Claude Mythos 程式碼效能:對 AI 開發工作流程的意義
據報導,Claude Mythos 的程式碼得分遠高於 Opus 4.6。以下是這對 2026 年打造 AI 程式碼代理程式的開發者意味著什麼。

當 Fortune 以簡短醒目的標題報導 時,所有人的目光都集中在資安漏洞上:Anthropic 意外將近 3,000 個內部檔案暴露在外,其中包括一篇吹捧其未發布模型的草稿部落格文章。但作為一個每天都在使用 Claude 進行開發的人,真正吸引我注意的不是洩露事件本身——而是那份草稿中悄悄埋藏的、關於程式碼撰寫效能的爆炸性說法。
在 WaveSpeedAI 上即刻可用 — 按 token 透明計費,OpenAI 相容端點。 Claude Opus 4.7 API → · Claude Sonnet 4.6 API → · 開啟 Playground →
在這篇文章中,我 Dora 和各位不會追逐炒作或資安恐慌,而是直接切入對開發者和正在交付真實產品的團隊真正重要的事:清楚說明我們對 Claude Mythos / Capybara 程式碼撰寫能力已知和未知的部分。
洩露草稿對 Claude Mythos 程式碼撰寫效能的說法
洩露草稿中的精確說法:「與我們之前最佳的模型 Claude Opus 4.6 相比,Capybara 在軟體程式碼撰寫、學術推理和網路安全等測試中獲得了顯著更高的分數。」
這就是 Anthropic 以書面形式說明程式碼撰寫效能的全部內容。沒有 SWE-bench 百分比、沒有 Terminal-Bench 分數、沒有比較表。「顯著更高」這個措辭才是真正的訊號——模糊,但並非毫無意義。

就背景而言,Opus 4.6 目前在公開可用的模型中,於 SWE-bench Verified(約 80.8%)、Terminal-Bench 2.0 和 Humanity’s Last Exam 上均領先。Anthropic 的官方發言人確認該模型在「推理、程式碼撰寫和網路安全方面有實質性進展」。訓練已完成,早期存取測試正在進行,而程式碼撰寫明確是三個主要能力維度之一。其他一切都是推斷。
為何程式碼撰寫是這個模型等級最重要的能力
Terminal-Bench 2.0 背景與當前 Opus 4.6 分數
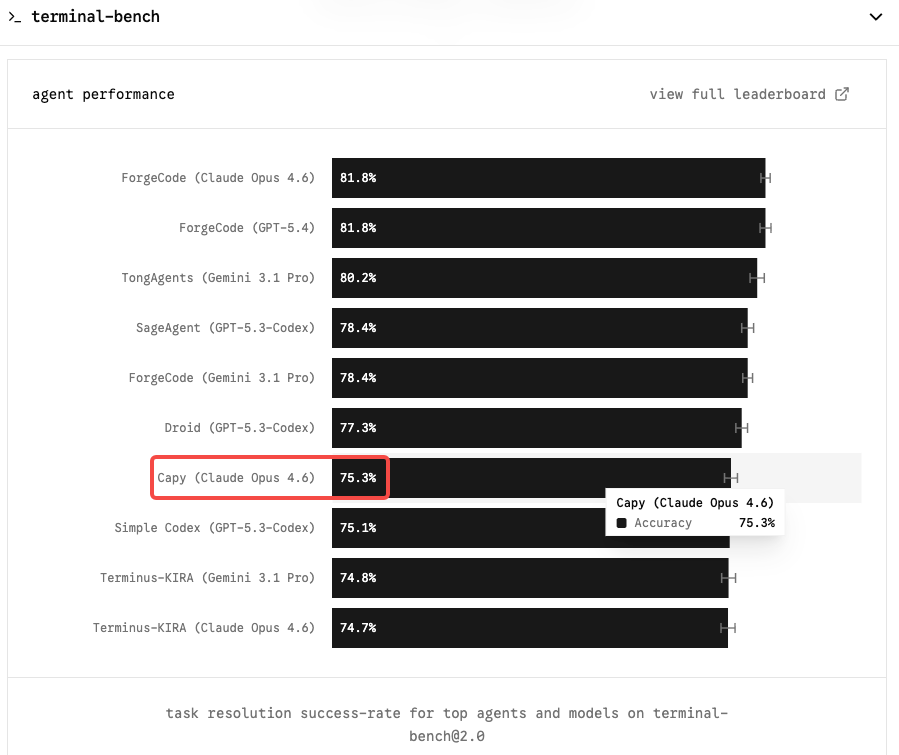
Terminal-Bench 2.0 是最重要的基準測試,對於代理式程式碼撰寫工作流程而言尤其如此。與測試獨立 GitHub issue 解決方案的 SWE-bench 不同,Terminal-Bench 在沙盒終端環境中評估真實任務——系統管理、DevOps、多步驟 CLI 工作流程。它難度更高、更能代表生產環境的使用情況,也較不容易受到架構驅動的分數膨脹影響。
Claude Opus 4.6 以 Terminal-Bench 2.0 65.4% 和 OSWorld 72.7% 排名第一。若 Capybara 等級的模型能將這個數字推進到 75–85% 的範圍,對任何運行自主程式碼撰寫代理的團隊而言,將是真正的質變。
在 SWE-bench Verified 上,情況更為集中:現在有六個模型的分數相差不到 0.8 個百分點。Opus 4.6 為 80.8%;Gemini 3.1 Pro 以每百萬 token $2/$12 的價格提供 80.6%。原始 SWE-bench 不再是有意義的差異化因素。Terminal-Bench 和長上下文一致性才是 Opus 4.6 值得溢價的地方——也是 Mythos 最有可能提出最清晰論據的地方。
「顯著更高」在結構上的實際含義
在草稿中,「顯著更高」與「質的變化」並列出現——這與 Anthropic 發言人公開使用的措辭相同。這兩個詞都不是隨意使用的。從 Opus 4.1 到 Opus 4.6 的跳躍是在同一等級內的代際改進。「質的變化」意味著某種不同性質的東西——更像 Sonnet 和 Opus 之間的差距,而不是兩個連續 Opus 版本之間的差距。
一個在程式碼撰寫方面明顯優於 Opus 4.6 的模型,將成為軟體開發、除錯和代理式工作流程的重要工具。懸而未決的問題是它何時可用以及費用如何。這是誠實的框架。鑑於 Anthropic 近期的記錄,效能聲明是可信的。驗證只是尚未到來。
對代理式程式碼撰寫工作流程的影響
長上下文程式碼任務
對程式碼撰寫團隊而言,Capybara 等級模型最直接的實際影響不是原始基準分數——而是更好的推理能力在規模上能做什麼。
Claude Code 的 100 萬 token 上下文窗口現在已在 Opus 4.6 上正式推出,在壓縮後提供約 83 萬個可用 token——足以容納整個 monorepo 和完整的文件集。一個在程式碼撰寫方面顯著優於 Opus 4.6 的模型,應用於同樣的窗口,意味著對大型程式碼庫有更好的架構理解,以及在多檔案重構時減少推理錯誤。上下文窗口不會改變。其中推理的質量將會改變。
對於今天進行大型程式碼庫分析的團隊——那種需要載入 5 萬行以上源代碼並要求模型理解全局的工作——這是最重要的實際升級路徑。
多步驟除錯代理
Anthropic 在 Opus 4.6 發布時將 Agent Teams 作為實驗性功能推出,標誌著代理式工作流程的重要一步。一個會話充當團隊負責人——它協調工作、分配任務並整合結果。隊員獨立工作,每個都在自己的上下文窗口中,並直接相互溝通。
多步驟除錯代理是更強大的基礎模型的複合價值最為清晰的地方。在多代理設置中,團隊負責人的規劃質量決定了整個操作的運行效果。更強大的模型能做出更好的任務分解決策、為子代理編寫更清晰的任務規範,並更早發現整合錯誤。
洩露的草稿特別指出軟體程式碼撰寫和網路安全是 Capybara「顯著」優於 Opus 4.6 的領域。如果這個差距在 Terminal-Bench 類型的任務上是真實且實質性的,它將直接轉化為更可靠的多步驟除錯代理,需要更少的人工干預來從錯誤假設中恢復。
自主驅動的程式碼庫探索
這是我在實踐中最好奇的使用案例。Claude Code 追蹤問題穿越你的程式碼庫,找出根本原因,並實施修復。這種追蹤的質量是推理深度的函數,而不僅僅是上下文窗口大小。
在典型的 2026 工作流程中,開發者可能提出一個高層次的需求,負責人代理將其分解為不同的任務,隊員利用 Model Context Protocol 同時訪問外部工具、運行測試並執行安全審計。作為協調者運行的 Capybara 等級模型將使整個工作流程更加自主——意味著更少的澄清請求、更好的初始任務分解,以及當子代理遇到意外狀態時更可靠的自我修正。
在 Mythos 尚未可用時,開發者現在應該做什麼
如何為你當前的使用案例對 Opus 4.6 進行基準測試
你現在能做的最有用的事情是對 Opus 4.6 進行自己的評估——不是對照基準測試,而是對照你的實際工作負載。SWE-bench 等通用基準測試使用標準化架構測試獨立的 issue 解決。你的生產程式碼撰寫代理有特定的程式碼庫結構、特定的任務集和特定的失敗模式。這些才是重要的。
程式碼撰寫代理的實用基線評估可能如下所示:
# Simple task success rate tracking
results = {
"task_id": [],
"model": [],
"success": [],
"turns_needed": [],
"context_used_tokens": [],
"cost_usd": []
}
# Run the same 20-30 representative tasks through Opus 4.6
# Track: did it succeed on first attempt? How many turns?
# What fraction of the 1M context window did it consume?
# Where did it fail — reasoning error, tool use, or context overflow?這很重要的原因是:當 Mythos 可用時,你將有一個真實的基線來評估能力提升是否能為你的特定工作流程帶來值得的成本溢價。Anthropic 內部測試套件上的「顯著更高」可能會或可能不會轉化為你特定程式碼庫結構和任務分佈上的有意義差異。
「最佳模型」是與你溝通方式相匹配的那個。在出色架構中的中等模型勝過在糟糕架構中的前沿模型。你的架構質量——提示工程、工具配置、CLAUDE.md 結構——是你現在可以改善的變數。Mythos 不會修復設計不良的代理架構。
能與更強大模型一起擴展的架構決策
好消息是,設計良好的代理式架構在路由層是與模型無關的。現在值得構建的模式:
將協調與執行分離。 一個分解任務、分配檔案並審查輸出的協調代理——由專門的子代理負責實施——可以通過單個參數更改來替換其基礎模型。現在建立這種分離,Mythos 升級就成為配置更新,而不是架構重構。
將 CLAUDE.md 用作運行時上下文,而非特定會話的提示。 CLAUDE.md 文件充當倉庫中 AI 代理的「憲法」——提供有關項目架構、程式碼標準和構建命令的必要上下文,使代理能夠在無需人工微觀管理的情況下運行。結構良好的 CLAUDE.md 今天可以降低 Opus 4.6 的每任務探索成本,明天也將放大更強大模型的收益。
為 100 萬 token 上下文窗口而設計,而非對抗它。 已經重構其文件載入策略、分塊邏輯和上下文管理以在 100 萬 token 窗口內工作的團隊,將能夠充分利用 Mythos 在同一窗口中的推理能力。不要為假設上限不會提高的上下文限制構建變通方案。
發布時,程式碼撰寫專注團隊應關注什麼
對開發者最重要的訊號與一般企業訊號不同。特別是對程式碼撰寫專注的團隊:
發布時的 SWE-bench 和 Terminal-Bench 分數。 Anthropic 歷來與模型發布同時公佈這些數據。如果 Mythos 兌現「顯著更高」的聲明,你預期 Terminal-Bench 2.0 分數將明顯高於 Opus 4.6 的 65.4%。跳升至 75% 以上將驗證代理式工作流程的聲明。
Claude Code 模型字串更新。 查看 Claude Code 文檔 和 API 模型概覽 以獲取新的模型別名。Claude Code 歷來在新旗艦發布後數天內更新其預設模型。如果 Mythos 向公開 API 發布,這是程式碼撰寫團隊將首先看到它的地方。
Agent Teams 相容性公告。 Agent Teams 在 Opus 4.6 時作為實驗性功能推出。Mythos 是否在發布時原生整合 Agent Teams——或是否需要單獨配置——將決定團隊能多快將其納入多代理工作流程。
Anthropic 更新日誌 和 定價文檔。這兩個頁面是任何新聞公告之前最早的可靠訊號。新的模型字串和新的定價行將首先出現在這裡。
常見問題
Claude Mythos 現在可用於程式碼撰寫任務嗎?
不。截至 2026 年 4 月初,沒有公開的 Claude Mythos 或 Capybara 等級的 API 端點。Claude Mythos / Capybara 僅對 Anthropic 選定的一小群早期存取客戶可用,沒有公開 API、沒有公佈的定價,也沒有確認的發布日期。Claude Opus 4.6——SWE-bench Verified 80.8%、Terminal-Bench 2.0 65.4%——仍然是最佳的公開可用選項。
Claude Mythos 能與 Claude Code 一起使用嗎?
幾乎可以肯定,最終會的。Claude Code 的架構與模型無關;切換到新旗艦只需更改單個參數。但這對 Mythos 在發布時並未確認。
我應該等待 Mythos 再構建我的 AI 程式碼撰寫工具嗎?
不。Anthropic 表示在「任何一般發布之前需要變得更加高效」。現在基於 Opus 4.6 構建意味著當 Mythos 到來時,你的架構已經過生產驗證。升級將是模型字串的替換。等待的團隊將處於追趕狀態。
Previous Posts:




