Gemini 3.1 Flash-Lite: Funktionen, Anwendungsfälle und Vergleich mit Flash
Gemini 3.1 Flash-Lite ist Googles günstigstes Inferenzmodell. Funktionen, reale Anwendungsfälle und ein direkter Vergleich mit Gemini Flash.

Mir fiel etwas Merkwürdiges auf, als Google am 3. März Gemini 3.1 Flash-Lite veröffentlichte. Normalerweise bringen sie zuerst das leistungsstärkere Flash-Modell heraus — oder überspringen die Lite-Stufe ganz. Diesmal gingen sie direkt zur Budget-Option über. Diese Verschiebung ließ mich aufhorchen.
Auf WaveSpeedAI verfügbar — Pro-Token-Abrechnung, OpenAI-kompatibler Endpunkt. Gemini 2.5 Pro API → · Gemini 2.5 Flash Lite API → · Playground öffnen →
Ich bin Dora. Ich teste es seit dem vergangenen Tag, und was mich überraschte, war nicht nur die Geschwindigkeit. Es war die Art, wie die Preisstruktur bestimmte Workflows plötzlich … erschwinglich machte, wie sie es zuvor nicht waren.

Was ist Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite steht am unteren Ende von Googles neuester Modellreihe, aber „unten” bedeutet nicht mehr das, was es früher bedeutete. Laut Googles offizieller Dokumentation ist es ihr kosteneffizientestes Gemini-Modell, optimiert für Anwendungsfälle mit niedriger Latenz und hohem Datenverkehr. Es soll die Leistung von Gemini 2.5 Flash in wichtigen Fähigkeitsbereichen erreichen und dabei deutlich schneller und günstiger sein.
Seine Position in der Gemini 3.1-Reihe
Die Gemini-3-Familie hat jetzt drei klar definierte Stufen. An der Spitze steht Gemini 3.1 Pro — das Schwergewicht für komplexe Reasoning-Aufgaben. In der Mitte befindet sich Gemini 3 Flash, das Pro-Level-Intelligenz mit Flash-Level-Geschwindigkeit verbindet. Und nun besetzt Flash-Lite den Bereich für hohes Volumen und Kostensensitivität.
Was das interessant macht: Flash-Lite ist keine abgespeckte Version von Flash. Es basiert tatsächlich auf der Architektur von Gemini 3 Pro, die dann speziell für Durchsatz und Latenz optimiert wurde. Diese architektonische Entscheidung spiegelt sich in den Benchmarks wider — es ist nicht nur schneller, sondern auch intelligenter, als man für den Preis erwarten würde.
Wie die Pro / Flash / Flash-Lite-Stufenlogik funktioniert
Der gestufte Ansatz betrifft nicht Features — es geht um die Zuweisung von Rechenkapazität. Pro verwendet mehr Tokens, um komplexe Probleme durchzudenken. Flash balanciert Reasoning mit Geschwindigkeit. Flash-Lite minimiert standardmäßig das interne Reasoning, aber das lässt sich anpassen.
Dieser letzte Punkt ist neu. Google hat sogenannte „Thinking Levels” eingeführt — minimal, niedrig, mittel oder hoch. Für eine einfache Übersetzungsaufgabe stellt man es auf minimal und erhält sofortige Ergebnisse. Für etwas, das mehr Genauigkeit erfordert, erhöht man es und akzeptiert eine leicht höhere Latenz und Kosten.
Ich habe das mit einem Stapel von Kundensupport-Tickets ausprobiert. Beim minimalen Thinking kamen die Antworten in unter zwei Sekunden zurück. Beim mittleren dauerte es fünf Sekunden, erfasste aber Nuancen, die der schnelle Durchlauf verpasst hatte. Die Kontrolle fühlt sich praktisch an.
Gemini 3.1 Flash-Lite Hauptfunktionen
Extrem niedrige Inferenzkosten
Der Preis beträgt $0,25 pro Million Input-Tokens und $1,50 pro Million Output-Tokens. Zum Vergleich: Gemini 3.1 Pro beginnt bei $2,00 pro Million Input-Tokens und $18 pro Million Output-Tokens für anspruchsvolle Workloads. Flash-Lite kostet für einfache Aufgaben grob ein Achtel des Pro-Preises.
Aber das überraschte mich: Es ist auch günstiger als Gemini 2.5 Flash (das bei $0,30/$2,50 lag), obwohl es leistungsfähiger ist. Das ist ungewöhnlich. Normalerweise zahlt man mehr für Upgrades.
Hoher Durchsatz und niedrige Latenz
Google gibt an, dass Flash-Lite eine Ausgabe mit 363 Tokens pro Sekunde erzeugt, und in meinen Tests stimmt das so gefühlt. Noch wichtiger ist die Zeit bis zum ersten Token — der Moment, in dem man aufhört zu warten und die Ausgabe beginnt — laut deren internen Benchmarks 2,5-mal schneller als bei Gemini 2.5 Flash, wie ihre internen Benchmarks zeigen.
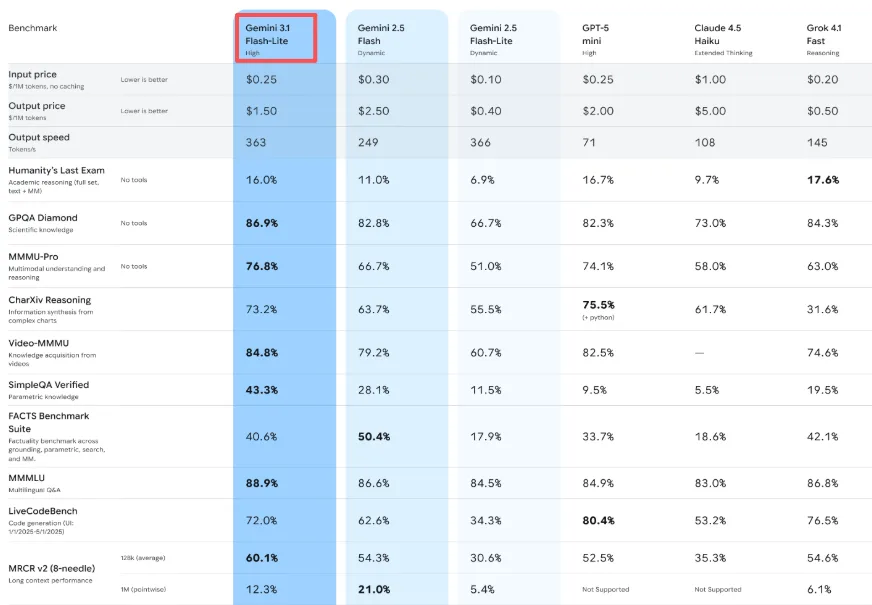
Das fiel mir am meisten auf, als ich eine einfache Content-Moderations-Pipeline aufbaute. Der Unterschied zwischen einer drei Sekunden langen Wartezeit und einer einzekunden langen klingt nicht nach viel. Aber wenn man Hunderte von Elementen verarbeitet, summiert sich diese Verzögerung. Mit Flash-Lite fühlte sich die Pipeline reaktionsschnell statt träge an.
Multimodale Eingabeunterstützung
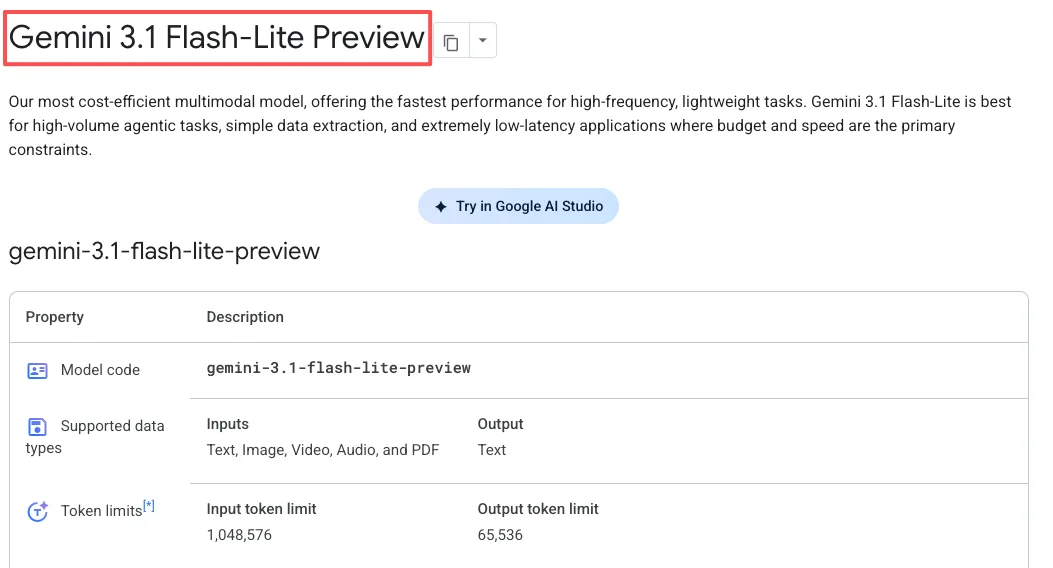
Flash-Lite verarbeitet Text, Bilder, Audio und Video. Das Kontextfenster reicht bis zu 1 Million Tokens, und es kann bis zu 64.000 Tokens als Textausgabe generieren.
Ich habe es mit einer Mischung aus Produktbildern und Beschreibungen für einen E-Commerce-Prototypen getestet. Es taggte sie konsistent und schnell — frühe Nutzer wie Whering berichteten von 100% Konsistenz beim Tagging von Artikeln in komplexen Modekategorien. Diese Art von Zuverlässigkeit ist wichtig, wenn man Systeme aufbaut, die sich keine Abweichungen leisten können.
Großes Kontextfenster
Das 1-Million-Token-Kontextfenster bedeutet, dass man ganze Dokumente, lange Gesprächsverläufe oder große Datensätze einspeisen kann, ohne sie vorher in kleinere Teile aufzuteilen. Ich nutze das volle Fenster nicht oft, aber wenn ich es tue — zum Beispiel bei der Analyse mehrseitiger PDFs — ist es der Unterschied zwischen einem reibungslosen Workflow und einem frustrierenden.
Gemini 3.1 Flash-Lite vs. Flash: Direkter Vergleich
Wann Flash-Lite verwendet werden sollte
Flash-Lite verwenden, wenn man Tausende oder Millionen ähnlicher Aufgaben ausführt. Übersetzungs-Pipelines, Content-Moderations-Warteschlangen, Sentiment-Analyse im großen Maßstab, grundlegende Datenextraktion — alles, wo die Aufgabe klar definiert ist und die Kosten pro Token wichtiger sind als tiefes Reasoning.
Ich fand auch, dass es gut als Router funktioniert. Man kann Flash-Lite verwenden, um eingehende Anfragen als „einfach” oder „komplex” zu klassifizieren und komplexe dann an Flash oder Pro weiterzuleiten. Das spart Geld, ohne dort an Qualität einzubüßen, wo es darauf ankommt.
Wann stattdessen Flash verwendet werden sollte
Wenn die Aufgabe mehrstufiges Reasoning, kreatives Problemlösen oder den Umgang mit mehrdeutigen Anweisungen erfordert, ist Flash die bessere Wahl. Es kostet doppelt so viel, ist aber auch intelligenter — besonders bei Coding-Aufgaben, bei denen es Pro in einigen Benchmarks gleichkommt oder übertrifft.
Ich habe beide bei einer Aufgabe getestet, bei der es darum ging, UI-Komponenten aus Texteingaben zu generieren. Flash-Lite konnte einfache Anfragen verarbeiten („erstelle ein Login-Formular”), hatte aber Schwierigkeiten mit vagen Anfragen („designe etwas Modernes und Sauberes”). Flash bewältigte beide.
Gemini 3.1 Flash-Lite Anwendungsfälle
KI-Agent-Routing und Aufgabenklassifizierung
Einer der saubersten Anwendungsfälle, die ich gesehen habe, ist die Verwendung von Flash-Lite als Verkehrsregler. Wenn ein Nutzer eine Anfrage einreicht, liest Flash-Lite sie, bestimmt die Komplexität und leitet sie an das entsprechende Modell weiter — Flash für mittlere Aufgaben, Pro für schwere.
Dieses Muster wird bereits in Produktionstools verwendet. Das Open-Source-Gemini-CLI verwendet Flash-Lite genau dafür, und es funktioniert, weil das Modell schnell und günstig genug ist, um diesen Routing-Schritt hinzuzufügen, ohne die Latenz oder die Kosten merklich zu erhöhen.
Hochvolumen-Chat und Support-Automatisierung
Im Kundensupport zeigen sich die Kosteneinsparungen am deutlichsten. Wenn man täglich Zehntausende von Support-Tickets bearbeitet, skaliert der Unterschied zwischen $0,25 und $2,00 pro Million Input-Tokens schnell.
Flash-Lite kann unkomplizierte Fragen beantworten, Absichten extrahieren und Tickets weiterleiten, die menschliche Aufmerksamkeit benötigen. Es wird keine komplexen technischen Probleme lösen, aber das muss es auch nicht. Es muss nur zuverlässig und schnell sein.
Content-Moderation und Tagging
Ich habe eine schnelle Test-Pipeline aufgebaut, um nutzergenerierte Inhalte zu moderieren — Spam, unangemessene Sprache und Off-Topic-Beiträge zu markieren. Flash-Lite verarbeitete etwa 500 Elemente in unter einer Minute mit konsistenter Genauigkeit.
Der Schlüssel hier ist Konsistenz. Einige Modelle driften im Laufe der Zeit oder geben bei ähnlichen Eingaben unterschiedliche Antworten. Flash-Lite blieb über wiederholte Durchläufe hinweg vorhersehbar, was wichtig ist, wenn man Systeme aufbaut, die sich jedes Mal gleich verhalten müssen.
Dokumentenvorverarbeitungs-Pipelines
Flash-Lite ist hervorragend bei der strukturierten Datenextraktion. Bei einem Stapel von Rechnungen oder Belegen kann es wichtige Felder extrahieren — Daten, Beträge, Lieferantennamen — und sie als JSON ausgeben.
Ich habe das mit einer Mischung aus PDF-Rechnungen getestet, und es hat die meisten davon sauber verarbeitet. Schwierigkeiten gab es bei minderwertigen Scans mit schlechtem Text, aber das ist eine Einschränkung der Eingabe, nicht des Modells.
Was Flash-Lite für das KI-Infrastrukturdesign bedeutet

Das gestufte Modellarchitekturmuster
Die Veröffentlichung von Flash-Lite vervollständigt das, was sich wie ein branchenübliches Muster anfühlt: ein dreistufiger Modell-Stack. Es gibt ein Schwergewicht für schwierige Probleme, eine ausgewogene Option für den täglichen Gebrauch und ein Leichtgewicht für hochvolumige, repetitive Arbeit.
Das ist nicht neu — OpenAI hat GPT-5 / GPT-5 mini, Anthropic hat Claude Opus / Sonnet / Haiku — aber Googles Implementierung ist interessant, weil die Preisunterschiede größer sind. Flash-Lite ist im Vergleich zu Pro wirklich günstig, was bestimmte Workflows wirtschaftlich rentabel macht, die es zuvor nicht waren.
Günstiger Router + starker Reasoner — warum das wichtig ist
Das Muster, das ich immer wieder sehe: Ein günstiges Modell verwenden, um zu entscheiden, mit welcher Art von Aufgabe man es zu tun hat, und dann nur bei Bedarf zu einem teureren Modell weiterleiten. Es geht dabei nicht nur ums Geldsparen. Es verbessert auch die Latenz bei einfachen Aufgaben, da man nicht darauf wartet, dass ein Schwergewichtsmodell hochfährt.
Ich habe das mit einem gemischten Stapel von 100 Aufgaben ausprobiert — halb einfach, halb komplex. Mit Flash-Lite als Router wurden die einfachen Aufgaben in Sekunden erledigt, und die komplexen wurden an Flash weitergeleitet. Die Gesamtkosten lagen etwa 40% niedriger als beim Ausführen von allem über Flash, ohne Qualitätsverlust bei den komplexen Aufgaben.
Diese Architektur funktioniert nur, wenn der Router schnell und günstig genug ist, um nicht selbst zum Engpass zu werden. Flash-Lite ist es.
Aktuelle Verfügbarkeit und API-Status
Gemini 3.1 Flash-Lite ist jetzt in der Vorschau über die Gemini API in Google AI Studio und Vertex AI verfügbar. Es ist nicht in der Consumer-Gemini-App — dies ist entwicklerfokussiert.
Vorschau-Modelle können sich ändern, bevor sie stabil werden, und sie haben strengere Rate-Limits. In der Praxis habe ich diese Limits bei normalen Tests nicht erreicht, aber wenn man eine Produktionsbereitstellung in ernsthaftem Maßstab plant, ist das etwas, das man im Auge behalten sollte.
Das Modell wird auch aktiv aktualisiert. Googles Release Notes zeigen laufende Verbesserungen bei der Befolgung von Anweisungen, der Audioeingabequalität und den Reasoning-Fähigkeiten. Das sind noch frühe Tage — es wird in den nächsten Monaten wahrscheinlich besser werden.
Ein anhaltender Gedanke
Was mich immer wieder beschäftigt, ist nicht die Geschwindigkeit oder die Kosten. Es ist die Tatsache, dass Flash-Lite bestimmte Workflows weniger wie Experimente und mehr wie Versorgungsleistungen erscheinen lässt. Wenn die Kosten niedrig genug sinken, hört man auf zu fragen: „Sollte ich KI dafür verwenden?” und beginnt zu fragen: „Wie baue ich das so, dass es skaliert?”
Diese Verschiebung — von der Neuheit zur Infrastruktur — ist der Punkt, an dem Werkzeuge anfangen, dauerhaft zu bestehen.
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt
GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing
GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten
MAI-Image-2.5 API: Was Entwickler wissen sollten