Z-Image-Turbo LoRA auf WaveSpeed: Eigene Stile anwenden (bis zu 3 LoRAs)
Nutzen Sie Z-Image-Turbo LoRA, um eigene Stile, Charaktere und Markenidentitäten anzuwenden. Stapeln Sie bis zu 3 LoRAs, 0,01 $/Bild. Inkl. Trainingsanleitung (1,25 $/1000 Schritte).

Hey, ich bin Dora. Hattest du, wie ich, das Problem, dass meine Mockups immer wieder vom Markenstil abwichen – ein Blau, das immer ins Türkise kippte, ein Logo, das an den Rändern weich wurde, ein Produktfoto, das… fast stimmte. Nah dran ist gut genug für Entwürfe, aber es erzeugt Rauschen. Also habe ich letzte Woche LoRA mit Z-Image-Turbo auf WaveSpeed ausprobiert. Nicht um Neuheit zu jagen, sondern um zu sehen, ob ich aus „nah genug” ein „ja, rausbringen wir das” machen kann, ohne ständig Prompts nachzubessern.
Das sind meine Notizen: Was funktioniert hat, wo es gehakt hat, und wie ich es eingerichtet habe, damit es nicht mehr im Weg steht, sobald es eingestellt ist.
Was ist LoRA?
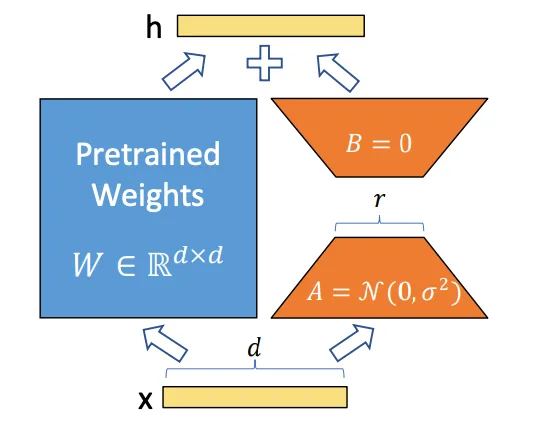 LoRA (Low-Rank Adaptation) ist eine kleine, gezielte Schicht, die ein großes Modell sanft in Richtung eines bestimmten Stils, einer Figur oder Ästhetik lenkt – ohne das gesamte Modell neu zu trainieren. Stell es dir wie eine sanfte Linse vor, die man hinzufügen oder entfernen kann. Das Basismodell behält seine breiten Fähigkeiten; das LoRA bringt ihm eine Vorliebe bei.
LoRA (Low-Rank Adaptation) ist eine kleine, gezielte Schicht, die ein großes Modell sanft in Richtung eines bestimmten Stils, einer Figur oder Ästhetik lenkt – ohne das gesamte Modell neu zu trainieren. Stell es dir wie eine sanfte Linse vor, die man hinzufügen oder entfernen kann. Das Basismodell behält seine breiten Fähigkeiten; das LoRA bringt ihm eine Vorliebe bei.
In der Praxis sind LoRA-Dateien kompakt, schnell zu trainieren und günstig auszutauschen. Der letzte Punkt ist für Workflows entscheidend. Ich will keinen separaten Modell-Checkpoint für jede Markenfarbpalette oder Figur. Ich will ein schnelles Grundgerüst (Z-Image-Turbo) und ein paar austauschbare Regler.
Warum LoRA für Z-Image-Turbo?
 Z-Image-Turbo auf WaveSpeed ist auf Geschwindigkeit ausgelegt. Toll zum Iterieren, aber Geschwindigkeit allein löst nicht das Problem „konsistenter Stil.” LoRA füllt diese Lücke. Ich kann:
Z-Image-Turbo auf WaveSpeed ist auf Geschwindigkeit ausgelegt. Toll zum Iterieren, aber Geschwindigkeit allein löst nicht das Problem „konsistenter Stil.” LoRA füllt diese Lücke. Ich kann:
- das Basismodell reaktionsschnell halten,
- ein vorgefertigtes LoRA für einen Look oder eine Figur anhängen,
- oder ein kleines benutzerdefiniertes LoRA für meine eigenen Assets trainieren.
Was mich überrascht hat, war die Kontrolle, die mir der Scale-Parameter gab. Ein kleiner Wert (0,3–0,6) bewahrte die Stärken des Basismodells. Ein höherer Wert (0,8–1,0) drängte stärker in den gelernten Stil – manchmal zu stark. Ich fing niedrig an und erhöhte dann, bis es sich richtig anfühlte. Diese einfache Gewohnheit reduzierte meine erneuten Renderings um etwa ein Drittel über die Woche.
Vorgefertigte LoRAs verwenden
Ich probierte zunächst vorgefertigte LoRAs aus, weil ich nichts trainieren wollte, bevor ich die Grenzen kannte. WaveSpeed behandelt LoRA wie ein Plug-in: auf eine Datei zeigen, einen Scale einstellen, loslegen.
Kompatible LoRAs finden
Kompatibilität hängt von Format und Basismodellfamilie ab. Wenn ein LoRA gegen ein ähnliches Diffusions-Grundgerüst trainiert wurde (und als kompatibel mit Z-Image-Turbo oder seiner Abstammung angegeben war), verhielt es sich in der Regel gut. Ich behielt eine kurze Checkliste:
- gleiche oder verwandte Basismodellfamilie,
- Versionshinweise, wenn vorhanden (Datum + Modell-Tag),
- eine Vorschaugalerie, die Vielfalt zeigt – keine reinen Vorzeigeergebnisse.
Wenn ein LoRA „zu perfekt” aussah, vermutete ich Overfitting. In meinen Tests neigten diese dazu, bei Prompts außerhalb eines engen Bereichs zu versagen. Die besseren Sets hielten stand, wenn ich Beleuchtung oder Kamera-Begriffe änderte.
API-Parameter: path + scale
 Die API von WaveSpeed verwendet eine einfache Struktur pro LoRA: einen path (wo die LoRA-Datei liegt) und einen scale (wie stark er angewendet wird). Path kann ein gehostetes WaveSpeed-Asset oder eine von dir kontrollierte signierte URL sein. Scale ist ein Float. Ich bewegte mich meistens zwischen 0,35 und 0,7. Unter 0,3 konnte ich oft nicht erkennen, dass es aktiv war; über 0,8 zerstörte es manchmal die Komposition.
Die API von WaveSpeed verwendet eine einfache Struktur pro LoRA: einen path (wo die LoRA-Datei liegt) und einen scale (wie stark er angewendet wird). Path kann ein gehostetes WaveSpeed-Asset oder eine von dir kontrollierte signierte URL sein. Scale ist ein Float. Ich bewegte mich meistens zwischen 0,35 und 0,7. Unter 0,3 konnte ich oft nicht erkennen, dass es aktiv war; über 0,8 zerstörte es manchmal die Komposition.
Eine kleine Anmerkung aus tatsächlichen Durchläufen: Wenn dein Path falsch ist oder das Asset ohne das richtige Token privat ist, bekommst du nicht immer einen deutlichen Fehler – du bekommst einfach Bilder, die wie das Basismodell aussehen. Wenn etwas verdächtig generisch wirkte, überprüfte ich den Path noch einmal.
Mehrere LoRAs stapeln (bis zu 3)
Du kannst bis zu drei LoRAs stapeln. Ich versuchte eines für Farbbehandlung, eines für eine Markentextur und eines für Figurmerkmale. Es funktionierte, aber erst nachdem ich ihre Scales balanciert hatte. Wenn zwei LoRAs sich beißen (z. B. eines besteht auf sanftem Filmkorn, während ein anderes scharfen Produktglanz hinzufügt), wirkt das Bild unentschieden. Meine Regel:
- jedes bei 0,3 starten,
- das Anker-LoRA identifizieren (den unverzichtbaren Look),
- dieses langsam erhöhen,
- die anderen anpassen, bis sie ergänzen statt konkurrieren.
Das Stapeln sparte mir Zeit, wenn ich sowohl Markengefühl als auch eine wiederkehrende Figur brauchte. Es sparte keine Zeit, wenn ich versuchte, drei schwere Stile gleichzeitig zu erzwingen. Das brachte mich nur zurück ins Trial-and-Error.
API-Implementierung
So habe ich das in einem kleinen Skript verdrahtet. Ich verwendete Prompts, die ich tatsächlich einsetze: Produktmockups mit Hintergrundvariationen, plus ein paar Figuraufnahmen für interne Dokumente.
LoRA-Parameterstruktur
Der Request-Body enthält ein loras-Array. Jedes Element:
- path: String (WaveSpeed-Asset-Pfad oder signierte URL)
- scale: Float (0,0–1,0; ich empfehle zum Einstieg 0,3–0,7)
Andere Z-Image-Turbo-Parameter (prompt, negative_prompt, seed, steps, width/height) funktionieren wie gewohnt. Seeds halfen mir, Scale-Änderungen direkt zu vergleichen.
Python-Code-Beispiel
import requests
API_KEY = "YOUR_WAVESPEED_KEY"
ENDPOINT = "https://api.wavespeed.ai/api/v3/wavespeed-ai/z-image/turbo"
payload = {
"prompt": "minimal product photo of a cobalt-blue bottle on soft textured linen, natural window light, 50mm, f2.8",
"negative_prompt": "text, watermark, harsh shadows, warped label",
"width": 768,
"height": 768,
"steps": 16,
"seed": 12345,
"loras": [
{"path": "wavespeed://assets/brand/linen_texture_lora.safetensors", "scale": 0.45},
{"path": "wavespeed://assets/brand/cobalt_hue_lora.safetensors", "scale": 0.55}
]
}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
r = requests.post(ENDPOINT, json=payload, headers=headers, timeout=60)
r.raise_for_status()
result = r.json()
# Base64-Bilder oder URLs erwarten, je nach Account-Einstellungen
print(result.get("images", []))In meinen Durchläufen reichten 16 Steps mit Z-Image-Turbo für Vorschauqualität. Für finale Bilder erhöhte ich auf 22–24 Steps. Das fügte ~0,3–0,6 Sekunden pro Bild in meinem Account hinzu, was in Ordnung war.
LoRA-Scales balancieren
Ich iterierte so:
- Seed fixieren,
- alle LoRAs auf 0,3 setzen,
- das Anker-LoRA auswählen und um 0,1 erhöhen, bis es sich richtig anfühlt,
- die anderen in 0,05–0,1-Schritten anpassen.
Den Seed beim Einstellen der Scales festzuhalten half mir, den Effekt direkt zu sehen. Sobald mir die Balance gefiel, löste ich den Seed für Variation. Das sparte mir anfangs keine Zeit – ich verbrachte 15–20 Minuten damit, ein Gespür zu entwickeln. Aber am dritten Tag bemerkte ich, dass ich aufgehört hatte, Prompts anzupassen. Die Scales trugen den Stil, und ich konzentrierte mich stattdessen auf Layout und Text.
Benutzerdefinierte LoRAs trainieren
Nach den vorgefertigten trainierte ich ein kleines LoRA für die Flaschenform und den Etikettenstil eines Kunden. Ich tat es, um das Hin-und-Her zu reduzieren, bei dem der Halswinkel und der Etikettenglanz immer wieder abwichen.
Trainingsdaten vorbereiten (ZIP-Upload)
Ich sammelte 18 Bilder, bereingte Hintergründe und hielt Metadaten konsistent. Ich zippte sie – einfacher Ordner, Kleinbuchstaben in Dateinamen, keine Leerzeichen – und lud sie hoch. Ich fügte 3–4 Bildunterschriften pro Bild hinzu, wenn der Etikettentext wichtig war. Wenn nicht, hielt ich die Beschriftungen minimal. Mehr Bildunterschriften halfen dabei, das Etikett lesbar zu halten.
Eine kleine Hürde: Bilder, die fast identisch aussahen, halfen nicht. Ich entfernte Beinahe-Duplikate und sah weniger Overfitting.
Trainingsparameter
Ich hielt es leicht:
- Auflösung: 768 quadratische Ausschnitte,
- Batch-Größe: 1,
- Lernrate: konservativer Standard,
- Trainings-Steps: 3.000–6.000 für Stil + Form,
- Netzwerkrang (r): moderat; hohe Werte machten es „lauter” als gewünscht.
Als ich Steps über ~8.000 erhöhte, fing es an, die Flasche in Prompts einzufügen, wo ich sie nicht verlangt hatte. Nicht ideal. Weniger Steps plus ein saubererer Datensatz gewann.
Preise: 1,25 $ pro 1.000 Steps
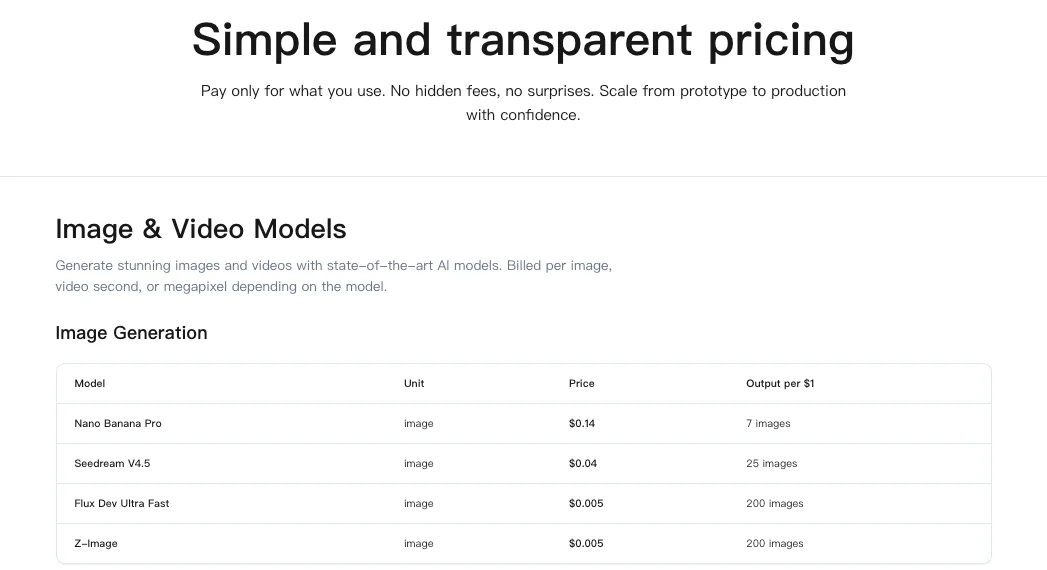 Meine zwei Durchläufe (3.500 und 5.000 Steps) kosteten insgesamt 10,63 $ bei 1,25 $ pro 1.000 Steps. Das ist vernünftig, wenn das LoRA sich einige Monate lang bewährt.
Meine zwei Durchläufe (3.500 und 5.000 Steps) kosteten insgesamt 10,63 $ bei 1,25 $ pro 1.000 Steps. Das ist vernünftig, wenn das LoRA sich einige Monate lang bewährt.
Typisches Trainingsbudget
Was ich jetzt einplanen würde:
- Nur-Stil-LoRA: 2.000–4.000 Steps (2,50–5,00 $),
- Figur mit Ausdrücken: 5.000–8.000 Steps (6,25–10,00 $),
- Produktform + Etikettendetails: 3.000–6.000 Steps (3,75–7,50 $).
Ich würde zuerst einen kürzeren Durchlauf machen, die Ergebnisse prüfen und dann aufstocken, wenn es vielversprechend ist. Zwei kleinere Durchläufe schlagen eine lange Overfitting-Session.
Anwendungsfälle
Das sind die Bereiche, wo LoRA auf Z-Image-Turbo mir geholfen hat, schneller zu liefern – nicht jeden Tag, aber zuverlässig, wenn die Aufgabe passte.

Konsistenz des Markenstils
Wenn du es satt hast, Markenhinweise in jeden Prompt einzutippen, hält ein milder Stil-LoRA bei 0,4–0,6 Farbe, Kontrast und Textur in Einklang. Ich nutzte das für Social-Media-Varianten und Web-Banner. Es machte sie nicht brillant – es machte sie einfach konsistent. Das ist der Punkt. Ich sparte vielleicht 5–7 Minuten pro Lieferobjekt, indem ich die zweite Runde „Vibe korrigieren” übersprang.
Figuren-LoRAs
Für interne Dokumente und ein leichtgewichtiges Maskottchen, das in Onboarding-Screens erscheint, hielt ein Figuren-LoRA die Merkmale über verschiedene Winkel hinweg stabil. Es mit einer sanften Farbbehandlung zu stapeln funktionierte, aber erst nachdem ich den Figuren-Scale auf 0,35 reduziert hatte. Höher und es überrollte die Beleuchtung. Einmal eingestellt, beseitigte es eine seltsame mentale Belastung: Ich hörte auf, mir Sorgen zu machen, ob das Gesicht abdriften würde.
Produktspezifische Ästhetik
Das benutzerdefinierte Flaschen-LoRA reduzierte Etikettenverzerrungen und bewahrte die Halsgeometrie bei Nahaufnahmen. Es war nicht makellos – enge Reflexionen brauchten noch ein paar Versuche –, aber es senkte die Anzahl unbrauchbarer Renderings. Der stille Gewinn war Vorhersagbarkeit. Wenn ich „Dreiviertelwinkel auf Leinen” tippte, bekam ich das – keine überraschende Variante.
Wer das mögen könnte: Leute, die bereits wissen, was sie wollen, und es satt haben, immer wieder mit dem Modell zu diskutieren. Wer nicht: Menschen, die jedes Mal wilde neue Stile erkunden. LoRA ist ein Stabilisator. Er glänzt, wenn du weniger Überraschungen über mehr Feuerwerk schätzt.
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt
GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing
GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten
MAI-Image-2.5 API: Was Entwickler wissen sollten