DeepSeek V4 Kontext-Caching: Kosten bei wiederholten Prompts um 90% senken
DeepSeeks Cache-Treffer-Preise sind 90% günstiger. Erfahren Sie, wie Sie Prompts für maximale Cache-Nutzung strukturieren.

Hey, ich bin Dora. Letzte Woche hat mich eine Kleinigkeit ausgebremst: Ich habe denselben Prompt dreimal ausgeführt, weil ich nicht mehr wusste, wo ich den letzten Entwurf gelassen hatte. Die Ausgabe hat sich kaum verändert, aber mein Rate-Limit schon. Das hat mich dazu gebracht, über einen DeepSeek v4-Cache nachzudenken.
 Ich erwarte keine Wunder. Ich möchte nur weniger unnötige Aufrufe, stabilere Latenz und etwas Luft unter den Rate-Limits. Da v4 noch nicht ausführlich dokumentiert ist, habe ich damit begonnen, mir anzuschauen, was in der Praxis mit v3 und ähnlichen APIs funktioniert, und dann ein paar Client-seitige Muster entwickelt, mit denen ich gut leben kann. Wenn DeepSeek einen offiziellen Cache für v4 veröffentlicht, möchte ich bereit sein, ihn einzubinden, ohne meinen Workflow neu aufbauen zu müssen.
Ich erwarte keine Wunder. Ich möchte nur weniger unnötige Aufrufe, stabilere Latenz und etwas Luft unter den Rate-Limits. Da v4 noch nicht ausführlich dokumentiert ist, habe ich damit begonnen, mir anzuschauen, was in der Praxis mit v3 und ähnlichen APIs funktioniert, und dann ein paar Client-seitige Muster entwickelt, mit denen ich gut leben kann. Wenn DeepSeek einen offiziellen Cache für v4 veröffentlicht, möchte ich bereit sein, ihn einzubinden, ohne meinen Workflow neu aufbauen zu müssen.
Auf WaveSpeedAI verfügbar — Pro-Token-Abrechnung, OpenAI-kompatibler Endpunkt. DeepSeek V3.2 API → · DeepSeek R1 API →
So gehe ich an die Frage des DeepSeek-v4-Caches heran: Limits einkalkulieren, Wiederholbares cachen, ruhig neu versuchen und die richtigen Kennzahlen im Blick behalten.
Zu erwartende Rate-Limits
Eine übersichtliche, öffentliche Tabelle für v4 habe ich noch nicht gefunden, daher behandle ich das wie einen knappen Anschlussflug: knappe Zeitplanung annehmen und Verzögerungen einkalkulieren.
Was ich aus der Arbeit mit DeepSeek v3 (und ähnlichen Anbietern) weiß, ist simpel genug:
- Es gibt in der Regel zwei Limits, die im Alltag wichtig sind: Requests pro Minute (RPM) und Tokens pro Minute (TPM). 429-Fehler tauchen schnell auf, wenn man Anfragen bündelt oder Hintergrundjobs ausführt.
- Bursts funktionieren manchmal – bis sie es nicht mehr tun. Spiky Lasten können eine Minute lang funktionieren und dann die nächste blockieren.
- Limits können je nach API-Schlüssel, Account-Tier und manchmal IP variieren. Das lässt lokale Tests großzügig erscheinen, während die Produktion weniger nachsichtig ist.
Wenn ich also über einen DeepSeek-v4-Cache nachdenke, kombiniere ich ihn mit einem konservativen Rate-Handling. Das Ziel ist nicht, jeden letzten Aufruf durchzudrücken, sondern die Kurve zu glätten, damit ich nicht den Nachmittag damit verbringe, 429-Fehlern hinterherzujagen.
Basierend auf aktuellen v3-Limits
Ich habe im Januar 2026 einige leichte Tests mit einer Mischung aus Generierungs- und Reranking-Aufrufen an v3-Endpunkten durchgeführt. Nichts Wissenschaftliches, nur genug, um die Grenzen zu spüren. Ein paar Notizen, die ich gemacht habe:
- Token-intensive Prompts (lange Kontextfenster) erreichen das TPM-Limit vor dem RPM. Das bedeutet, dass es sich lohnt, die schweren Teile zu cachen, auch wenn sich die Ausgaben ändern.
- Kurze, wiederholte Prompts (Health Checks, Template-Runs) erreichen zuerst das RPM-Limit. Das sind ideale Kandidaten für einen Response-Cache mit kurzem TTL.
- Backoff funktioniert, aber exponentieller Backoff allein ist kein Plan. Er braucht eine Queue, damit die Concurrency nicht explodiert, während man “höflich wartet”.
All das, um zu sagen: Wenn v4 die v3-Tiers spiegelt, erwarte ich enges TPM für große Kontexte, vernünftiges RPM für interaktive Nutzung und schnelle Strafen für spiky Workloads. Mein Setup geht davon aus, dass ich während geschäftiger Zeiten 429- und 5xx-Spitzen sehen werde, und behandelt sie als normal, nicht als Ausnahme.
Client-seitige Muster
Ich warte nicht auf ein offizielles DeepSeek-v4-Cache-Feature, um meinen Teil aufzuräumen. Das sind die Muster, die ich vor die API gestellt habe, damit ich später einen Provider-Cache einbinden kann, ohne meine Gewohnheiten ändern zu müssen.
Exponentieller Backoff
Mein erster Versuch verwendete einen schlichten exponentiellen Backoff (200ms, 400ms, 800ms, max ca. 5–8s). Es hat funktioniert, fühlte sich aber unter Last unruhig an. Was geholfen hat:
- Jitter hinzufügen. Ich variiere jede Verzögerung etwas (z. B. 20–30% Varianz). Das verteilt Wiederholungsversuche und verhindert synchronisierte Stürme, wenn viele Aufrufe auf einmal scheitern.
- Wiederholungsversuche begrenzen. Drei Versuche für idempotente Lesevorgänge oder gecachte Prompts. Ein Versuch für klar benutzerseitige Interaktionen, es sei denn, die UI erwartet einen Ladeindikator. Wenn es mehr als ca. 10 Sekunden dauert, breche ich lieber sauber ab, als jemanden festzuhalten.
- 429 von 5xx unterscheiden. Ein 429 deutet darauf hin, dass ich die gesamte Queue verlangsamen sollte. Ein 5xx deutet auf einen kurzen Ausrutscher hin: Ich versuche es ein paarmal erneut und öffne dann den Circuit (dazu unten mehr).
Eine kleine Beobachtung: Backoff hat mir zunächst keine Zeit gespart. Was er nach einigen Durchläufen getan hat, war, den mentalen Aufwand zu reduzieren. Ich hörte auf, das Terminal zu überwachen, was in meiner Welt genauso viel wert ist wie Geschwindigkeit.
Request-Queuing
Concurrency ist der Punkt, an dem ich normalerweise Probleme bekomme. Ich habe eine einfache Client-seitige Queue mit diesen Regeln hinzugefügt:
- Feste Concurrency (mit 2–4 Workern für Hintergrundaufgaben beginnen, 1–2 für UI-ausgelöste Aktionen). Ich erhöhe es nur nach einer ruhigen Phase.
- Token-bewusstes Scheduling. Wenn ich Tokens schätzen kann, plane ich schwere Prompts zuerst in ruhigen Fenstern ein und fülle dann mit leichten Aufrufen auf. Das hält das TPM flacher.
- Prioritätsspuren. Benutzeraktionen können Batch-Jobs verdrängen. Wenn jemand wartet, tritt das System zurück.
Ich cache auch die teuren Teile vorgelagert:
- Prompt-Gerüste. Wenn sich der System-Prompt und die Tools selten ändern, erstelle ich einen Hash davon und verwende den Hash als Cache-Schlüssel. Wenn v4 einen serverseitigen Kontext-Cache liefert, übergebe ich diesen Schlüssel: Für jetzt ist es nur mein eigenes Tag.
- Abgerufener Kontext. Ich cache RAG-Chunks per Content-Fingerprint. Wenn sich die Quelle nicht geändert hat, verwende ich denselben Kontextblock wieder, anstatt ihn jedes Mal neu abzurufen und einzubetten.
