HappyHorse-1.0 与 Seedance 2.0 对比:谁更胜一筹?
HappyHorse-1.0 在无音频的文生视频和图生视频任务上领先 Seedance 2.0,但在音频处理上表现较弱,且尚无稳定 API。以下是对开发者的实际影响分析。

我花了不少时间刷新 Artificial Analysis 视频竞技场排行榜。嗨,我是 Dora!上周末,一个我从未听说过的模型——HappyHorse-1.0——悄然出现,并在四个主要排名中的两个将 Seedance 2.0 从榜首挤了下来。没有人知道是谁开发了它。Artificial Analysis 本身将其称为一个”匿名”参赛者。我的时间线上一半是兴奋,一半是困惑。
于是我整理了数据,追踪了访问路径,试图弄清楚一个对所有正在使用这些模型的人来说真正重要的问题:哪一个是你今天就能投入使用的?
答案并不像排行榜看起来那么简单。
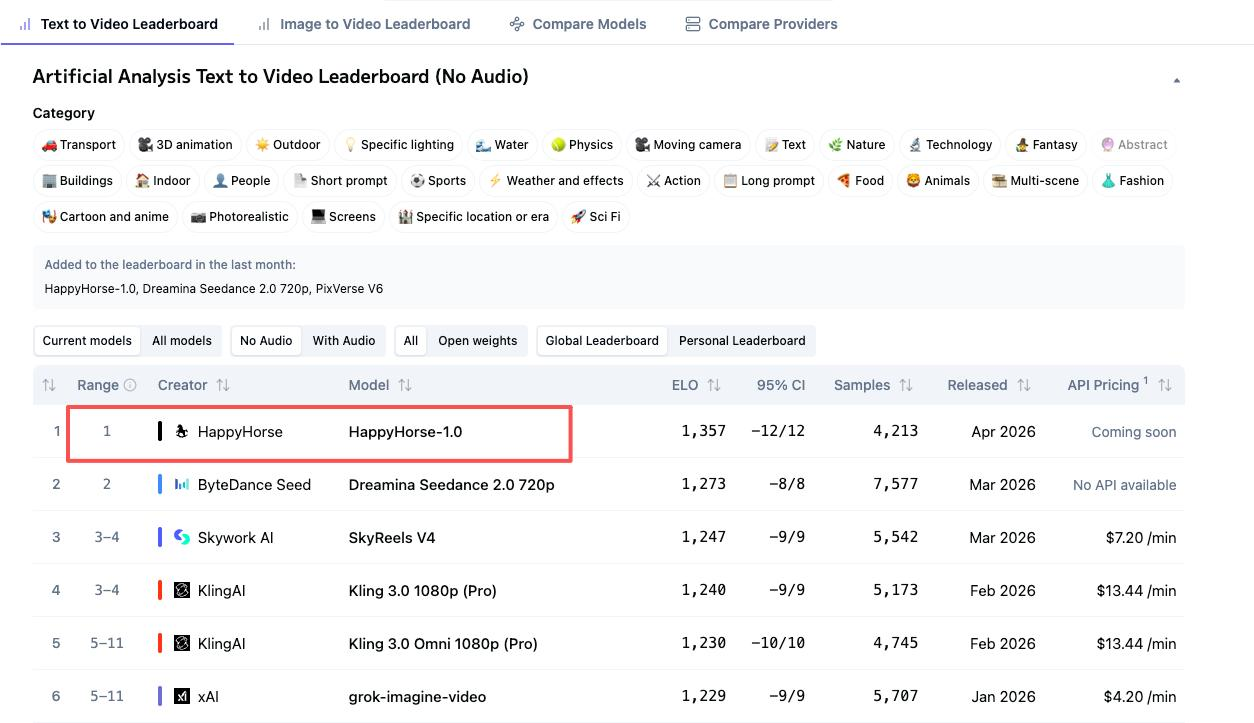
排行榜上真正重要的四个数字
HappyHorse 和 Seedance 2.0 占据了 Artificial Analysis 四个独立排名的榜首。但它们的位置会根据评测是否包含音频而互换。这一区别比大多数比较所承认的更为重要。
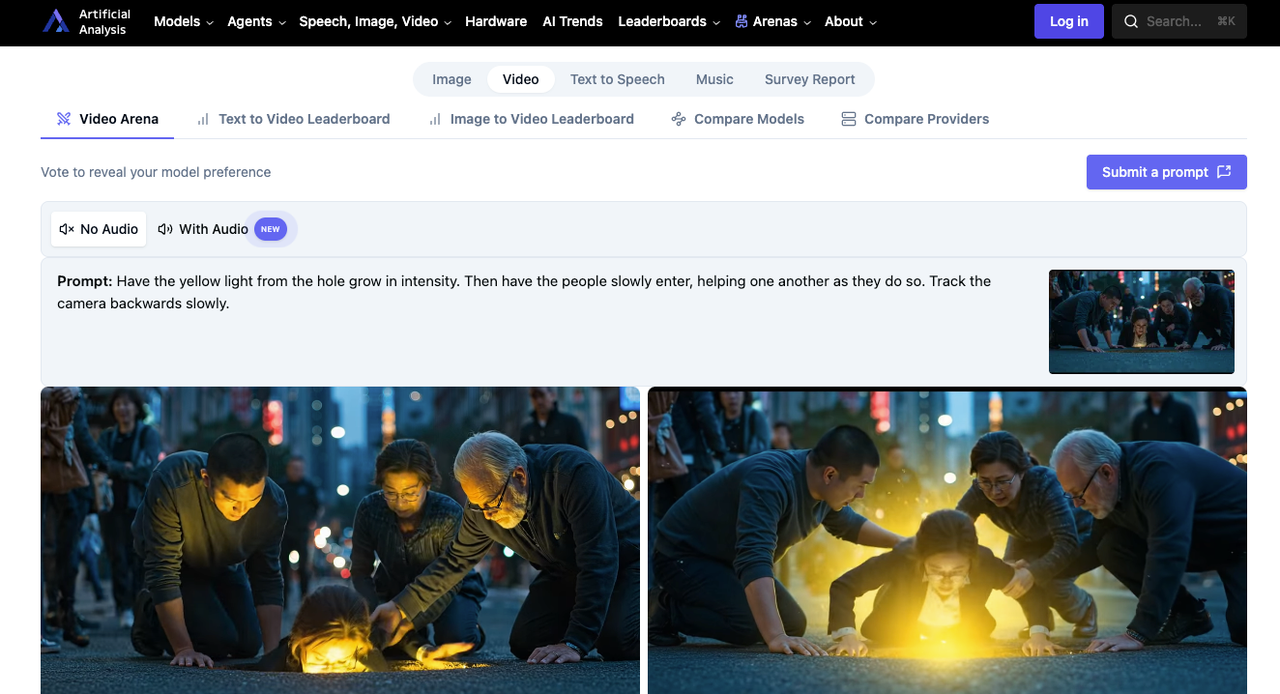
无音频文生视频:HappyHorse 第1名(Elo 1333)vs Seedance 2.0 第2名(Elo 1273)
这是 HappyHorse 表现最强劲的项目。在盲测投票竞技场中 60 分的 Elo 差距是有意义的——这大致意味着在一对一对比中,用户约 59% 的时间会选择 HappyHorse 的输出。这里的投票捕捉的是视觉运动质量、提示词遵循度和场景连贯性,不受任何音频的影响。
有音频文生视频:Seedance 2.0 第1名(Elo 1219)vs HappyHorse 第2名(Elo 1205)
一旦加入音频,Seedance 以 14 分的优势领先。字节跳动的双分支扩散 Transformer 在单次推理中同时生成视频和音频——一个分支负责视频帧,另一个负责音频波形,通过交叉注意力机制连接。当同步的音效和对话成为评判标准时,这一架构选择的价值就体现出来了。
无音频图生视频:HappyHorse 第1名(Elo 1392)vs Seedance 2.0 第2名(Elo 1355)
这是 HappyHorse 在所有四个类别中最高的 Elo 值。在无音频图生视频上领先 37 分,表明该模型在遵循参考图像构图方面尤为出色——在生成运动时保持主体身份、取景和视觉风格的一致性。对于做产品动画或概念转动态工作的团队来说,这个数字最为重要。
有音频图生视频:Seedance 2.0 第1名(Elo 1162)vs HappyHorse 第2名(Elo 1161)——几乎持平
仅差一分。 这在任何合理的误差范围内。两个模型在这里都没有实质性优势。在积累更多投票之前,将这个类别视为平局。
Elo 实际衡量的是什么——及其对生产决策的局限性
