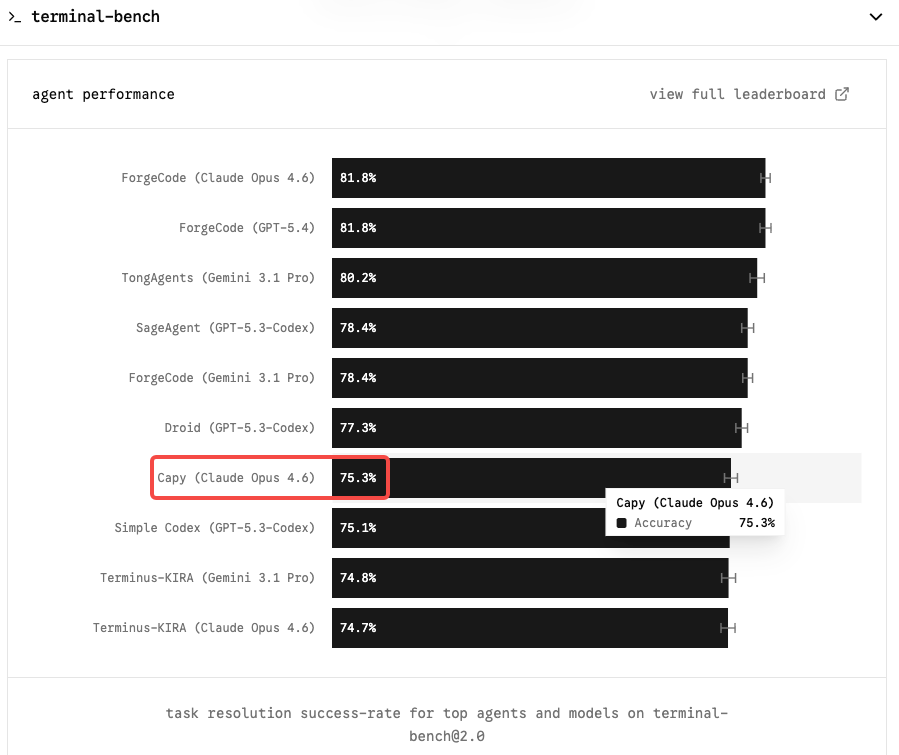
Terminal-Bench 2.0 ist der Benchmark, der für agentische Coding-Workflows am wichtigsten ist. Im Gegensatz zu SWE-bench, das isolierte GitHub-Issue-Auflösungen testet, bewertet Terminal-Bench reale Aufgaben in einer gesandboxten Terminal-Umgebung — Systemadministration, DevOps, mehrstufige CLI-Workflows. Es ist schwieriger, repräsentativer für den Produktionseinsatz und weniger anfällig für scaffold-getriebene Inflation.
Claude Opus 4.6 hält den Spitzenplatz mit 65,4 % auf Terminal-Bench 2.0 und 72,7 % auf OSWorld. Ein Modell der Capybara-Klasse, das diese Zahl in den Bereich von 75–85 % verschiebt, wäre eine echte Veränderung für jedes Team, das autonome Coding-Agenten betreibt.
Bei SWE-bench Verified ist das Bild enger: Sechs Modelle liegen jetzt innerhalb von 0,8 Punkten voneinander. Opus 4.6 liegt bei 80,8 %; Gemini 3.1 Pro liefert 80,6 % bei 2 $/12 $ pro Million Tokens. Reines SWE-bench ist kein bedeutsamer Unterscheidungsfaktor mehr. Terminal-Bench und Long-Context-Kohärenz sind, wo Opus 4.6 seinen Aufpreis verdient — und wo Mythos seinen klarsten Fall machen wird.
Was „deutlich höher” strukturell wirklich bedeutet
Im Entwurf erscheint „deutlich höher” neben „Quantensprung” — denselben Begriff, den Anthropics Sprecher öffentlich verwendete. Keiner dieser Begriffe ist beiläufig. Der Sprung von Opus 4.1 zu Opus 4.6 war eine generationelle Verbesserung innerhalb derselben Klasse. „Quantensprung” impliziert etwas qualitativ Anderes — eher wie der Abstand zwischen Sonnet und Opus als zwischen zwei aufeinanderfolgenden Opus-Versionen.
Ein Modell, das Opus 4.6 beim Coding deutlich übertrifft, wäre ein bedeutendes Werkzeug für Softwareentwicklung, Debugging und agentische Workflows. Die offene Frage ist, wann es verfügbar wird und zu welchen Kosten. Das ist die ehrliche Einschätzung. Die Leistungsbehauptung ist angesichts Anthropics jüngster Erfolgsbilanz glaubwürdig. Die Validierung liegt nur noch nicht vor.
Auswirkungen auf agentische Coding-Workflows
Long-Context Code-Aufgaben
Die unmittelbarste praktische Auswirkung eines Capybara-Klasse-Modells für Coding-Teams sind nicht rohe Benchmark-Scores — sondern was besseres Denken im Maßstab bewirkt.
Claude Codes 1M-Kontextfenster ist jetzt allgemein verfügbar für Opus 4.6 und bietet ~830K nutzbare Tokens nach Komprimierung — genug für ganze Monorepos und vollständige Dokumentationssätze. Ein Modell, das Opus 4.6 beim Coding dramatisch übertrifft, angewendet auf dasselbe Fenster, bedeutet besseres architektonisches Verständnis über große Codebasen hinweg und weniger Denkfehler bei Multi-File-Refactoring. Das Kontextfenster ändert sich nicht. Die Qualität des Denkens darin würde es.
Für Teams, die heute große Codebase-Analysen durchführen — die Art von Arbeit, bei der man 50K+ Zeilen Quellcode lädt und das Modell bittet, das Gesamtbild zu verstehen — ist dies der praktisch relevanteste Upgrade-Pfad.
Mehrstufige Debugging-Agenten
Anthropic hat Agent Teams als experimentelles Feature mit dem Opus 4.6-Release ausgeliefert, was einen bedeutenden Schritt bei agentischen Workflows markiert. Eine Sitzung fungiert als Teamleiter — sie koordiniert die Arbeit, weist Aufgaben zu und synthetisiert Ergebnisse. Teammitglieder arbeiten unabhängig, jeweils in ihrem eigenen Kontextfenster, und kommunizieren direkt miteinander.
Mehrstufige Debugging-Agenten sind der Ort, an dem der kumulierte Wert eines besseren Basismodells am deutlichsten wird. In einem Multi-Agenten-Setup bestimmt die Planungsqualität des Teamleiters, wie gut die gesamte Operation läuft. Ein stärkeres Modell trifft bessere Aufgabenzerlegungs-Entscheidungen, schreibt klarere Aufgabenspezifikationen für Subagenten und erkennt Integrationsfehler früher.
Der durchgesickerte Entwurf nannte ausdrücklich Software-Coding neben Cybersicherheit als die Bereiche, in denen Capybara Opus 4.6 „dramatisch” übertrifft. Wenn diese Lücke bei Terminal-Bench-ähnlichen Aufgaben real und substanziell ist, würde sie sich direkt in zuverlässigere mehrstufige Debugging-Agenten übersetzen, die weniger menschliches Eingreifen benötigen, um sich von falschen Annahmen zu erholen.
Selbstgesteuerte Codebase-Exploration
Dies ist der Anwendungsfall, für den ich mich in der Praxis am meisten interessiere. Claude Code verfolgt das Problem durch Ihre Codebase, identifiziert die Grundursache und implementiert eine Lösung. Die Qualität dieser Verfolgung ist eine Funktion der Denktiefe, nicht nur der Kontextfenstergröße.
In einem typischen Workflow von 2026 könnte ein Entwickler eine hochrangige Anforderung präsentieren, und der Lead-Agent zerlegt diese in verschiedene Aufgaben, wobei Teammitglieder das Model Context Protocol nutzen, um gleichzeitig auf externe Tools zuzugreifen, Tests auszuführen und Sicherheitsaudits durchzuführen. Ein Capybara-Klasse-Modell, das als Orchestrator in diesem Setup läuft, würde den gesamten Workflow autonomer machen — was bedeutet: weniger Klärungsanfragen, bessere anfängliche Aufgabenzerlegung und zuverlässigere Selbstkorrektur, wenn ein Subagent auf einen unerwarteten Zustand trifft.
Was Builder jetzt tun sollten, solange Mythos nicht verfügbar ist
Wie man Opus 4.6 für den eigenen Anwendungsfall benchmarkt
Das Nützlichste, was Sie jetzt tun können, ist, Ihre eigene Evaluierung auf Opus 4.6 durchzuführen — nicht gegen Benchmarks, sondern gegen Ihre tatsächliche Arbeitslast. Generische Benchmarks wie SWE-bench testen isolierte Issue-Auflösungen mit standardisiertem Scaffolding. Ihr Produktions-Coding-Agent hat eine spezifische Codebase-Struktur, einen spezifischen Satz von Aufgaben und einen spezifischen Fehlermodus. Das ist, was zählt.
Eine praktische Baseline-Evaluierung für einen Coding-Agenten könnte so aussehen:
# Einfaches Tracking der Aufgaben-Erfolgsrate
results = {
"task_id": [],
"model": [],
"success": [],
"turns_needed": [],
"context_used_tokens": [],
"cost_usd": []
}
# Führen Sie dieselben 20-30 repräsentativen Aufgaben durch Opus 4.6 aus
# Verfolgen Sie: Hat es beim ersten Versuch geklappt? Wie viele Durchläufe?
# Welchen Anteil des 1M-Kontextfensters hat es verbraucht?
# Wo ist es gescheitert — Denkfehler, Tool-Nutzung oder Kontext-Overflow?Der Grund, warum das wichtig ist: Wenn Mythos verfügbar wird, haben Sie eine echte Baseline, um zu beurteilen, ob die Fähigkeitsverbesserung den Kostenaufschlag für Ihren spezifischen Workflow rechtfertigt. „Dramatisch höher” in Anthropics internem Testsuite muss sich nicht zwangsläufig in einen bedeutsamen Unterschied bei Ihrer speziellen Codebase-Struktur und Aufgabenverteilung übersetzen.
Das „beste Modell” ist dasjenige, das dazu passt, wie Sie mit ihm kommunizieren. Ein mittelmäßiges Modell in einem guten Harness schlägt ein Frontier-Modell in einem schlechten. Ihre Harness-Qualität — Prompt-Engineering, Tool-Konfiguration, CLAUDE.md-Struktur — ist eine Variable, die Sie jetzt verbessern können. Mythos wird keine schlecht konzipierte Agenten-Architektur reparieren.
Architekturentscheidungen, die mit einem leistungsfähigeren Modell skalieren
Die gute Nachricht ist, dass gut konzipierte agentische Architekturen auf der Routing-Ebene modell-agnostisch sind. Die Muster, auf die es sich jetzt hinzuarbeiten lohnt:
Orchestrierung von Ausführung trennen. Ein Orchestrator-Agent, der Aufgaben zerlegt, Dateien zuweist und Outputs überprüft — unterstützt durch spezialisierte Subagenten für die Implementierung — kann sein Basismodell mit einer einzigen Parameteränderung tauschen. Bauen Sie diese Trennung jetzt auf, und das Mythos-Upgrade wird ein Konfigurations-Update, kein architektonisches Refactoring.
CLAUDE.md als Runtime-Kontext verwenden, nicht als sitzungsspezifisches Prompting. Die CLAUDE.md-Datei dient als „Verfassung” für KI-Agenten innerhalb eines Repositories — sie liefert den notwendigen Kontext über Projektarchitektur, Coding-Standards und Build-Befehle, der es Agenten ermöglicht, ohne menschliches Mikromanagement zu arbeiten. Ein gut strukturiertes CLAUDE.md reduziert die Explorationskosten pro Aufgabe bei Opus 4.6 heute und wird die Gewinne eines stärkeren Modells morgen verstärken.
Für das 1M-Kontextfenster entwerfen, nicht dagegen. Teams, die ihre Dateilade-Strategie, Chunking-Logik und Kontextverwaltung bereits so umstrukturiert haben, dass sie innerhalb des 1M-Fensters funktionieren, werden gut positioniert sein, um Mythos’s Denkfähigkeit über dasselbe Fenster voll auszuschöpfen. Bauen Sie keine Workarounds für Kontextgrenzen, die davon ausgehen, dass die Obergrenze nicht steigen wird.
Worauf Coding-fokussierte Teams beim Launch achten sollten
Die wichtigsten Signale für Entwickler unterscheiden sich von allgemeinen Enterprise-Signalen. Für coding-fokussierte Teams im Besonderen:
SWE-bench und Terminal-Bench Scores beim Launch. Anthropic hat diese historisch zusammen mit Modell-Releases veröffentlicht. Wenn Mythos die „dramatisch höher”-Behauptung erfüllt, würden Sie erwarten, dass die Terminal-Bench 2.0 Scores deutlich über Opus 4.6’s 65,4 % steigen. Ein Sprung auf 75 %+ würde die Behauptung für agentische Workflows validieren.
Claude Code Modell-String-Update. Überprüfen Sie die Claude Code-Dokumentation und die API-Modellübersicht auf einen neuen Modell-Alias. Claude Code hat historisch sein Standardmodell innerhalb von Tagen nach einem neuen Flagship-Release aktualisiert. Wenn Mythos für die öffentliche API verfügbar wird, wird es hier zuerst für Coding-Teams auftauchen.
Agent Teams Kompatibilitäts-Ankündigung. Agent Teams wurde als experimentell mit Opus 4.6 ausgeliefert. Ob Mythos nativ mit Agent Teams beim Launch integriert — oder eine separate Konfiguration erfordert — wird bestimmen, wie schnell Teams es in Multi-Agenten-Workflows bringen können.
Das Anthropic-Changelog und die Preisdokumentation. Diese beiden Seiten sind das früheste zuverlässige Signal vor jeder Pressemitteilung. Ein neuer Modell-String und eine neue Preiszeile werden hier zuerst erscheinen.
FAQ
Ist Claude Mythos jetzt für Coding-Aufgaben verfügbar?
Nein. Stand Anfang April 2026 gibt es keinen öffentlichen API-Endpunkt für Claude Mythos oder die Capybara-Klasse. Claude Mythos / Capybara ist nur für eine kleine Gruppe von Early-Access-Kunden verfügbar, die von Anthropic ausgewählt wurden, ohne öffentliche API, ohne angekündigte Preise und ohne bestätigtes Veröffentlichungsdatum. Claude Opus 4.6 — 80,8 % auf SWE-bench Verified, 65,4 % auf Terminal-Bench 2.0 — bleibt die beste öffentlich verfügbare Option.
Wird Claude Mythos mit Claude Code funktionieren?
Mit ziemlicher Sicherheit ja, irgendwann. Claude Codes Architektur ist modell-agnostisch; der Wechsel zu einem neuen Flagship ist eine einzige Parameteränderung. Aber dies ist für Mythos beim Launch nicht bestätigt.
Sollte ich auf Mythos warten, um mein KI-Coding-Tool zu bauen?
Nein. Anthropic hat erklärt, es müsse „deutlich effizienter werden, bevor es eine allgemeine Veröffentlichung gibt.” Jetzt auf Opus 4.6 aufzubauen bedeutet, dass Ihre Architektur produktionsvalidiert ist, wenn Mythos eintrifft. Das Upgrade wird ein Modell-String-Tausch sein. Die Teams, die warten, werden aufholen müssen.
Vorherige Beiträge:
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt

GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing

GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten

MAI-Image-2.5 API: Was Entwickler wissen sollten
