Claude Code Architektur im Detail: Was der geleakte Quellcode enthüllt
Der geleakte Claude Code Quellcode legte 512.000 Zeilen Produktions-TypeScript offen. Hier ist die vollständige Architekturanalyse – Tool-System, Query-Engine, Multi-Agenten-Muster und Kontextkomprimierung.

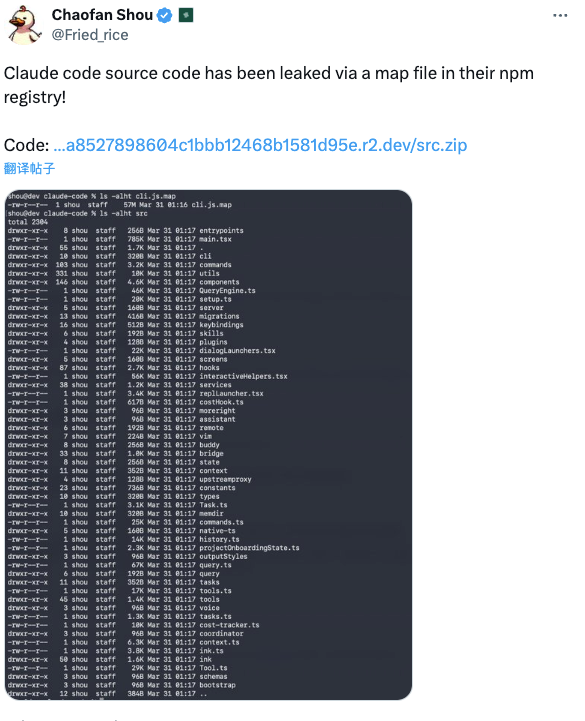
Hallo zusammen, ich bin Dora. Im März 2026 suchte ich nicht nach einem Kaninchenbau. Eine Nachricht erschien in meinem Feed: „Der Claude Code-Quellcode wurde über eine Map-Datei in ihrer npm-Registry geleakt.”
Ich schloss den Tab und schaute nicht zurück.
Was folgte, war einer der genuinen interessantesten Nachmittage, die ich damit verbracht habe zu studieren, wie ein KI-Tool in der Produktion tatsächlich gebaut ist. Nicht wegen des Leak-Dramas — das wird schnell alt — sondern weil der Code eine seltene Sache ist: ein echtes, veröffentlichtes, kommerziell dominantes agentisches CLI, untersucht mit 512.000 Zeilen Details.
Hier ist, was mir aufgefallen ist.
Warum der geleakte Quellcode eine seltene Architektur-Studienmöglichkeit ist
Nachdem Claude Code geleakt wurde, tauchte der Quellcode auf — exponiert durch eine falsch konfigurierte .map-Datei im npm-Paket von Anthropic — und Entwickler erkannten schnell, dass dies kein Wrapper um eine Chat-API war. Laut der Analyse von cybersecuritynews.com zum Vorfall umfasste die Exposition ungefähr 1.900 Dateien und über 512.000 Zeilen striktes TypeScript, wobei allein der primäre Einstiegspunkt 785 KB wog.
Der Stack selbst ist bereits interessant: Bun als Laufzeitumgebung (nicht Node.js), React mit Ink für das Terminal-UI-Rendering und Zod v4 für die Schema-Validierung überall. React-Komponentenmuster in einem CLI zu verwenden bedeutet Zustandsverwaltung, Re-Renders und zusammensetzbare UI-Komponenten in Ihrem Terminal. Das ist eine bewusste, mutige Entscheidung.
Was dies über Memes hinaus studierwürdig macht: Die Claude Code-Architektur-Muster hier gelten für jedes Team, das ernsthafte agentische Systeme baut.

Das Tool-System — 40+ eigenständige, berechtigungsgesicherte Module
Das Erste, was mir auffiel, war, wie sauber das Tool-System isoliert ist. Jedes Tool definiert sein eigenes Eingabe-Schema, seine Berechtigungsstufe und seine Ausführungslogik — unabhängig. Es gibt keinen gemeinsamen veränderlichen Zustand, der zwischen Tools schleicht.
BashTool und FileReadTool befinden sich in derselben Registry, haben aber grundlegend unterschiedliche Risikoprofile. Bash-Ausführung kann den Systemzustand ändern; Dateilesen ist schreibgeschützt. Die Architektur behandelt sie entsprechend und schützt jedes hinter seiner eigenen Berechtigungsstufe, anstatt eine pauschale Richtlinie anzuwenden. Diese Trennung ist in agentischen Produktionssystemen enorm wichtig, wo ein Berechtigungsmodell, das über Tools hinausleckt, ein Sicherheits- und Zuverlässigkeitsproblem darstellt, das nur auf seinen Moment wartet.
AgentTool ist das clevere Element. Es ermöglicht dem System, Sub-Agenten als einfachen weiteren Tool-Aufruf zu spawnen — keine spezielle Orchestrierungsschicht erforderlich, kein separates Prozessmodell. Sub-Agenten sind erstklassige Bürger derselben Tool-Registry. Diese Designentscheidung hält die Architektur flach und vorhersehbar.
Die Basis-Tool-Definition allein umfasst rund 29.000 Zeilen TypeScript. Das ist keine Aufgeblasenheit — das ist, wie rigorose Schema-Validierung, Berechtigungsdurchsetzung und Fehlerbehandlung in diesem Maßstab tatsächlich aussehen. Die offizielle Claude Code-Dokumentation von Anthropic bestätigt diese tool-zentrierte Philosophie: Tools sind es, die das System überhaupt agentisch machen.
Die 46K-Zeilen Query-Engine — Das eigentliche Gehirn von Claude Code
QueryEngine.ts hat 46.000 Zeilen. Lassen Sie das kurz sacken.
Dies ist das Modul, das alle LLM-API-Aufrufe, Streaming, Caching und Orchestrierung verwaltet. In einer einzigen Datei. Das klingt vielleicht nach einem Warnsignal — und je nach Ihren Codebase-Konventionen hätten Sie recht, es zu hinterfragen — aber die Begründung ist kohärent: Alles, was die Modell-API berührt, befindet sich an einem Ort, was bedeutet, dass Retry-Logik, Rate-Limit-Handling, Kontext-Budget-Management und Streaming-Fehler alle zusammen bedacht werden.
Die selbstheilende Query-Schleife ist der Teil, der mich überraschte. Wenn das Kontext-Budget sein Limit erreicht, stürzt die Engine nicht ab oder bittet um Hilfe. Sie löst automatisch Kompression aus, schnitzt einen Puffer vor der Obergrenze heraus und generiert eine strukturierte Zusammenfassung des bisher Besprochenen. Das ist kein Hack — das ist geplantes Verhalten. Für jeden, der lang laufende Agenten-Sitzungen baut, ist dieses Muster direkt studierwürdig.
Multi-Agenten-Orchestrierung — Koordinator, Worker und das Mailbox-Muster
Das Multi-Agenten-System verwendet das, was der geleakte Quellcode als Mailbox-Muster für gefährliche Operationen bezeichnet. Was das in der Praxis bedeutet: Ein Worker-Agent, der eine Aufgabe ausführt, kann eine risikoreiche Operation nicht eigenständig genehmigen. Stattdessen sendet er eine Anfrage an die Mailbox des Koordinators und wartet. Der Koordinator bewertet und genehmigt oder lehnt ab.
Der atomare Claim-Mechanismus verhindert, dass zwei Worker dieselbe Genehmigung gleichzeitig bearbeiten — ein subtiles, aber kritisches Detail in jedem System mit paralleler Ausführung. Gemeinsamer Speicherplatz für alle Agenten bedeutet, dass das Team einen kohärenten Kontext beibehält, ohne redundantes erneutes Abrufen.
Dies ist eine bedeutende Abkehr von naiven Multi-Agenten-Designs, bei denen jeder Agent mit voller Autonomie operiert. Die Koordinator/Worker-Aufteilung mit Genehmigungstoren ist der Weg, um Parallelismus ohne Chaos zu erreichen. Teams, die Orchestrierungsschichten für ihre eigenen agentischen Systeme bauen, sollten die agentischen Musterdokumentation von Anthropic durchlesen, bevor sie ihr eigenes Design entwickeln.
Dreilagige Kontextkompression — Ingenieurarbeit für lange Sitzungen
Dies ist wahrscheinlich das direkt nützlichste Stück Ingenieurarbeit in der gesamten Codebase für jeden, der KI-Anwendungen in der Produktion baut.
Claude Code verwendet drei verschiedene Kompressionsstrategien, jede an einem anderen Punkt ausgelöst:
MicroCompact bearbeitet zwischengespeicherte Inhalte lokal, ohne API-Aufrufe. Alte Tool-Ausgaben werden direkt gekürzt. Schnell, günstig, transparent.
AutoCompact wird ausgelöst, wenn sich das Gespräch dem Kontextfenster-Limit nähert. Es reserviert einen 13.000-Token-Puffer und generiert dann eine strukturierte Zusammenfassung der Sitzung von bis zu 20.000 Token. Es gibt einen eingebauten Schaltkreisunterbrecher — nach drei aufeinanderfolgenden Kompressionsfehlern hört es auf, es erneut zu versuchen. Keine Endlosschleifen.
Full Compact komprimiert das gesamte Gespräch und injiziert dann kürzlich aufgerufene Dateien (begrenzt auf 5.000 Token pro Datei), aktive Pläne und relevante Skill-Schemas neu. Nach der Kompression setzt sich das Arbeitsbudget auf 50.000 Token zurück.
Bemerkenswert ist, was diese Architektur für Tools impliziert, die Kompression vollständig überspringen. Agentische Tools, die das Kontext-Budget nicht verwalten, werden einfach im großen Maßstab scheitern — still degradieren oder auf harte Fehler treffen. Der dreilagige Ansatz ist ein seltenes Beispiel für das Designen für Sitzungslanglebigkeit von Anfang an, nicht als nachträgliche Ergänzung.
Feature-Flags als Architektur — 108 Module, die in der Produktion nicht existieren
Einer der weniger diskutierten Befunde aus dem geleakten Quellcode: 108 feature-gesicherte Module, aus externen Builds durch Buns kompilierzeitliche Dead-Code-Eliminierung entfernt.
KAIROS, VOICE_MODE, DAEMON — diese existieren nicht in der Version, die Sie installieren. Der Code ist im Quellcode vorhanden, aber Bun eliminiert ihn zur Kompilierzeit basierend auf der Feature-Flag-Konfiguration. Das Produktions-Bundle wird sauber ausgeliefert. So iterieren Sie an neuen Fähigkeiten, ohne das zu berühren, was sich bereits in den Händen der Benutzer befindet.
Die Ironie ist gut dokumentiert: Undercover Mode, ein Subsystem, das speziell entwickelt wurde, um zu verhindern, dass interne Codenamen in Git-Commits oder Ausgaben erscheinen, war im geleakten Quellcode vorhanden. Das System, das gebaut wurde, um Leaks zu verhindern, konnte den Leak selbst nicht verhindern. Kein katastrophales Sicherheitsversagen, aber ein lehrreiches darüber, wo sich Risiken tatsächlich in Software-Lieferpipelines ansammeln.
Telemetrie in die Kernschleife eingebaut
Zwei Telemetriesignale aus dem geleakten Quellcode, über die ich immer wieder nachdenke:
Eine Frustrations-Metrik verfolgt die Fluchfrequenz als UX-Signal. Wenn Benutzer das Tool anflüchen, geht etwas schief — ein führender Indikator, kein nacheilender.
Ein “Continue”-Zähler verfolgt, wie oft Benutzer das Wort “continue” mitten in einer Sitzung eingeben. Für ein agentisches CLI ist dies ein Proxy für Stillstände — Momente, in denen der Agent den Schwung verlor und der Mensch ihn vorwärts stoßen musste.
Keine ist eine Eitelkeitsmetrik. Beide enthüllen spezifische Fehlermodi, die Standardanalysen verpassen würden. Wenn Sie ein KI-Produkt mit erweiterten Interaktionssitzungen bauen, ist es die Ingenieurzeit wert, das Agentenverhalten auf diese Weise zu instrumentieren.
Was dies Entwicklern über Stack-Entscheidungen sagt
Die ehrliche Schlussfolgerung aus dem Studium dieser Claude Code-Architektur: Ein agentisches Produktions-CLI von Grund auf zu bauen ist ein erhebliches Ingenieursengagement. Das Tool-System, die Query-Engine, die Multi-Agenten-Orchestrierung, die Kontextkompression und die Telemetrie zusammen repräsentieren Jahre der Iteration, nicht Monate.
Das ist kein Argument gegen das Bauen. Es ist ein Argument dafür, klar zu sein, was man sich vornimmt. Muster wie das Mailbox-Genehmigungssystem und die dreilagige Kompression sind exportierbar — Sie brauchen keine 512.000 Zeilen, um die Kernideen zu implementieren.
Wo sich die Build-vs-Buy-Kalkulation verschiebt, ist beim Modellzugang und der Aggregation. Die Architektur setzt direkten Zugang zu einem einzelnen Modellanbieter voraus. Teams, die mit mehreren Modellanbietern arbeiten oder Produkte bauen, die modell-agnostisch bleiben müssen, stehen vor einer ganz anderen Reihe von Abwägungen.
Die Muster hier sind es wert, ausgeliehen zu werden. Die Komplexität ist es wert, verstanden zu werden, bevor man sich zur Replikation verpflichtet.

FAQ
Wie unterscheidet sich Claude Codes Tool-System vom Standard-Funktionsaufruf?
Standard-Funktionsaufruf behandelt Tools als flache Liste. Claude Code fügt pro-Tool-Berechtigungstore, isolierte Ausführungskontexte und Schema-Validierung an jeder Grenze hinzu — verhindert cross-tool Zustandsleckage und erzwingt Least-Privilege-Zugang, was wichtig ist, wenn BashTool den Systemzustand ändern kann.
Was ist das Mailbox-Muster und wann sollten Entwickler es verwenden?
Es leitet gefährliche Operationen von Worker-Agenten zur Genehmigung an einen Koordinator weiter, anstatt sie autonom auszuführen. Verwenden Sie es immer dann, wenn Sie parallele Agentenausführung haben und einen menschlichen Kontrollpunkt oder einen hierarchischen Genehmigungsmechanismus für risikoreiche Aktionen benötigen. Durchsatzkosten, Sicherheitsgewinn.
Wie geht Claude Code mit Kontextfenster-Limits im großen Maßstab um?
Dreilagige Kompression: MicroCompact (lokale Bearbeitungen, keine API-Kosten), AutoCompact (nahe Limits ausgelöst, generiert eine strukturierte Zusammenfassung mit reserviertem Token-Puffer) und Full Compact (vollständige Gesprächskompression mit selektiver Datei-Neuinjektion). Für lange Sitzungen ohne manuelle Eingriffe konzipiert.
Was sind kompilierzeitliche Feature-Flags und warum verwenden KI-Tools in der Produktion sie?
Sie erlauben, dass Code für unveröffentlichte Features im Quellcode existiert, ohne in Produktions-Builds zu erscheinen. Bun eliminiert abgeschalteten Code zur Kompilierzeit, sodass externe Benutzer niemals Features begegnen, die noch nicht bereit sind — Ausliefern von Bereitschaft trennen.
Ist es legal, den geleakten Quellcode für Architekturinspiration zu studieren und zu referenzieren?
Wert, vorsichtig behandelt zu werden. Der geleakte Quellcode ist das geistige Eigentum von Anthropic. Architekturmuster zu Bildungszwecken zu studieren liegt in anderem Terrain als Code direkt zu kopieren. Die offizielle Dokumentation von Anthropic bleibt die angemessene Referenz für alles, was Sie auf ihren Systemen aufbauen würden. Im Zweifelsfall konsultieren Sie Ihren eigenen Rechtsbeistand.

Das, worauf ich immer wieder zurückkomme, ist, wie viel von dieser Architektur darum geht, Fehler gracefully zu verwalten. Die Schaltkreisunterbrecher bei der Kompression, das Mailbox-Muster für gefährliche Operationen, die Berechtigungsisolation zwischen Tools — das sind keine optimistischen Designs. Sie wurden von Menschen gebaut, die gesehen haben, wie Dinge schiefgehen, und die entschieden haben, sie ingenieurtechnisch zu umgehen.
Das ist eine andere Art von Reife als Feature-Geschwindigkeit.
OK, das war es für heute. Bis zum nächsten Mal.
Frühere Beiträge:
- GPT-5, DeepSeek und andere Modelle in realer Leistung und Kosten vergleichen
- DeepSeek V4 Kontext-Caching verstehen und wie es die Effizienz langer Sitzungen verbessert
- Über DeepSeek V4 Rate-Limits und Skalierungsbeschränkungen für Produktionssysteme erfahren
- DeepSeek V4 Preisgestaltung und Kosten pro Million Token für großangelegte Anwendungen erkunden
- Sehen, wie viel GPU-VRAM DeepSeek V4 für reale Deployments benötigt
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt

GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing

GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten

MAI-Image-2.5 API: Was Entwickler wissen sollten