这些 Elo 分数来自盲测用户在并排比较中的投票,使用从国际象棋排名改编的 Bradley-Terry 模型。用户看到同一提示词下匿名生成的两个视频,选择他们更喜欢的那个。这是我们目前最接近大规模”感觉测试”的方式。
但 Elo 不衡量 API 可靠性、生成速度、每个片段的成本、访问稳定性,或者你是否能以编程方式调用该模型。排行榜排名是质量信号,而非上线决策。
核心对比表
| 维度 | HappyHorse-1.0 | Seedance 2.0 |
|---|---|---|
| 无音频文生视频 Elo | 1333(第1名) | 1273(第2名) |
| 有音频文生视频 Elo | 1205(第2名) | 1219(第1名) |
| 无音频图生视频 Elo | 1392(第1名) | 1355(第2名) |
| 有音频图生视频 Elo | 1161(第2名) | 1162(第1名) |
| 音频生成 | 有,但落后于 Seedance | 更强——原生双分支同步 |
| 已知提供商 | 否——匿名 | 是——字节跳动 |
| 架构(声称) | 单流 40 层 Transformer | 双分支扩散 Transformer |
| 开放权重 | 声称”即将推出” | 否 |
| 稳定 API | 无公开 API | 消费者通过 Dreamina 访问;官方 API 暂停 |
| 今日访问方式 | 仅限演示网站 | Dreamina、CapCut Pro、国内应用 |
HappyHorse 的领先之处
无音频场景的视觉运动质量:盲测投票捕捉到了什么
无音频排名上的 Elo 差距——文生视频 60 分,图生视频 37 分——并非微不足道。在盲测比较中,用户持续选择 HappyHorse,原因被描述为更自然的镜头漂移、更流畅的肢体运动和更强烈的场景氛围。如果你的用例是静音产品循环、配独立音乐的社交短片,或在后期配乐的 B-roll,这个数字就很重要。
单流 Transformer 架构(声称)vs 多流流水线
HappyHorse 的宣传材料描述了一个统一的 40 层自注意力 Transformer,在单一序列中处理文本、视频和音频 token——各独立分支之间没有交叉注意力。如果属实,这在架构上与 Seedance 的双分支方法截然不同。据称前后各 4 层使用模态专用投影,中间 32 层跨所有模态共享参数。我目前还无法独立验证这些说法。GitHub 和模型中心均标注为”即将推出”。
多语言音频支持声明
HappyHorse 声称原生支持七种语言——英语、普通话、粤语、日语、韩语、德语和法语——并具有低词错率的唇形同步。Seedance 2.0 支持 8 种以上语言的音素级唇形同步。从纸面上看,两者旗鼓相当。但实际上,我还没能对 HappyHorse 的多语言输出进行足够的压力测试来确认其与 Seedance 的对等性。
Seedance 2.0 保持优势的地方
音频生成:在两个有音频排行榜上仍然领先
Seedance 在有音频的文生视频和图生视频上均位居第1。其双分支架构——一个分支生成视频帧,另一个生成音频波形,通过交叉注意力实现毫秒级同步——正是为此目的而设计的。当你的输出需要对话、环境音或逐帧精准的音效时,Seedance 将音频作为生成过程中的一等公民(而非后处理步骤)的架构决策赋予了它结构性优势。
已知提供商:字节跳动,身份稳定,生态完善
你知道 Seedance 2.0 是谁开发的。字节跳动的 Seed 研究团队,由吴永晖(前谷歌 Fellow,在谷歌包括 Google Brain 工作了 17 年)领导,有从 Pixeldance 到 Seedance 1.0、1.5 Pro,再到 2.0 的有据可查的传承。而 HappyHorse?截至本文发布时,没有人公开确认是谁开发了它。Artificial Analysis 将其作为匿名参赛者添加。多个第三方封装网站在其竞技场首秀后数小时内出现,但没有一个声称是原始开发者。
对于生产决策来说,来源至关重要。你需要知道在模型更新、合规性和连续性方面你依赖的是谁。
访问路径:Dreamina 有公开入口
Seedance 2.0 今天就可以通过字节跳动的 Dreamina 平台国际访问,付费计划起价约 18 美元/月。CapCut Pro 集成于 2026 年 3 月底在部分市场推出。中国用户可以通过即梦访问,计划起价约 69 元/月(约 9.60 美元)。
话虽如此——官方 Seedance 2.0 API 自 2026 年 3 月中旬起因报道的版权纠纷而暂停。消费者访问正常运作。在你将流水线构建在其上之前,需要先验证生产规模的程序化 API 访问情况。第三方提供商通过 API 提供 Seedance v1.5;官方渠道的 Seedance 2.0 API 可用性需要在正式投产前确认。
访问差距才是真正的决策因素
HappyHorse:截至发布时无稳定 API、无公开权重、仅限演示
尽管声称要开源发布,HappyHorse 的 GitHub 和模型中心均标注为”即将推出”。存在多个演示和封装网站,但没有一个提供带有 SLA、速率限制或定价的文档化 API 端点,让你可以围绕其构建产品。我找不到任何一家第三方 API 提供商目前通过稳定的、有文档记录的端点提供 HappyHorse-1.0 服务。
如果你在评估生产可用性,这是最重要的单一因素。一个你无法可靠调用的模型,就不是一个你能交付的模型。
Seedance 2.0:可通过 Dreamina 访问——细节需要验证
通过 Dreamina 的消费者访问是可用的。该平台支持完整功能集,包括 @ 参考系统、多镜头编辑和音视频生成。但如果你的工作流程需要 API 级别的集成,情况就不那么明朗了。Seedance 2.0 的官方 BytePlus API 自 3 月起已暂停。fal.ai 和 PiAPI 等第三方提供商提供了 Seedance 1.5;Seedance 2.0 的程序化访问及其相关定价结构应在构建生产依赖之前直接确认。
为什么”排行榜第1”和”生产就绪”是不同的问题
我不断回想到这一点。Elo 告诉你在受控比较中用户更喜欢哪个模型。它不告诉你下周二能否稳定跑完 10,000 次生成而不出现 503 错误。HappyHorse 可能确实能生成更好的静音视频。但如果你无法可靠地调用它,那个质量优势只存在于竞技场中,而不在你的流水线里。
决策框架
音频质量不可妥协 → Seedance 2.0。 它在两个有音频排行榜上均领先,其双分支架构原生生成同步音效。如果你的片段需要对话、环境音频或逐帧精准的音效,Seedance 是今天更强的选择。
视觉运动保真度是你的优先级,且你愿意等待 → 持续关注 HappyHorse。 无音频 Elo 领先是真实存在的。如果开放权重和 API 访问如承诺般实现,HappyHorse 对于静音优先的工作流程可能会很有吸引力。但”即将推出”不是 SLA。
你今天就需要生产 API → Seedance 2.0 是更安全的选择。 不是因为它完美——官方 API 暂停是一个真实的限制——而是因为 Dreamina 提供了带有文档化定价的可用访问路径,且第三方提供商正在积极准备 Seedance 2.0 端点。HappyHorse 目前还没有同等的基础设施。
常见问题
HappyHorse-1.0 真的比 Seedance 2.0 更好吗?
取决于你衡量的标准。HappyHorse 在无音频比较中的视觉质量上领先(文生视频 Elo 1333 vs 1273,图生视频 1392 vs 1355)。当音频作为评测一部分时,Seedance 领先。两个模型都没有在所有四个类别中占据主导。“更好”只有相对于你的具体用例以及音频是否重要时才有意义。
为什么 HappyHorse 在无音频时领先,但在有音频时落后?
可能与架构有关。HappyHorse 声称采用单一统一的 Transformer 在一个序列中处理所有模态。Seedance 2.0 使用专门设计的双分支结构,独立的视频和音频分支通过交叉注意力连接。当声音质量和同步与视觉一起被评判时,这个专门的音频分支似乎给了 Seedance 优势。
我今天可以通过 API 访问 HappyHorse-1.0 吗?
截至 2026 年 4 月 8 日,我无法验证任何稳定的、有文档记录的端点。多个封装网站提供基于浏览器的演示访问,但没有一个发布 API 文档、速率限制或生产级 SLA。官方 GitHub 和模型中心均标注为”即将推出”。
Artificial Analysis 排行榜对生产决策有多可靠?
它是感知视频质量最可信的众包信号——盲测投票,基于 Elo 的排名,真实的人类偏好。但它只衡量一件事:用户在并排比较中更喜欢哪个输出。它不考虑生成速度、成本、可靠性、API 正常运行时间或访问稳定性。将其作为质量输入,而非完整的采购决策。
HappyHorse-1.0 会在未来版本中改进音频吗?
没有公开的路线图。该模型在不到一周前以匿名身份出现在竞技场上。如果”即将推出”的开源发布成真,社区贡献可能会提高音频质量。但目前没有时间表、没有确认的开发团队、也没有宣布的 v2 计划。任何超出当前排行榜所显示的内容都是猜测。
排行榜所说的与开发者实际能使用的之间,正在发生一些有趣的事情。HappyHorse 的数据确实令人印象深刻——但没有访问途径的数字只是数字。我会继续关注那个 GitHub 仓库何时上线。在那之前,这个比较其实不是关于哪个模型更好的问题。而是关于哪个模型现在可以用。
在 WaveSpeedAI 上试用 HappyHorse-1.0
HappyHorse-1.0 现已在 WaveSpeedAI 上线:
往期文章:




