為什麼HappyHorse-1.0突然登頂影片排行榜第一名?
HappyHorse-1.0在沒有公開團隊的情況下登上Artificial Analysis排行榜第一。深入解析Elo評分為何以影片品質而非品牌知名度決勝負,以及這對開發者意味著什麼。

嘿,大家好,我是 Dora。我數了一下,這週在我的動態消息裡,有多少人問過類似「HappyHorse 到底是什麼鬼?」這種問題。六次。六個獨立的討論串。而且每一個都附帶了略有不同的傳言——有人說它是 WAN 2.7,有人說是 ByteDance 的秘密發布,也有人說是阿里巴巴出的東西。沒有人確切知道。但所有人都同意的一件事是:它在 2026 年 4 月 7–8 日前後出現在 Artificial Analysis 影片排行榜,並立即奪下文字轉影片和圖片轉影片的第一名。
這是事實。之後的一切——誰建造了它、權重何時公開、它是否還能保持第一——都仍懸而未決。
這篇文章要講的是:這份排行榜實際上在衡量什麼、為什麼一個無名模型能合理地登上榜首,以及身為開發者,你應該如何、又不應該如何運用這些資訊。
Artificial Analysis 影片競技場的運作方式
在你信任一個排名之前,你需要先了解這個排名在衡量什麼。Artificial Analysis 影片競技場並非由模型開發者自行提交分數的基準測試——它是一個盲測用戶投票系統。
使用者看到的(以及看不到的)
你進入競技場,系統會顯示兩段由相同文字提示或輸入圖片所生成的影片,然後你選擇你比較喜歡哪一段。你不知道哪個模型生成了哪段影片。沒有標籤,沒有背景資訊,只有兩段影片。
Artificial Analysis 直接如此描述:「用戶在不知道哪個模型生成了哪段影片的情況下,比較由相同文字提示生成的兩段影片。」這才是關鍵所在。沒有自我申報,沒有開發者提供的基準,沒有行銷頁面干擾結果。
Elo:訊號可靠,但並非無懈可擊
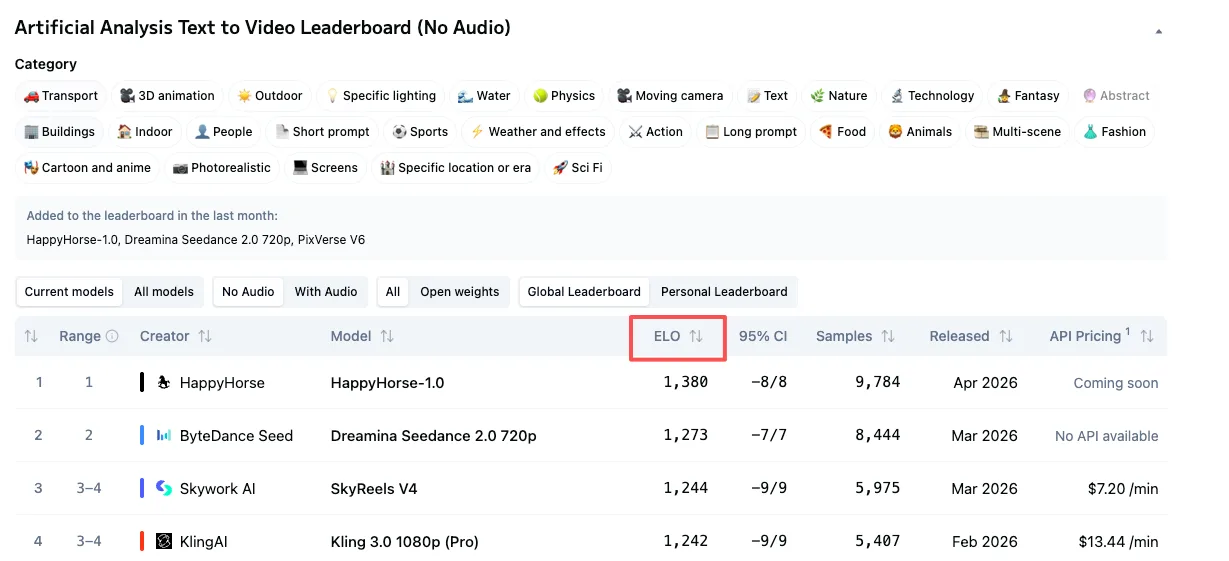
排名採用 Elo 系統——這套方法借鑑自競技象棋。每當兩個模型在投票中對決,勝者獲得 Elo 積分,敗者失去一些積分。Elo 積分高的模型,代表它在與其他模型的對決中,勝出次數持續多於敗出次數。
Elo 分數越高,代表該模型被更頻繁地選擇。這是一個真實的訊號。它基於數千個真實的人類選擇,而非合成測試、精挑細選的範例,或是模型說明卡。
投票數與樣本數:人們常常略過的部分
關於新進者的 Elo,有一件事需要注意。成熟的模型如 Seedance 2.0 背後有數千票支撐其分數——Seedance 2.0 在文字轉影片類別有超過 7,500 個投票樣本。HappyHorse 的樣本數目前尚未公開細分。投票數越多 = 分數越穩定。投票對決次數較少的新模型,每一票新投票都可能造成更大的分數波動。

隨著更多投票湧入,這些數字將會變動。變動的方向目前未知。在你根據一個才兩天大的數字做出產品線決策之前,請記住這一點。
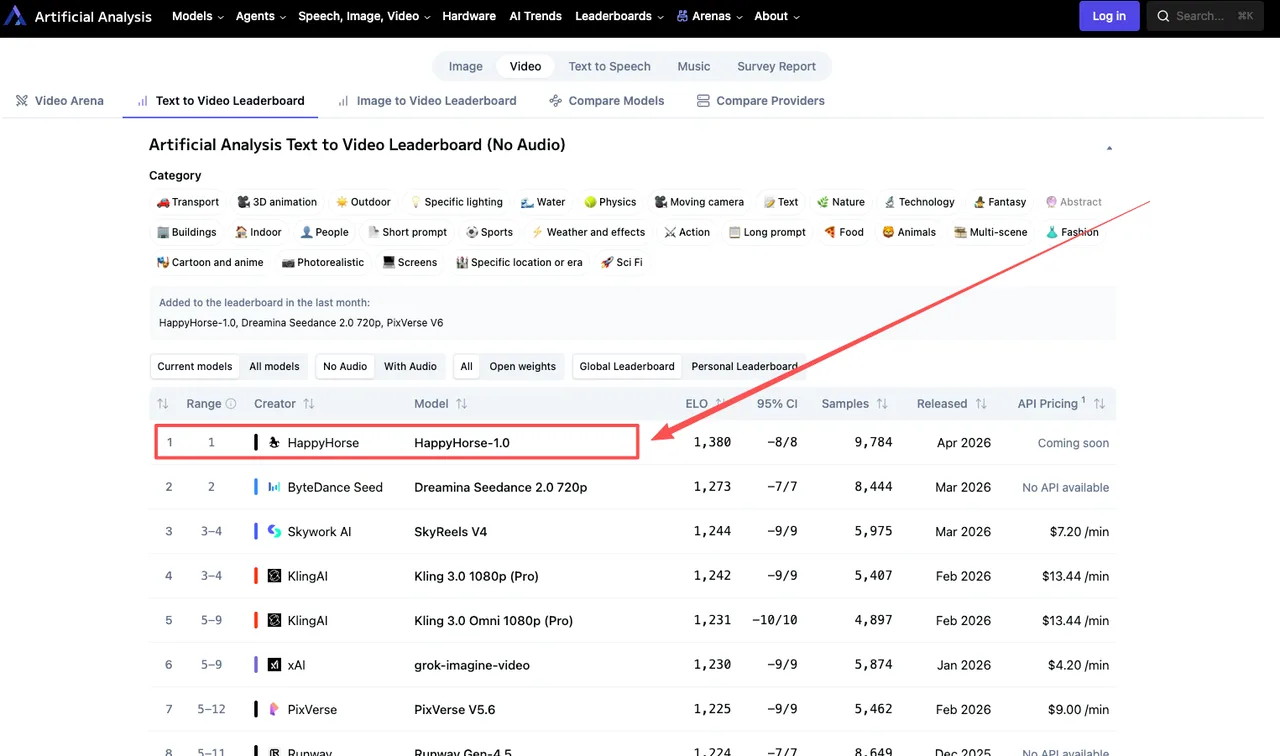
HappyHorse-1.0 的實際得分情況
以下是從 2026 年 4 月初的即時排行榜擷取的現有數據:
文字轉影片(無音訊): HappyHorse-1.0 以 1357 的 Elo 分數領先,其次是 Dreamina Seedance 2.0 的 1273、SkyReels V4 的 1244,以及 Kling 3.0 Pro 的 1243。
圖片轉影片(無音訊): HappyHorse-1.0 以 1402 的 Elo 領先,Seedance 2.0 為 1355,Grok Imagine Video 為 1331。
圖片轉影片(無音訊)類別中 84 分的差距並不小。60 分的 Elo 差距意味著一個模型在盲測對決中贏得約 58–59% 的勝率——這是有意義的差距。80 分以上的差距則更為顯著。
音訊項目的情況截然不同
在有音訊的圖片轉影片類別中,HappyHorse-1.0 目前以 1160 的 Elo 領先,Dreamina Seedance 2.0 為 1158。2 分的差距屬於統計誤差範圍。而在有音訊的文字轉影片類別中,Seedance 2.0 以 1220 領先,HappyHorse 為 1215。
因此,整體情況比「HappyHorse 全面稱霸」更為微妙。它在排除音訊的情況下以顯著差距位居第一。但當音訊品質加入考量時,它與 Seedance 2.0 基本上不相上下。
架構聲稱說明了什麼(又無法證明什麼)
多個描述 HappyHorse 的網站表示,它採用單流 Transformer 架構,參數量約為 150 億,聲稱在單張 H100 上生成一段 1080p 影片的速度約為 38 秒。截至 2026 年 4 月 8 日,這些 HappyHorse 網站上的 GitHub 和 Hugging Face 連結均指向「即將推出」的頁面,或回傳 404 錯誤。權重並無法公開下載。
這些架構聲明是合理的——但尚未經過驗證。目前沒有任何獨立的技術審計確認過其參數量、架構類型或推理速度。請將這些視為宣稱,而非已確認的事實。
為何無名模型能在 Elo 中獲勝
這正是那些以為排行榜會獎勵品牌知名度的人感到困惑的地方。
Elo 不在乎是誰建造了這個模型。 它不知道你是 Google 還是一個三人小團隊。Artificial Analysis 的影片競技場使用 Elo 評分系統,完全依賴真實用戶的盲測投票。它忽略參數量、論文或炒作——它只在乎一個問題:「看完兩段影片後,你更喜歡哪一段?」
這其實是一個優點。這是少數幾個資金充裕的品牌無法藉由發表有利論文來買到更好結果的評估系統之一。
這種模式以前發生過
匿名發布前的預覽已成為中國 AI 生態系統的一種慣例。2026 年 2 月的 Pony Alpha 事件是最清晰的先例——一個神秘模型出現在 OpenRouter,引發了一場猜謎遊戲,最後證實是 Z.ai 的 GLM-5 在進行秘密壓力測試。HappyHorse 符合這個模板:無名、發布時沒有團隊署名、首頁的 GitHub 連結顯示「即將推出」、輸出品質強勁。
無論它是某個大型實驗室進行的靜默能力測試,還是一個真正的新團隊——這目前仍懸而未決。但 Elo 分數本身,無論如何都是真實的。
Elo 無法隱藏的局限性
Elo 只衡量一件事:在盲測比較中,真實用戶更喜歡哪段影片。它不衡量模型在批量處理中的表現,不衡量 API 正常運行時間、高負載下的延遲,也不衡量當你大規模生成(而非精挑細選競技場範例)時輸出品質是否穩定。
一個模型可能有出色的盲測結果,卻完全無法在生產環境中使用。這是兩個截然不同的問題。
「排行榜第一」對開發者而言不意味著什麼
如果你正要根據 HappyHorse 目前的排名做出工具決策,我建議你放慢腳步。
沒有 API,就沒有生產環境的使用機會
有三件事能讓 HappyHorse 從「排行榜條目」變成「真實選項」:一個包含實際權重和推理程式碼的 GitHub 儲存庫、一個附有可驗證細節和授權條款的 HuggingFace 模型卡,或者一個附有文件化定價的 API 端點。截至撰文時,這三者均不存在。
如果你無法呼叫它,你就無法使用它。排行榜排名是關於輸出品質的資訊,而非可用性。
音訊表現改變了考量依據
如果你的工作流程需要音訊——配音、環境音、唇形同步——HappyHorse 的領先優勢基本上就消失了。在有音訊的類別中,它與 Seedance 2.0 的差距在文字轉影片為 5 分,在圖片轉影片為 2 分。這些差距在正常的 Elo 變異範圍內屬於平手。
對於需要音訊的使用情境,目前實際的競爭格局看起來像是 Seedance 與 HappyHorse 並列榜首,SkyReels V4 則落後一個明顯的差距。
團隊可信度:未知
Artificial Analysis 在將 HappyHorse 加入競技場時,將其描述為「匿名」模型。部分與該模型相關的網站聲稱,它由淘天集團(阿里巴巴)未來生命實驗室團隊打造,由前 Kling AI 負責人張迪帶領。另一項分析則將其與 Sand.ai 一個名為 daVinci-MagiHuman 的開源項目聯繫起來,兩者規格幾乎完全相同。兩種說法均未獲官方確認。
對於生產工具而言,團隊可信度對於錯誤修復、模型更新和長期支援至關重要。對於匿名模型,你無法獲得這種保障。
開發者應如何解讀影片排行榜
具體的框架,而非抽象的建議。
將 Elo 作為品質訊號,而非採購決策的依據。 如果一個模型持續在與資金充裕的競爭對手的盲測中勝出,這確實說明了一些關於其輸出品質的真實資訊。這值得關注。但它並不能告訴你任何關於 API 條款、定價、延遲,或者團隊是否會回應錯誤報告的資訊。
實際可用的排行榜從第三名開始。 目前按 Elo 排名品質最高的兩個模型——HappyHorse 和 Seedance 2.0——均無法透過公開 API 使用。下一梯隊——SkyReels V4、Kling 3.0、PixVerse V6——才是目前實際整合決策的發生地。
何時應該及早關注排行榜新進者。 如果一個模型以顯著的 Elo 差距高居榜首、有已驗證的 GitHub 發布,且文件存在——值得立即測試。如果它高居榜首但 GitHub 顯示「即將推出」——設定兩週後的提醒再來查看。不要為了虛無縹緲的東西重組你的產品線。
直接查看即時排行榜,而非文章。 包括這篇。Elo 分數每天都在變動。我在這裡引用的數字反映的是 2026 年 4 月初的情況,當你閱讀此文時,這些數字已經有所變化。
常見問題
HappyHorse-1.0 在 Artificial Analysis 排行榜上存在多久了?
Artificial Analysis 於 2026 年 4 月 7 日宣布新增此模型,將其描述為一個新加入的匿名模型。截至撰文時,它上線大約 48 小時,投票數仍在累積中。
一個模型能無限期地保持 Elo 第一嗎?
通常不行。隨著更新的模型進入競技場並累積更多投票,排名會發生變化。一個在第二天以小樣本量稱霸的模型,隨著投票池加深,其分數可能會穩定在較低的位置。分數始終是即時的——它反映的是當前數據,而非永久判斷。
Artificial Analysis 是否驗證提交到競技場的模型的身份?
Artificial Analysis 尚未公布模型提交的正式驗證政策。他們在宣布 HappyHorse-1.0 時將其描述為「匿名」,這暗示該團隊的身份是他們知道但未公開披露的。他們是否對提交的模型進行任何技術審計,目前尚無文件記錄。
我應該僅根據 Elo 分數選擇模型嗎?
不。Elo 告訴你的是盲測比較中的視覺偏好。它對 API 可用性、每次生成的成本、延遲、正常運行時間、內容政策,或者模型是否能在三個月後繼續存在,完全隻字未提。它只是眾多訊號之一。
除排行榜排名外,還有哪些指標值得關注?
API 存取和文件;每次生成或每分鐘的定價;在你的使用頻率下的延遲和冷啟動行為;Elo 分數背後的樣本數(投票越多 = 越穩定);以及該團隊是否有維護和更新模型的往績。WaveSpeed 模型比較頁面追蹤了可存取模型的若干這些維度,如果你需要一個起點的話。
目前情況就是如此。一個團隊不明、沒有公開權重的模型,剛剛以難以忽視的差距登上了我們所擁有的最具可信度的影片基準測試的榜首。它是否能成為真正的生產選項,完全取決於未來幾週內會有什麼東西被發布出來。
值得持續關注。但現在還不值得採取行動。
更多內容即將推出。
在 WaveSpeedAI 上試用 HappyHorse-1.0
HappyHorse-1.0 現已在 WaveSpeedAI 上提供:
相關文章:
