Z-Image-Turbo LoRA现已登陆WaveSpeed:应用自定义风格(最多3个LoRA)
使用Z-Image-Turbo LoRA应用自定义风格、角色形象和品牌识别。最多可叠加3个LoRA,每张图片仅需$0.01。包含训练指南(每1000步$1.25)。

嗨,我是 Dora。你是否和我一样,厌倦了设计稿总是偏离品牌风格——蓝色总是偏向青绿,logo 边缘变得模糊,产品图看起来……差不多对,但又不完全对。草稿阶段差不多就行,但这会引入噪音。所以上周,我尝试了在 WaveSpeed 上使用 LoRA 配合 Z-Image-Turbo。不是为了追求新奇,而是想看看能否让”差不多”变成”可以上线”,而不需要一直盯着提示词反复调整。
以下是我的使用笔记——什么有效,哪里卡壳,以及我如何配置,让它一旦调好就能自动运转。
什么是 LoRA?
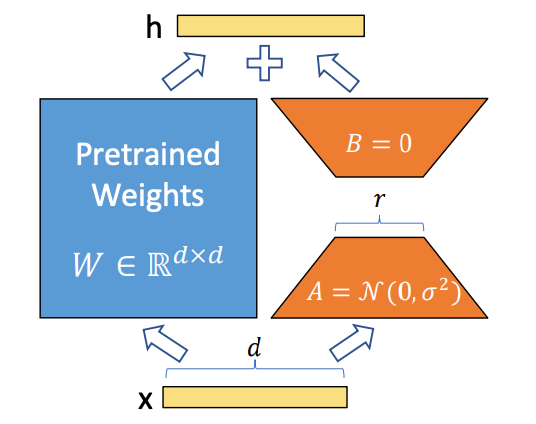 LoRA(低秩适应)是一个小型、精准的层,它能将大模型引导向特定风格、角色或美学方向,而无需重新训练整个模型。可以把它理解为一块可随时添加或取下的柔和滤镜。基础模型保留其广泛能力,LoRA 则教它学会某种偏好。
LoRA(低秩适应)是一个小型、精准的层,它能将大模型引导向特定风格、角色或美学方向,而无需重新训练整个模型。可以把它理解为一块可随时添加或取下的柔和滤镜。基础模型保留其广泛能力,LoRA 则教它学会某种偏好。
实际使用中,LoRA 文件体积小、训练快、切换成本低。最后这点对工作流程尤为重要。我不想为每个品牌色板或角色单独维护一个模型检查点,我想要一个快速的骨干模型(Z-Image-Turbo)加上几个可替换的调节旋钮。
为什么在 Z-Image-Turbo 上使用 LoRA?
 WaveSpeed 上的 Z-Image-Turbo 专为速度优化,非常适合快速迭代,但速度本身解决不了”风格一致性”的问题。LoRA 正好填补了这个空缺。我可以:
WaveSpeed 上的 Z-Image-Turbo 专为速度优化,非常适合快速迭代,但速度本身解决不了”风格一致性”的问题。LoRA 正好填补了这个空缺。我可以:
- 保持基础模型的快速响应,
- 挂载预制 LoRA 来实现某种外观或角色,
- 或者为自己的资产训练一个小型自定义 LoRA。
让我意外的是 scale(强度)参数给了我多大的控制空间。较小的 scale(0.3–0.6)保留了基础模型的优势,较高的(0.8–1.0)则会更强力地推向所学风格,有时会用过头。我从低值开始,逐步调高直到感觉合适。这个简单习惯在那一周里让我的重新渲染次数减少了约三分之一。
使用预制 LoRA
我首先尝试了预制 LoRA,因为在了解边界之前我不想自己训练任何东西。WaveSpeed 将 LoRA 当作插件处理,指向文件,设置强度,直接运行。
寻找兼容的 LoRA
兼容性取决于格式和基础模型系列。如果一个 LoRA 是基于相似的扩散骨干训练的(并标注为与 Z-Image-Turbo 或其同系列兼容),通常表现良好。我维护了一个简短的检查清单:
- 相同或相近的基础模型系列,
- 版本说明(如有,注明日期和模型标签),
- 展示多样性的预览图,而不只是精心挑选的最佳结果。
当一个 LoRA 看起来”太完美”时,我会怀疑过拟合。在我的测试中,这类 LoRA 在超出特定范围的提示词下容易崩溃。更优质的 LoRA 集在我改变光线或镜头描述时依然稳定。
API 参数:path + scale
 WaveSpeed 的 API 为每个 LoRA 使用简单的结构:path(LoRA 文件的位置)和 scale(应用强度)。path 可以是托管在 WaveSpeed 的资产路径,也可以是你自己控制的签名 URL。scale 是浮点数,我大多数时候保持在 0.35 到 0.7 之间。低于 0.3,我往往感觉不到效果;高于 0.8,有时会破坏构图。
WaveSpeed 的 API 为每个 LoRA 使用简单的结构:path(LoRA 文件的位置)和 scale(应用强度)。path 可以是托管在 WaveSpeed 的资产路径,也可以是你自己控制的签名 URL。scale 是浮点数,我大多数时候保持在 0.35 到 0.7 之间。低于 0.3,我往往感觉不到效果;高于 0.8,有时会破坏构图。
实际运行中的一个小提示:如果 path 错误,或资产因缺少正确 token 而私有,你不会总是收到明显报错——你只会得到看起来像基础模型输出的图片。当结果看起来莫名其妙地泛泛时,我会再次核查 path。
叠加多个 LoRA(最多 3 个)
你可以叠加最多三个 LoRA。我尝试了一个用于色彩处理,一个用于品牌纹理,一个用于角色特征。结果可行,但前提是平衡好各自的 scale。如果两个 LoRA 互相冲突(比如一个坚持柔和胶片颗粒,另一个要增加清晰产品光泽),图像会显得摇摆不定。我的原则:
- 每个先设为 0.3,
- 确定主 LoRA(不可妥协的核心风格),
- 缓慢提升该 LoRA 的值,
- 再微调其他 LoRA 直至相互补充而非竞争。
当我需要同时呈现品牌感和固定角色时,叠加确实节省了时间。但当我试图强行叠加三个风格很重的 LoRA 时,反而让我回到了反复试错的状态。
API 实现
下面是我在一个小脚本里的接入方式。我用的是实际工作中的提示词:带背景变化的产品样机,以及几张用于内部文档的角色图。
LoRA 参数结构
请求体包含一个 loras 数组,每个元素包含:
- path:字符串(WaveSpeed 资产路径或签名 URL)
- scale:浮点数(0.0–1.0,建议从 0.3–0.7 开始)
其他 Z-Image-Turbo 参数(prompt、negative_prompt、seed、steps、width/height)照常使用。固定 seed 帮助我在对比 scale 变化时做到同等条件下的比较。
Python 代码示例
import requests
API_KEY = "YOUR_WAVESPEED_KEY"
ENDPOINT = "https://api.wavespeed.ai/api/v3/wavespeed-ai/z-image/turbo"
payload = {
"prompt": "minimal product photo of a cobalt-blue bottle on soft textured linen, natural window light, 50mm, f2.8",
"negative_prompt": "text, watermark, harsh shadows, warped label",
"width": 768,
"height": 768,
"steps": 16,
"seed": 12345,
"loras": [
{"path": "wavespeed://assets/brand/linen_texture_lora.safetensors", "scale": 0.45},
{"path": "wavespeed://assets/brand/cobalt_hue_lora.safetensors", "scale": 0.55}
]
}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
r = requests.post(ENDPOINT, json=payload, headers=headers, timeout=60)
r.raise_for_status()
result = r.json()
# 根据你的账户设置,返回 base64 图片或 URL
print(result.get("images", []))在我的实际运行中,Z-Image-Turbo 使用 16 步已足够用于预览质量。正式图片我会调高到 22–24 步,每张图大约增加 0.3–0.6 秒,在可接受范围内。
平衡 LoRA 强度
我的迭代方式如下:
- 固定 seed,
- 将所有 LoRA 设为 0.3,
- 选出主 LoRA,每次提升 0.1 直到感觉合适,
- 其他 LoRA 以 0.05–0.1 为步长微调。
在调节 scale 时保持 seed 固定,能直观看到变化效果。一旦平衡感觉对了,就放开 seed 以获得多样性。这开始时并没有节省时间——我花了 15–20 分钟才找到感觉。但到第三天,我发现自己已经不再反复修改提示词了。风格由 scale 来承载,我反而可以专注于排版和文案。
训练自定义 LoRA
用过预制 LoRA 之后,我为某客户的瓶型和标签风格训练了一个小型 LoRA,目的是减少来回沟通,因为瓶颈角度和标签光泽总是跑偏。
准备训练数据(ZIP 上传)
我收集了 18 张图片,清理了背景,保持元数据一致。打成 zip 包——简单的文件夹、小写文件名、不带空格——然后上传。当标签文字很重要时,我为每张图添加了 3–4 条说明。不重要时则尽量简洁。更多说明有助于标签文字保持清晰可读。
一个小摩擦点:几乎相同的图片帮助不大。我删除了近似重复项后,过拟合情况明显减少。
训练参数
我保持了轻量配置:
- 分辨率:768 方形裁剪,
- batch size:1,
- 学习率:保守的默认值,
- 训练步数:风格 + 形态为 3,000–6,000 步,
- 网络秩(r):适中,调高会让效果变得”太响”。
步数超过约 8,000 后,它开始在我没有要求的提示词中强行加入瓶形,并不理想。步数少一些配合更干净的数据集效果更好。
定价:每 1,000 步 $1.25
 我的两次训练(3,500 步和 5,000 步)按每 1,000 步 $1.25 计算,合计花费 $10.63。如果这个 LoRA 能用上几个月,这个成本是合理的。
我的两次训练(3,500 步和 5,000 步)按每 1,000 步 $1.25 计算,合计花费 $10.63。如果这个 LoRA 能用上几个月,这个成本是合理的。
典型训练预算
我现在的预算参考:
- 纯风格 LoRA:2,000–4,000 步($2.50–$5.00),
- 带表情的角色:5,000–8,000 步($6.25–$10.00),
- 产品形态 + 标签细节:3,000–6,000 步($3.75–$7.50)。
我会先跑一次较短的训练,检验结果,如果有潜力再补充步数。两次较小的训练比一次漫长的过拟合训练要好得多。
使用场景
以下是 Z-Image-Turbo 上的 LoRA 帮助我更快交付的场景——不是每天都用,但在任务合适时确实可靠。

品牌风格一致性
如果你厌倦了在每个提示词里重复品牌关键词,一个强度在 0.4–0.6 的轻量风格 LoRA 能让色彩、对比度和纹理保持统一。我用它来制作社交媒体变体和网页横幅。它不会让作品变得出色,只会让它们变得一致。这才是重点。每个交付物我大约节省了 5–7 分钟,跳过了第二轮”调整氛围”。
角色 LoRA
用于内部文档和出现在引导界面中的轻量吉祥物,角色 LoRA 让各角度的面部特征保持稳定。叠加柔和色彩处理是可行的,但前提是将角色 scale 降到 0.35。再高就会压制光线效果。调好之后,它消除了一种奇怪的心理负担:我不再担心脸部会跑偏。
产品特定美学
自定义瓶型 LoRA 减少了标签变形,并在特写镜头中保持了瓶颈几何形状。虽然不完美——紧密反光仍需要试几次——但它降低了不可用渲染的数量。悄然的收获是可预测性。当我输入”四分之三角度,亚麻布背景”,我得到的就是这个,而不是意料之外的变体。
适合这种方式的人:已经清楚自己想要什么、厌倦了反复和模型”争论”的人。不适合的人:每次都想探索全新风格的人。LoRA 是一个稳定器,当你重视减少意外胜过追求惊喜时,它才能发挥最大价值。




