Claude Mythos 编码性能:对 AI 开发工作流意味着什么
据报道,Claude Mythos 在编码方面的得分远高于 Opus 4.6。以下是这对 2026 年构建 AI 编码智能体的开发者意味着什么。

当《财富》杂志发布了一篇措辞强硬的独家报道称:Anthropic 意外泄露了近 3,000 个内部文件,其中包括一篇宣传其未发布模型的博客草稿,所有人的目光都聚焦在了这场网络安全事件上。但作为一个每天都在使用 Claude 进行开发的人,吸引我注意力的并非泄露事件本身——而是那篇草稿中悄然藏着的关于编程性能的爆炸性声明。
在 WaveSpeedAI 上即刻可用 — 按 token 透明计费,OpenAI 兼容端点。 Claude Opus 4.7 API → · Claude Sonnet 4.6 API → · 打开 Playground →
在这篇文章中,我和大家——我是 Dora——不打算追逐炒作或安全恐慌,而是直奔要害,梳理我们目前已知(以及尚不清楚)的关于 Claude Mythos / Capybara 编程能力的一切。
泄露草稿对 Claude Mythos 编程性能的描述
草稿中的原文如下:“与我们此前最优秀的模型 Claude Opus 4.6 相比,Capybara 在软件编程、学术推理和网络安全等测试中取得了大幅更高的分数。”
这就是 Anthropic 在文字层面对编程性能的全部描述。没有 SWE-bench 百分比,没有 Terminal-Bench 分数,也没有对比表格。“大幅更高”这个措辞才是真正的信号——虽然模糊,但并非毫无意义。

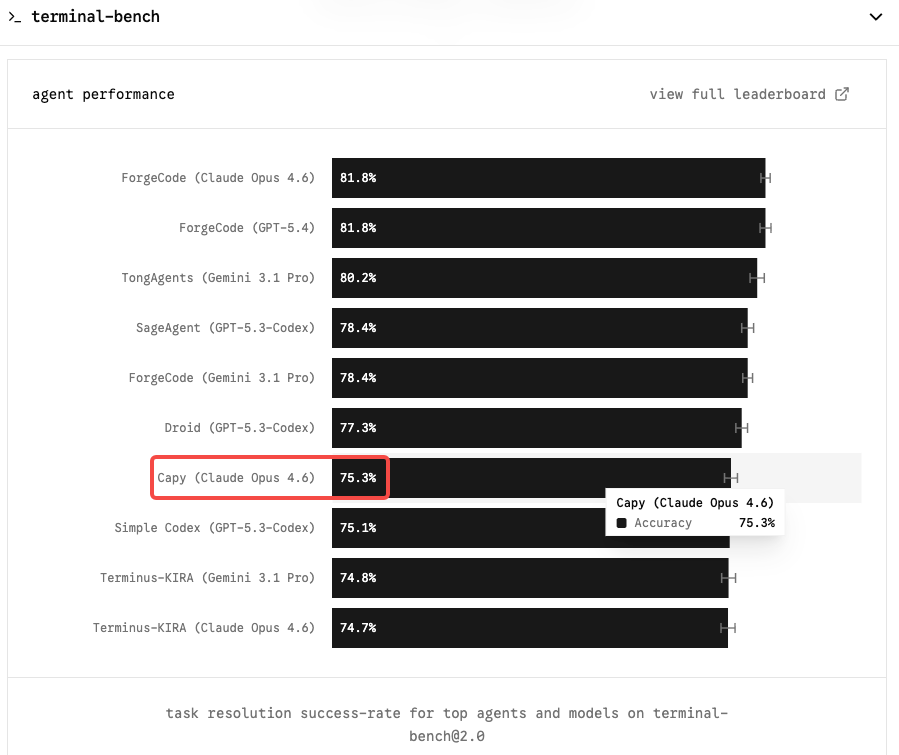
就背景而言,Opus 4.6 目前在公开可用模型中领跑 SWE-bench Verified(约 80.8%)、Terminal-Bench 2.0 和 Humanity’s Last Exam。Anthropic 官方发言人确认,该模型在推理、编程和网络安全方面代表着”有实质意义的进步”。训练已完成,早期访问测试正在进行,编程明确是三大核心能力维度之一。其余均为推断。
为何编程是这一模型层级最重要的能力
Terminal-Bench 2.0 背景与当前 Opus 4.6 分数
Terminal-Bench 2.0 是最关键的基准测试,专为智能体编程工作流而设计。与测试孤立 GitHub 问题解决的 SWE-bench 不同,Terminal-Bench 在沙盒终端环境中评估真实任务——系统管理、DevOps、多步骤 CLI 工作流。它更难、更贴近生产实际,也更不容易被脚手架技巧所刷高。
Claude Opus 4.6 以 Terminal-Bench 2.0 65.4% 的成绩位居榜首,OSWorld 达到 72.7%。若 Capybara 层级的模型能将这一数字推进至 75–85% 区间,对于任何运行自主编程智能体的团队而言,将是真正意义上的跨越式进步。
在 SWE-bench Verified 上,竞争格局更为拥挤:六个模型的分数相差不足 0.8 个百分点。Opus 4.6 为 80.8%;Gemini 3.1 Pro 以每百万 token $2/$12 的价格达到 80.6%。原始 SWE-bench 已不再是有意义的差异化因素。Terminal-Bench 和长上下文连贯性才是 Opus 4.6 值得溢价的地方——也正是 Mythos 最可能展示竞争力的领域。
“大幅更高”在结构层面的实际含义
在草稿中,“大幅更高”与”跨越式进步”并列出现——Anthropic 官方发言人公开发言中也使用了同样的措辞。这两个词都不是随口说说。从 Opus 4.1 到 Opus 4.6 的飞跃是同一层级内的代际提升。“跨越式进步”暗示着一种本质上的不同——更像 Sonnet 与 Opus 之间的差距,而非两个相邻 Opus 版本之间的差距。
一个在编程上显著超越 Opus 4.6 的模型,将成为软件开发、调试和智能体工作流的重要工具。悬而未决的问题是:何时可用,以及定价几何。这才是诚实的框架。鉴于 Anthropic 近期的发展轨迹,性能声明是可信的。只是验证尚未到来。
对智能体编程工作流的影响
长上下文代码任务
Capybara 层级模型对编程团队最直接的实际影响,并非原始基准分数——而是更强的推理能力在规模化应用时能带来什么。
Claude Code 的 100 万上下文窗口现已对 Opus 4.6 正式开放,压缩后可提供约 83 万可用 token——足以容纳整个 monorepo 和完整文档集。将一个在编程上大幅超越 Opus 4.6 的模型应用于同等窗口,意味着对大型代码库的架构理解更深入,多文件重构中的推理错误更少。上下文窗口本身不会改变,但其中推理质量会提升。
对于今天从事大型代码库分析的团队——那种需要加载 5 万行以上源码并要求模型理解全貌的工作——这是最关键的实际升级路径。
多步骤调试智能体
Anthropic 随 Opus 4.6 发布同时推出了智能体团队(Agent Teams)作为实验性功能,标志着智能体工作流迈出了重要一步。一个会话充当团队负责人——协调工作、分配任务、综合结果。团队成员独立工作,各自拥有独立的上下文窗口,并可相互直接通信。
多步骤调试智能体正是更强基础模型的复合价值体现得最清晰的地方。在多智能体架构中,团队负责人的规划质量决定了整体运作效率。更强的模型能做出更好的任务分解决策,为子智能体编写更清晰的任务规格,并更早发现集成错误。
泄露草稿专门点名软件编程与网络安全并列,称其为 Capybara “大幅”超越 Opus 4.6 的领域。如果这一差距在 Terminal-Bench 类任务上确实存在且显著,将直接转化为更可靠的多步骤调试智能体,需要更少的人工干预来从错误假设中恢复。
自主代码库探索
这是我在实践中最感兴趣的用例。Claude Code 追踪代码库中的问题路径,识别根本原因,并实现修复。这种追踪的质量是推理深度的函数,而不仅仅是上下文窗口大小。
在典型的 2026 工作流中,开发者可能提出一个高层级需求,负责人智能体将其分解为不同任务,团队成员利用模型上下文协议(Model Context Protocol)同时访问外部工具、运行测试并执行安全审计。以 Capybara 层级模型作为这类架构中的编排者,将使整个工作流更加自主——意味着更少的澄清请求、更好的初始任务分解,以及当子智能体遭遇意外状态时更可靠的自我纠正。
Mythos 尚未开放时,开发者现在应该做什么
如何针对当前用例对 Opus 4.6 进行基准测试
现在最有价值的一件事,是针对 Opus 4.6 运行你自己的评估——不是对照基准测试,而是针对你的实际工作负载。SWE-bench 等通用基准测试使用标准化脚手架测试孤立的问题解决能力。你的生产编程智能体有其特定的代码库结构、特定的任务集和特定的失败模式。这些才是真正重要的。
针对编程智能体的实用基线评估可能如下所示:
# 简单的任务成功率追踪
results = {
"task_id": [],
"model": [],
"success": [],
"turns_needed": [],
"context_used_tokens": [],
"cost_usd": []
}
# 通过 Opus 4.6 运行同样的 20-30 个代表性任务
# 追踪:首次尝试是否成功?需要几轮?
# 消耗了 100 万上下文窗口的多大比例?
# 在哪里失败——推理错误、工具使用还是上下文溢出?这样做的意义在于:当 Mythos 正式开放时,你将拥有真实的基线,可以评估其能力提升是否值得为你的特定工作流支付溢价。Anthropic 内部测试套件上的”大幅更高”,不一定能转化为你特定代码库结构和任务分布上的实质性差异。
“最佳模型”是那个与你的沟通方式相匹配的模型。在出色框架中使用中等模型,胜过在糟糕框架中使用前沿模型。你的框架质量——提示词工程、工具配置、CLAUDE.md 结构——是你现在就能改进的变量。Mythos 无法修复设计糟糕的智能体架构。
能随更强模型扩展的架构决策
好消息是,设计良好的智能体架构在路由层是模型无关的。现在值得构建的模式:
将编排与执行分离。 一个负责分解任务、分配文件、审查输出的编排智能体——由专门负责实现的子智能体支撑——只需修改单个参数即可切换基础模型。现在建立这种分离,Mythos 的升级就变成一次配置更新,而非架构重构。
将 CLAUDE.md 作为运行时上下文,而非会话级提示词。 CLAUDE.md 文件充当仓库中 AI 智能体的”宪法”——提供项目架构、编码规范和构建命令等必要上下文,使智能体无需人工微观管理即可运作。结构良好的 CLAUDE.md 能降低今天 Opus 4.6 的每任务探索成本,并在明天放大更强模型带来的收益。
为 100 万上下文窗口而设计,而非绕过它。 已经针对 100 万窗口重新调整了文件加载策略、分块逻辑和上下文管理的团队,将能充分利用 Mythos 在同等窗口内的推理能力。不要为假设上限不会提升的上下文限制构建变通方案。
发布时编程团队应关注什么
对开发者而言最重要的信号,与通用企业信号有所不同。对专注编程的团队来说:
发布时的 SWE-bench 和 Terminal-Bench 分数。 Anthropic 历来在模型发布时同步公布这些数据。如果 Mythos 兑现了”大幅更高”的承诺,你应该会看到 Terminal-Bench 2.0 分数明显超过 Opus 4.6 的 65.4%。跳升至 75% 以上将验证其对智能体工作流的价值。
Claude Code 模型字符串更新。 关注 Claude Code 文档和 API 模型概览中的新模型别名。Claude Code 历来在新旗舰发布后数天内更新默认模型。如果 Mythos 向公共 API 开放,这里将是编程团队最先看到它的地方。
智能体团队兼容性公告。 智能体团队随 Opus 4.6 以实验性功能的形式发布。Mythos 是否在发布时原生集成智能体团队——还是需要单独配置——将决定团队将其纳入多智能体工作流的速度。
Anthropic 更新日志和定价文档。 这两个页面是任何新闻公告之前最早可靠的信号。新的模型字符串和新的定价行将首先出现在这里。
常见问题
Claude Mythos 现在可以用于编程任务吗?
不能。截至 2026 年 4 月初,Claude Mythos 或 Capybara 层级没有公开的 API 端点。Claude Mythos / Capybara 仅对 Anthropic 选定的一小批早期访问客户开放,没有公共 API、没有公布定价、也没有确认的发布日期。Claude Opus 4.6——SWE-bench Verified 80.8%、Terminal-Bench 2.0 65.4%——仍是目前公开可用的最佳选择。
Claude Mythos 能与 Claude Code 配合使用吗?
几乎可以肯定,最终会的。Claude Code 的架构是模型无关的;切换到新旗舰只需修改单个参数。但这一点在 Mythos 发布时尚未得到确认。
我是否应该等待 Mythos 再开始构建 AI 编程工具?
不应该。Anthropic 已表示需要”在任何公开发布之前变得更加高效”。现在基于 Opus 4.6 进行构建,意味着当 Mythos 到来时你的架构已经过生产验证。升级只是修改一个模型字符串。等待的团队将会陷入被动追赶。
往期文章:




