OmniHuman-1.5:Toward Virtual Humans with “Soul”
Have you ever watched videos featuring smoothly animated digital humans, but felt they lacked genuine emotion? To overcome this limitation, we introduce OmniHuman-1.5, developed by ByteDance—a groundbreaking framework designed to generate character animations that transcend superficial mimicry. It not only brings virtual avatars to life but also endows them with the ability to express emotions.
你曾看过具有流畅动画的数字人类视频,但是否觉得他们缺乏真实的情感?为了克服这一限制,我们推出了由字节跳动开发的 OmniHuman-1.5——一个突破性框架,旨在生成超越表面模仿的角色动画。它不仅使虚拟化身栩栩如生,还赋予它们表达情感的能力。
从模仿到表达:技术突破
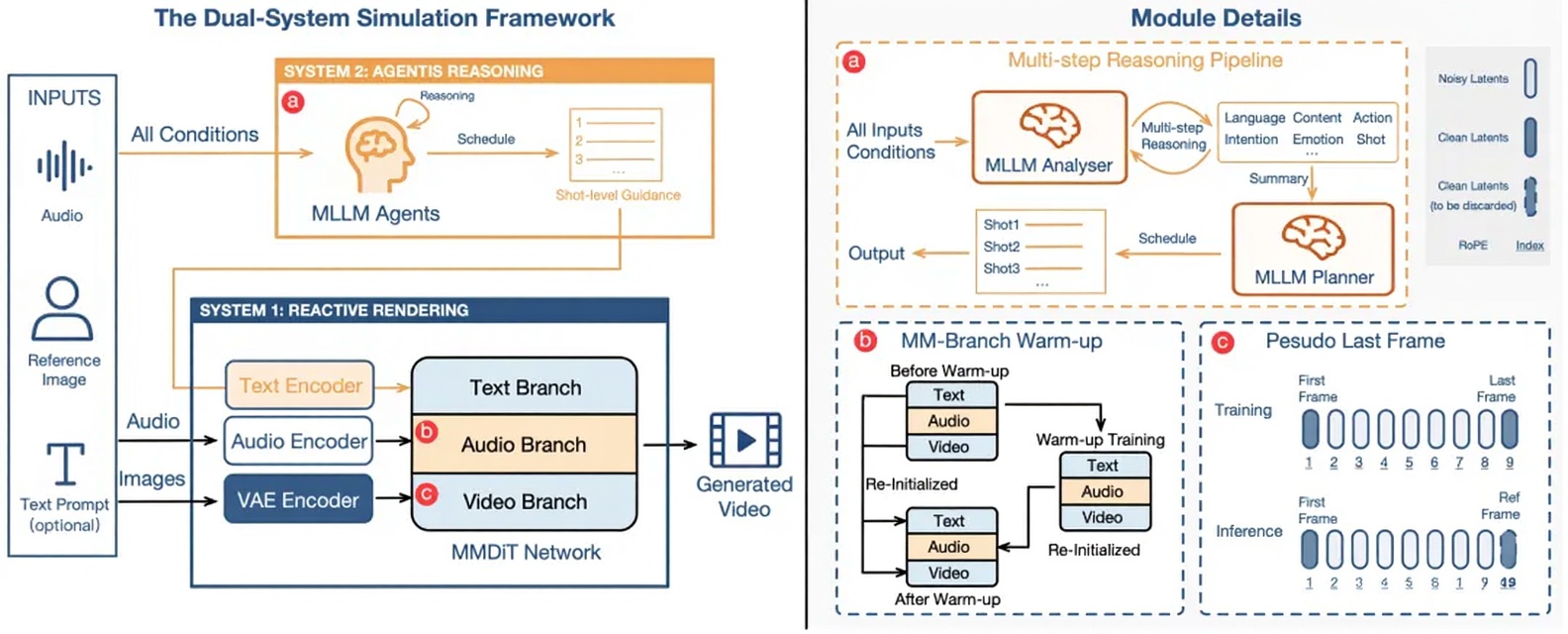
OmniHuman-1.5 采用双系统模拟框架。
首先,该方法利用多模态大型模型生成结构化的语义表示,提供先进的语义指导,使动作生成超越单纯的节奏同步,更好地与上下文和情感对齐。
其次,通过专门设计的多模态 DiT 架构和伪末帧机制,它可以高效融合多模态信息,同时减轻冲突,从而生成与角色、场景和语言深度一致的动作。
OmniHuman-1.5 能做什么?
🎶音乐表演
只需一张照片和一首歌曲,OmniHuman-1.5 就能创建一个”数字歌手”,精确模仿艺术家的停顿、呼吸和节奏。
🎭情感表演
OmniHuman-1.5 不仅可以创建数字歌手,还可以制作富有情感的数字演员。
🗣️上下文感知手势
动画不再重复,而是与意义对齐。例如,当音频提到”心脏”时,角色自然地把手放在胸口。
✍️文本引导动画
OmniHuman-1.5 支持提示控制。示例包括:
- 摄像机运动:“摄像机缓慢环绕角色,营造艺术电影的氛围。”
- 物体生成:“化身向镜头伸出手,然后开始说话。”
- 特定动作:“一只企鹅跳舞、戴上太阳镜并在舞台上表演。“
👥多角色和风格化场景
与以往的数字人类不同,OmniHuman-1.5 可以进行群体对话和集体表演。
它也适用于人类、动物、拟人化人物和风格化卡通形象,展现出非凡的多功能性。
结论:走向具有”灵魂”的虚拟人类
虚拟人类技术取得了新的突破。OmniHuman-1.5 的出现标志着一个新时代的到来,虚拟人类已从表面模仿演进到深层表达。它能理解你说的话,并与你进行真诚、深情的交流。让我们期待 OmniHuman-1.5 模型的推出!
现在在 WaveSpeedAI 上注册。此外,你可以在下方社交媒体上与我们联系。
Discord: Discord





