HappyHorse-1.0为何突然登顶视频排行榜?
HappyHorse-1.0在没有公开团队的情况下登顶Artificial Analysis排行榜。本文解析为何Elo评分体系更看重视频质量而非品牌——以及这对开发者意味着什么。

嘿,大家好,我是 Dora。我数了一下,这周我的信息流里有多少人问过类似”HappyHorse 到底是什么鬼?“这种问题——六次。六个独立的讨论串,每个都带着略有不同的传言——有人说它是 WAN 2.7,有人说是 ByteDance 的秘密发布,还有人说来自阿里巴巴。没人确切知道。但所有人都认同一件事:它大约在 2026 年 4 月 7 日至 8 日出现在 Artificial Analysis 视频排行榜上,并立刻拿下了文本生成视频和图像生成视频双榜的第一名。
这是事实。此后的一切——谁构建了它、权重何时发布、它能否守住第一——至今仍悬而未决。
这篇文章要讲的是:排行榜实际上在衡量什么,为什么一个无名模型能合理地登上榜首,以及作为开发者,你应该如何利用这些信息,又应该避免哪些误判。
Artificial Analysis 视频竞技场的运作机制
在你信任一个排名之前,你需要了解它在衡量什么。Artificial Analysis 视频竞技场不是模型开发者自行提交分数的基准测试——它是一个盲测用户投票系统。
用户看到的(和看不到的)
你进入竞技场,系统会展示两段由相同文本提示词或输入图像生成的视频,然后你选择更喜欢哪一个。你不知道哪个模型生成了哪段视频,没有标签,没有背景信息,只有两个视频片段。
Artificial Analysis 是这样直接描述的:“用户在不知道哪个模型生成了哪段视频的情况下,比较由相同文本提示词生成的两段视频。“这才是关键所在。没有自我报告,没有开发者提供的基准测试,没有营销页面影响结果。
Elo:信号可靠,但非万能
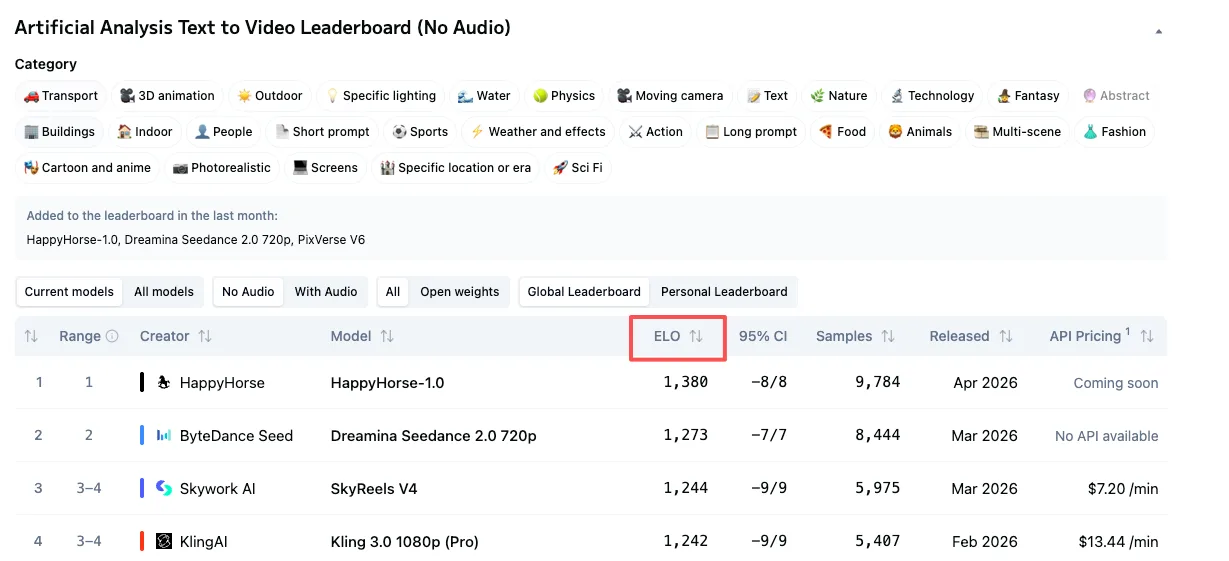
排名使用 Elo 系统——这套方法借鉴自竞技象棋。每当两个模型在投票中对决,胜者获得 Elo 分数,败者失去一些分数。Elo 分数高的模型意味着它在与其他模型的对决中赢多输少。
更高的 Elo 分数表明一个模型更频繁地被用户偏好。这是真实的信号,基于成千上万次真实的人类选择,而非合成测试、精心挑选的样本或模型简介页。
投票数量与样本规模:被人们忽视的部分
关于 Elo 与新入场模型,有一点值得注意。像 Seedance 2.0 这样的成熟模型背后有数千次投票支撑其分数——Seedance 2.0 在文本生成视频类别中拥有超过 7500 个投票样本。HappyHorse 的样本数量目前尚未公开拆分披露。投票越多 = 分数越稳定。新入场模型参与对决次数较少,每一次新投票的影响都会更大。

随着更多投票涌入,这些数字会发生变化。变化的方向未知。在把流水线决策押注在一个只有两天历史的数字上之前,请务必牢记这一点。
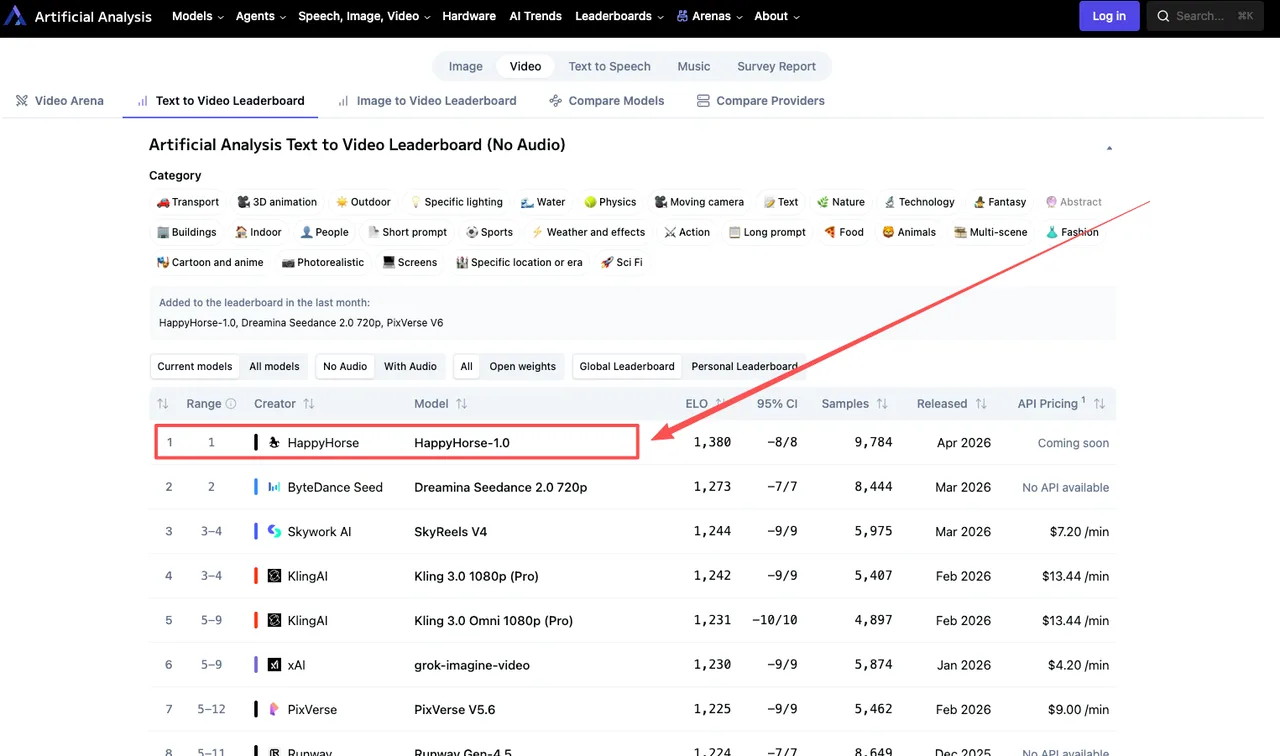
HappyHorse-1.0 的实际得分情况
以下数据摘自 2026 年 4 月初的实时排行榜:
文本生成视频(无音频): HappyHorse-1.0 以 1357 的 Elo 分数领先,其后是 Dreamina Seedance 2.0(1273)、SkyReels V4(1244)和 Kling 3.0 Pro(1243)。
图像生成视频(无音频): HappyHorse-1.0 以 1402 的 Elo 领跑,Seedance 2.0 为 1355,Grok Imagine Video 为 1331。
图像生成视频(无音频)类别中 84 分的差距并不小。60 分的 Elo 差距意味着一个模型在盲测对决中赢得约 58–59% 的胜率——这已经很有意义了。超过 80 分的差距则更为显著。
音频版本的排名反转
对于带音频的图像生成视频,HappyHorse-1.0 目前以 1160 的 Elo 领先,而 Dreamina Seedance 2.0 为 1158。2 分的差距属于统计误差。在带音频的文本生成视频类别中,Seedance 2.0 以 1220 领先,HappyHorse 为 1215。
因此,实际情况比”HappyHorse 全面称霸”更为微妙。当音频排除在外时,它以显著优势领先;一旦音频质量进入考量范围,它与 Seedance 2.0 基本持平。
架构声称说明了什么(又无法证明什么)
多家描述 HappyHorse 的网站表示,它运行于单流 Transformer 架构,参数量约 150 亿,在单张 H100 上生成一段 1080p 视频的速度约为 38 秒。截至 2026 年 4 月 8 日,这些 HappyHorse 网站上的 GitHub 和 Hugging Face 链接指向”即将上线”页面或返回 404 错误。权重尚未公开可下载。
这些架构声称是合理的——但尚未经过核实。没有任何独立技术审计确认参数数量、架构类型或推理速度。请将其视为声称,而非确认。
为什么无名模型能在 Elo 上获胜
这正是让那些认为排行榜奖励品牌认知度的人感到困惑的地方。
Elo 不关心谁构建了模型。 它不知道你是谷歌还是一个三人实验室。Artificial Analysis 的视频竞技场使用 Elo 评级系统,完全依赖真实用户的盲测投票。它忽略参数、论文或炒作——只关心一个问题:“在看完两段视频后,你更喜欢哪一段?”
这实际上是一个优点。这是为数不多的评估系统之一,资金雄厚的品牌无法通过发布有利论文来买到更好的结果。
这种模式之前出现过
匿名预发布投放已经成为中国 AI 生态中的一种规律。2026 年 2 月的 Pony Alpha 事件是最清晰的先例——一个神秘模型出现在 OpenRouter 上,引发了一场猜谜游戏,结果证明是 Z.ai 的 GLM-5 在进行秘密压力测试。HappyHorse 符合这一模板:无名名称、发布时无团队署名、登陆页面上的 GitHub 链接写着”即将上线”、输出效果优秀。
无论它是大型实验室在悄悄做能力测试,还是真正的新团队——目前仍未有定论。但不管怎样,Elo 分数本身是真实的。
Elo 无法掩盖的局限性
Elo 衡量一件事:哪段视频在盲测比较中更受真实用户偏好。它不衡量模型在批量运行中的表现,不衡量 API 正常运行时间、负载下的延迟,也不衡量当你大规模生成而非精心挑选竞技场示例时,输出质量是否能保持稳定。
一个模型可以有出色的盲测结果,却在生产中完全无法使用。这是两个独立的问题。
“排行榜第一”对开发者意味着什么(和不意味着什么)
如果你正准备根据 HappyHorse 当前的排名做工具选型决策,我建议你先放慢脚步。
没有 API,没有生产访问权限
有三件事能让 HappyHorse 从”排行榜条目”变成”真实可用的选项”:一个包含实际权重和推理代码的 GitHub 仓库、一个带有可核实细节和许可证的 HuggingFace 模型页,或者一个有文档化定价的 API 端点。截至本文撰写时,以上三者均不存在。
如果你无法调用它,你就无法使用它。排行榜位置是关于输出质量的信息,而非可用性的证明。
音频表现改变了计算逻辑
如果你的工作流需要音频——配音、环境音、口型同步——那么 HappyHorse 的领先优势基本消失。在带音频类别中,它与 Seedance 2.0 的差距在文本生成视频中为 5 分,在图像生成视频中为 2 分。这些都在正常 Elo 方差范围内,相当于打平。
对于需要音频的使用场景,目前实际格局看起来是 Seedance 与 HappyHorse 在顶部并列,SkyReels V4 明显落后一个身位。
团队责任归属:未知
Artificial Analysis 在将 HappyHorse 添加到竞技场时将其描述为”匿名”模型。与该模型相关的一组网站声称它由淘天集团(阿里巴巴)未来生活实验室团队构建,由前 Kling AI 负责人张笛领导。另一项分析将其与 Sand.ai 的一个名为 daVinci-MagiHuman 的开源项目联系起来,两者规格几乎相同。两者均未得到官方确认。
对于一个生产工具来说,团队责任归属在错误修复、模型更新和长期支持方面至关重要。对于匿名模型,你无法获得这种清晰度。
作为开发者如何解读视频排行榜
具体框架,不谈抽象原则。
将 Elo 视为质量信号,而非采购决策。 如果一个模型在与资金雄厚的竞争对手的盲测比较中持续获胜,那确实说明了一些关于它所产出内容的实质性东西。这值得关注。但它无法告诉你任何关于 API 条款、定价、延迟,或团队是否响应 bug 报告的信息。
实际可用的排行榜从第三名开始。 Elo 最高的两个模型——HappyHorse 和 Seedance 2.0——目前都无法通过公开 API 访问。下一梯队——SkyReels V4、Kling 3.0、PixVerse V6——才是当前实际集成决策的发生地。
何时对新入榜模型采取行动。 如果一个模型以有意义的 Elo 差距位居榜首,拥有经过验证的 GitHub 发布,且文档齐全——值得立即测试。如果它位居榜首但 GitHub 显示”即将上线”——设一个两周后的提醒再去检查。不要围绕虚无缥缈的东西重构流水线。
直接查看实时排行榜,而非依赖文章。 包括本文在内。Elo 分数每天都在变动。我在此引用的数据反映的是 2026 年 4 月初的情况,当你读到这篇文章时,数字已经发生了变化。
常见问题
HappyHorse-1.0 在 Artificial Analysis 排行榜上出现多久了?
Artificial Analysis 于 2026 年 4 月 7 日宣布了它,将其描述为新添加的匿名模型。截至本文撰写时,它上线约 48 小时,投票数仍在持续累积。
一个模型能无限期保持 Elo 第一吗?
通常不会。随着更新的模型进入竞技场并积累更多投票,排名会发生变化。一个在第二天以小样本量称霸的模型,随着投票池加深可能会稳定在更低的位置。分数始终是实时的——它反映当前数据,而非永久性判断。
Artificial Analysis 会核实谁向竞技场提交模型吗?
Artificial Analysis 尚未发布关于模型提交的正式核实政策。他们在宣布 HappyHorse-1.0 时将其描述为”匿名”,这表明团队身份对他们是已知的,但未公开披露。他们是否对提交的模型进行任何技术审计,目前没有文档记载。
我应该仅凭 Elo 分数选择模型吗?
不应该。Elo 告诉你的是盲测比较中的视觉偏好。它对 API 可用性、每次生成的费用、延迟、正常运行时间、内容政策,或者该模型三个月后是否还存在,一概不置可否。它只是众多信号之一。
除了排行榜排名,还有哪些指标值得关注?
API 访问权限和文档;每次生成或每分钟的定价;在你的使用频率下的延迟和冷启动行为;Elo 分数背后的样本数量(投票越多 = 越稳定);以及团队是否有维护和更新模型的历史记录。如果你需要一个起点,WaveSpeed 模型对比页面跨可访问模型追踪了其中几个维度。
目前情况就是这样。一个团队未知、没有公开权重的模型,刚刚以难以忽视的优势登上了我们所拥有的最具公信力的视频基准榜首。它能否成为真正的生产选项,完全取决于接下来几周内会发布什么。
值得关注。但还不值得付诸行动。
更多内容即将到来。
在 WaveSpeedAI 上试用 HappyHorse-1.0
HappyHorse-1.0 现已在 WaveSpeedAI 上线:
往期文章:
