GPT-5.6 API Guide: Limited Preview Checklist
GPT-5.6 API guide for builders: limited preview access, Sol/Terra/Luna tiers, pricing snapshot, Codex access, and checks before integration.

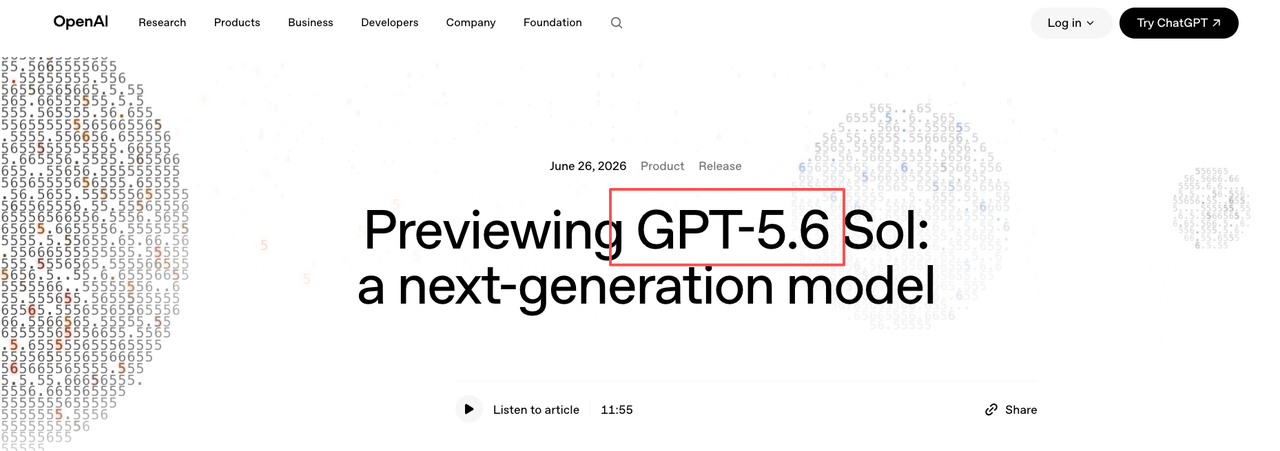
Hey, it’s Dora, still. I would not create a gpt-5.6-sol config entry today. Not because GPT-5.6 is uninteresting. It is. But on July 2, 2026, the public state is still limited preview. API and Codex access are only for select trusted partners and organizations.
That puts the GPT-5.6 API in a different bucket from a normal model migration. This is not “swap the model ID and run staging.” This is “prepare the fields, leave blanks where the docs are still blank, and do not let preview excitement leak into production config.”
Small thing. Saves cleanup later.
GPT-5.6 API Status Today
Limited preview and trusted partner access
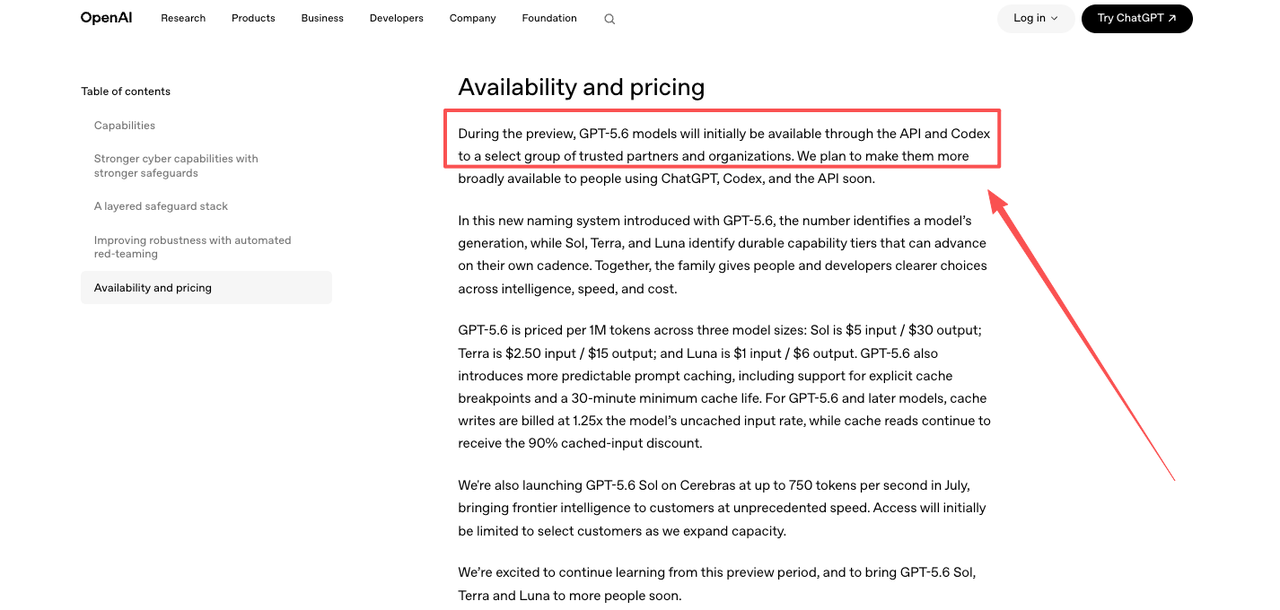
OpenAI announced GPT-5.6 on June 26, 2026. The official GPT-5.6 Sol announcement says GPT-5.6 models will initially be available through the API and Codex to select trusted partners and organizations. That is the part I would pin at the top of any internal rollout doc.
Limited preview means limited preview. Not all API accounts. Not all regions. Not every dashboard. Not every team that wants to start testing by Friday.
If the model is not visible in the account, the integration status is “waiting.” Not “blocked by engineering.”
API and Codex availability boundaries
I would check API and Codex access separately.
A preview partner may get one surface before another. A platform team may see an account note before the model appears in the dashboard. A Codex workflow may not map cleanly to the same model availability as a direct API call.
The OpenAI models page currently marks GPT-5.6 as preview access for select trusted partners. That is enough to plan around. It is not enough to write hardcoded assumptions.
What Is Confirmed vs What Must Be Checked
Confirmed: Sol, Terra, Luna, preview access, pricing snapshot
The confirmed public layer is narrow.
| Field | Current public status |
|---|---|
| Model family | GPT-5.6 |
| Tiers | Sol, Terra, Luna |
| Release | June 26, 2026 announcement |
| Access | Limited preview |
| Initial surfaces | API and Codex for select trusted partners and organizations |
| Pricing | Public snapshot available |
| Prompt caching | New GPT-5.6-and-later behavior described |
That is the stable part of the note.
Everything else goes into a “check before build” column. I would keep it visible. People forget what is unknown once a model has a name.
Must verify: model IDs, rate limits, account eligibility, regions
These fields still need confirmation before integration work starts:
- exact model IDs
- dashboard visibility
- organization eligibility
- rate limits
- supported regions
- data residency behavior
- Codex availability
- batch or priority support
- billing visibility
- prompt caching behavior in actual usage
- safety review requirements
I would not infer model IDs from naming patterns. Preview names are not infrastructure contracts. They are labels until the API accepts them.
Sol, Terra, and Luna at a Glance
Tier positioning without workload guarantees
Sol, Terra, and Luna are useful planning names.
They do not tell me whether a support agent improves. They do not tell me whether a JSON extractor stops breaking. They do not tell me whether a Codex task completes with fewer retries.
Here is how I would map them before access expands:
| Tier | Planning use |
|---|---|
| GPT-5.6 Sol | High-value reasoning, coding, agentic, and analysis evals |
| GPT-5.6 Terra | Balanced product workloads where cost still matters |
| GPT-5.6 Luna | Higher-volume paths where latency and unit cost matter more |
When to prepare evals before access expands
I would prepare evals now if the product already depends on the OpenAI API.
The set should include real production prompts, not clean examples. Add long-context cases. Add structured output tasks. Add tool-use tasks. Add prompts that previously caused manual overrides. Add safety-sensitive requests.
Then leave the GPT-5.6 result cells empty. Looks unfinished. Correctly unfinished.
Pricing Snapshot and Update Policy
Token prices and prompt caching as of 2026-07-02
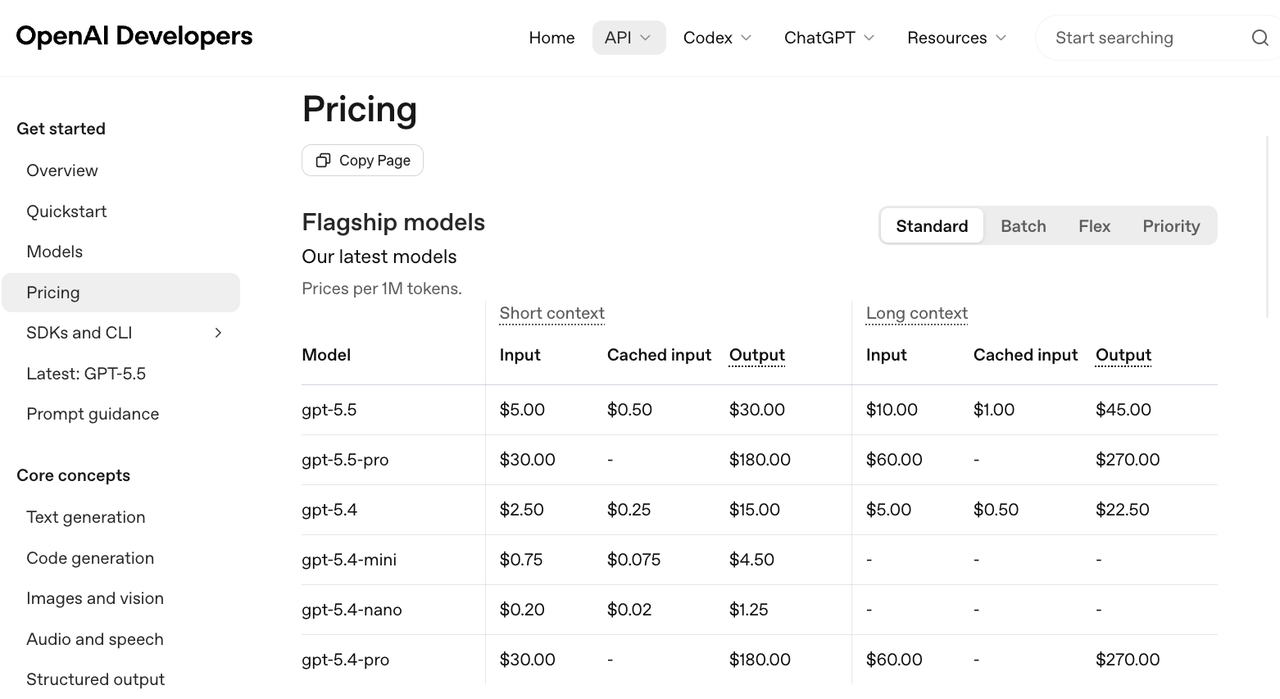
As of July 2, 2026, OpenAI’s announcement lists this GPT-5.6 pricing snapshot per 1M tokens:
| Model | Input | Output |
|---|---|---|
| GPT-5.6 Sol | $5 | $30 |
| GPT-5.6 Terra | $2.50 | $15 |
| GPT-5.6 Luna | $1 | $6 |
The same announcement says GPT-5.6 introduces explicit cache breakpoints and a 30-minute minimum cache life. Cache writes are billed at 1.25x the uncached input rate. Cache reads keep the 90% cached-input discount.
That goes into planning. Not final deployment math.
Before launch, I would re-check the OpenAI API pricing page. Pricing pages are living documents. Internal spreadsheets are where old prices go to retire badly.
Why teams must re-check official pricing before deployment
For the internal model registry, I would store:
- public tier name
- exact model ID
- input price
- output price
- cached write rule
- cached read discount
- eligible processing modes
- verification date
- source URL
- owner
No date, no trust. That rule is irritating until the first pricing update. Then it becomes obvious.
Integration Readiness Checklist
Dashboard access, API docs, billing, monitoring
I would not open implementation tickets until these are visible or confirmed:
- the model appears in the API dashboard
- a test project can call it
- billing logs show usage
- rate limits are known
- logs capture model ID, latency, tokens, cache use, cost, errors, and retries
- fallback behavior is defined
- evals compare GPT-5.6 against the current production model
The GPT-5.6 API should enter the registry before it enters production code.
That sounds bureaucratic. It is mostly just making sure the system knows what it is calling.
Safety checks and cyber-use constraints
GPT-5.6 also has a safety review surface. If the workload touches code execution, autonomous agents, vulnerability analysis, security triage, or dual-use cyber tasks, I would read the GPT-5.6 Preview System Card before routing anything real. Not as a compliance ritual.
As a way to know which requests need stricter gates before someone discovers the limit through an incident.
FAQ
Can teams use GPT-5.6 in production today?
Only teams with preview access can test the GPT-5.6 API today. Production use still depends on account access, model visibility, eval results, billing checks, and safety review.
What should be verified before integration work starts?
Model IDs, dashboard access, account eligibility, rate limits, supported regions, pricing, Codex availability, logging, fallback behavior, and safety constraints.
Should pricing snapshots go into an internal model registry?
Yes. With a verification date. Without that date, the number is just folklore with a dollar sign.
What happens if preview access changes?
The registry status changes. New production usage pauses until model IDs, pricing, limits, evals, and safety checks are refreshed. Preview access can move. Production assumptions should not move silently.
Conclusion
The GPT-5.6 API is worth preparing for. I would prepare the registry. I would prepare evals. I would prepare pricing fields, cache fields, Codex boundaries, fallback paths, and safety gates. I would not guess the missing pieces.
That is where my data ends.
Previous posts:
Related Articles

GPT-5.6 Sol vs Terra vs Luna for Production

Grok 4.5 API Watch: Availability and Migration Checks
Models.dev vs Portkey Models: Metadata vs Gateway Catalogs

Models.dev API: Routing, Pricing, and Capability Checks

What Is Models.dev? Pricing and Capability Data