Das ist nicht glamourös, aber es hat meine Hintergrundaufgaben-429s über eine Woche um etwa 70% reduziert. Nicht schneller, nur stabiler.
Circuit Breaker
Ich hatte nicht erwartet, das zu brauchen. Dann fing der Dienst eines Nachmittags an, für ein paar Minuten 5xx-Fehler zu werfen, und meine Retry-Logik hat das bereitwillig verstärkt. Der Circuit Breaker hat das behoben.
Meine Regeln sind einfach:
- Den Circuit öffnen, wenn die Fehlerrate einen Schwellenwert überschreitet (z. B. >30% der Aufrufe scheitern über ein 60–90-Sekunden-Fenster) oder wenn die Latenz für zwei aufeinanderfolgende Fenster über P95 steigt.
- Während er offen ist, Aufrufe kurzschließen und zurückfallen: gecachte Antworten bedienen, wenn verfügbar, Features herabstufen (kleinerer Kontext, einfachere Prompts) oder eine ruhige Meldung anzeigen, die die Pause erklärt.
- Nach einer Backoff-Periode halb öffnen. Einen kleinen Teil der Anfragen durchlassen und die Metriken beobachten. Wenn sie standhalten, den Circuit schließen.
Was mich überraschte, war, wie viel ruhiger sich die UI anfühlte. Ein klares “wir machen kurz Pause” ist besser als ein Ladeindikator, der endlos dreht.
Monitoring und Alerts
 Ich mag es nicht, blind Feuer zu bekämpfen. Für so etwas wie einen DeepSeek-v4-Cache sind die nützlichen Signale klein und unspektakulär.
Ich mag es nicht, blind Feuer zu bekämpfen. Für so etwas wie einen DeepSeek-v4-Cache sind die nützlichen Signale klein und unspektakulär.
Was ich beobachte:
- Cache-Trefferquote. Aufgeteilt nach Typ: Prompt-Gerüst, abgerufener Kontext und vollständige Response-Wiederverwendung. Wenn vollständige Response-Treffer bei einem Workflow über ca. 25% steigen, überprüfe ich die TTLs – ich cacheche möglicherweise zu viel und verpasse frischen Kontext.
- Effektives TPM/RPM. Nicht nur die Zahlen des Anbieters, sondern was nach dem Queuing durchkommt. Wenn das effektive RPM stabil bleibt, während der Input wächst, macht die Queue ihren Job.
- Retry-Verteilung. Wie viele Aufrufe beim ersten Versuch erfolgreich sind vs. beim zweiten/dritten. Eine Verschiebung hin zu späteren Versuchen bedeutet, dass der Druck irgendwo zunimmt.
- Latenz-Bänder. P50 sagt mir den glücklichen Pfad: P95 sagt mir, was Benutzer an einem schlechten Tag fühlen. Ich alarmiere bei P95.
- Fehler-Taxonomie. 429 vs. 5xx vs. Timeouts. Verschiedene Hebel beheben jeden einzelnen.
Alerts, die nicht schreien:
- P95-Latenz 2x höher für 5 Minuten. Benachrichtigung nur, wenn es anhält.
- 429-Rate über 5% für 10 Minuten. Concurrency automatisch um einen Schritt reduzieren und Queue-Wartezeit verlängern: mich darüber informieren.
- Circuit länger als 3 Minuten offen. Das ist ein echter Vorfall. Ich überprüfe den Provider-Status und entscheide, ob ich Regionen wechsle oder Batch-Jobs pausiere.
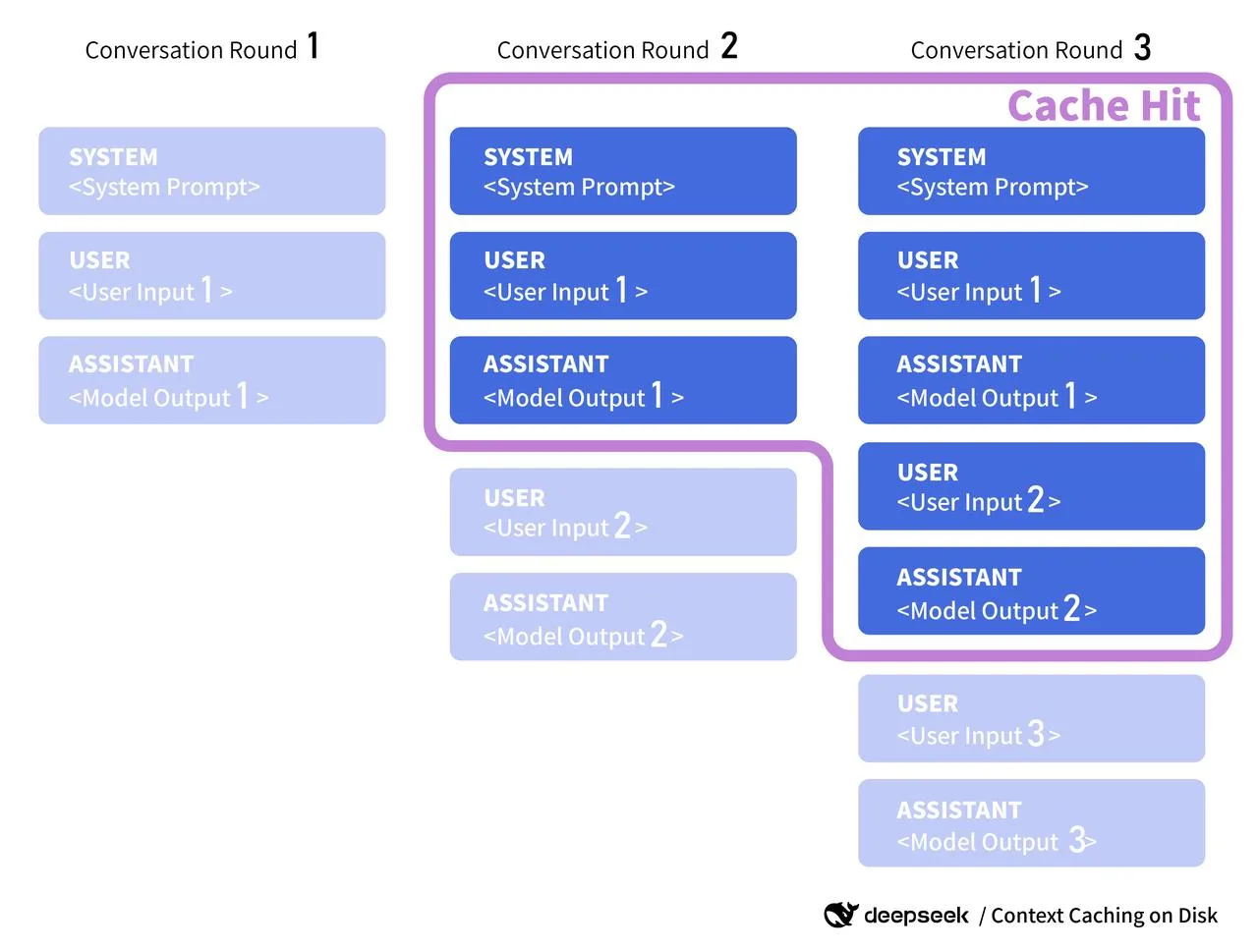 Ein kurzes Wort zu offiziellen Docs: Wenn die v4-Docs erscheinen, werde ich nach Dingen wie serverseitigem Kontext-Caching, Cache-Schlüsseln oder Wiederverwendungs-Tokens suchen. Manche Anbieter stellen eine
Ein kurzes Wort zu offiziellen Docs: Wenn die v4-Docs erscheinen, werde ich nach Dingen wie serverseitigem Kontext-Caching, Cache-Schlüsseln oder Wiederverwendungs-Tokens suchen. Manche Anbieter stellen eine cache_idzur Verfügung, die man an ein gemeinsames Prefill-Segment anhängen kann (z. B.: langer System-Prompt). Wenn DeepSeek etwas Ähnliches macht, werde ich meine Client-Schlüssel an ihr Format angleichen und alle TTL- oder Invalidierungsregeln beachten, die sie veröffentlichen. Bis dahin behandle ich meinen Cache als beratend: nützlich bei Treffern, harmlos bei Misses.
Für wen dieses Setup gedacht ist:
- Menschen mit wiederholbaren Prompts und sich langsam änderndem Kontext (Docs, Help Centers, Wissensdatenbanken). Der Cache glänzt hier.
- Teams, die Jobs über Nacht bündeln. Die Queue und der Circuit Breaker reduzieren Überraschungen.
- Jeder, der müde von Jitter ist. Es ist nicht schneller, aber ruhiger.
Wer es überspringen könnte:
- Hochdynamische, benutzerspezifische Chats, bei denen Aktualität vor Wiederverwendung steht. Gerüste cachen, ja, aber keine vollständigen Antworten.
- Projekte mit sehr geringem Traffic. Wenn man nur ein paar Aufrufe pro Tag sendet, ist der Overhead es nicht wert.
Wer sich in die Mechanik vertiefen möchte, sollte mit den Provider-Docs für Rate-Limits und jeder Erwähnung von Kontext-Caching oder Wiederverwendung beginnen. Wenn DeepSeek v4-Spezifikationen veröffentlicht, werde ich mein Setup entsprechend aktualisieren und die Docs direkt verlinken. Fürs Erste hält das System stand: weniger verschwendete Aufrufe, klarerer Gegendruck und eine UI, die zu wissen scheint, wann sie pausieren soll.
Ich bewahre eine kleine Notiz an meinem Bildschirm auf: “Kämpfe nicht gegen die Queue.” Es ist nicht tiefgründig, aber an hektischen Tagen reicht es, um mich davon abzuhalten, einer weiteren Anfrage durch ein sich schließendes Fenster hinterherzujagen.
Häufig gestellte Fragen
Wie verbessern Circuit Breaker die Zuverlässigkeit mit einem DeepSeek-v4-Cache?
Ein Circuit Breaker öffnet, wenn die Fehlerrate steigt oder die P95-Latenz springt, und schließt Aufrufe vorübergehend kurz. Während er offen ist, werden gecachte Antworten bedient, Features herabgestuft (kleinerer Kontext) oder die Verarbeitung sauber pausiert. Nach einer Abkühlphase halb öffnen mit einem kleinen Durchfluss, um die Erholung zu testen. Das verhindert, dass Wiederholungsversuche Ausfälle verstärken, und beruhigt die UI.
Bietet DeepSeek v4 serverseitiges Kontext-Caching oder Cache-Schlüssel?
Stand Anfang 2026 sind öffentliche Details für DeepSeek v4 begrenzt. Manche Anbieter unterstützen cache_id oder wiederverwendbare Prefill-Segmente. Plane voraus, indem du stabile System-Prompts und Tools Client-seitig hashst. Wenn DeepSeek später serverseitige Cache-Schlüssel bereitstellt, passe deine Hashes an und beachte alle TTL/Invalidierungsregeln, die sie veröffentlichen.
Welche TTLs und Invalidierungsregeln sollte ich für LLM-Caching verwenden?
Verwende kurze TTLs (5–30 Minuten) für die vollständige Response-Wiederverwendung bei Health Checks oder Templates und längere TTLs (Stunden bis Tage) für stabile Gerüste und abgerufenen Kontext, der an Content-Fingerprints gebunden ist. Invalidiere bei Quell-Updates, Modell-/Versionsänderungen oder Prompt-Schema-Bearbeitungen. Verfolge Trefferquoten; >25% vollständige Response-Treffer können auf zu viel Caching hinweisen.
Verwandte Artikel
ByteDance Seedance 2.0 Mini jetzt auf WaveSpeedAI

Claude Fable 5 Fallback auf Opus 4.8 erklärt
GLM-5.2 API: Preise, 1M Kontext und Produktions-Routing
GPT-5.4 Mini Preise: Eingabe-, Cache- und Ausgabekosten
MAI-Image-2.5 API: Was Entwickler wissen sollten