DeepSeek V4 API Python:流式响应的最少代码示例
DeepSeek V4的即插即用Python代码。聊天补全、代码生成和流式响应处理。

大家好!我是Dora。一切始于一个小烦恼:我不停地在项目之间复制相同的聊天补全样板代码,像换标签一样替换基础URL和模型名称。这不算难事,只是那种给你一天增添摩擦的活儿。我看到DeepSeek出现的次数足够多,引起了我的好奇,所以在2026年1月下旬花了几个早晨,把他们的”V4” API接入我的Python技术栈,看看实际用起来感觉如何。
在 WaveSpeedAI 上即刻可用 — 按 token 透明计费,OpenAI 兼容端点。 DeepSeek V3.2 API → · DeepSeek R1 API → · 打开 Playground →
我不是在追基准测试。我想知道的是:客户端会不会碍事,能不能可靠地进行流式传输,错误是否以容易理解的方式抛出?以下是我尝试的内容、绊住我的地方,以及默默运行良好的部分。开始吧!
环境设置
依赖项
我在macOS上用Python 3.11保持了简单的设置。用标准库也能完成,但三个小包让生活更轻松:
- requests(简单直接的HTTP:大多数场景够用了)
- httpx(异步请求和表现良好的超时控制)
- python-dotenv(这样我就不用到处粘贴密钥了)
 如果你计划用Server-Sent Events进行流式传输,可以用requests自己解析行(我就是这么做的),或者引入一个辅助库比如sseclient-py。我坚持用requests,活动部件更少。
如果你计划用Server-Sent Events进行流式传输,可以用requests自己解析行(我就是这么做的),或者引入一个辅助库比如sseclient-py。我坚持用requests,活动部件更少。
安装
pip install requests httpx python-dotenv我还为每个项目创建了一个最小的虚拟环境。这是老生常谈的建议,但三个月后重新回来时它能帮你避免依赖漂移的痛苦。
API密钥配置
我将密钥存储在环境变量中。没什么花哨的:
# .env
DEEPSEEK_API_KEY=your_key_here然后在Python中:
from dotenv import load_dotenv
import os
load_dotenv()
API_KEY = os.getenv("DEEPSEEK_API_KEY")
if not API_KEY:
raise RuntimeError("Missing DEEPSEEK_API_KEY")设置中的两个小提示:
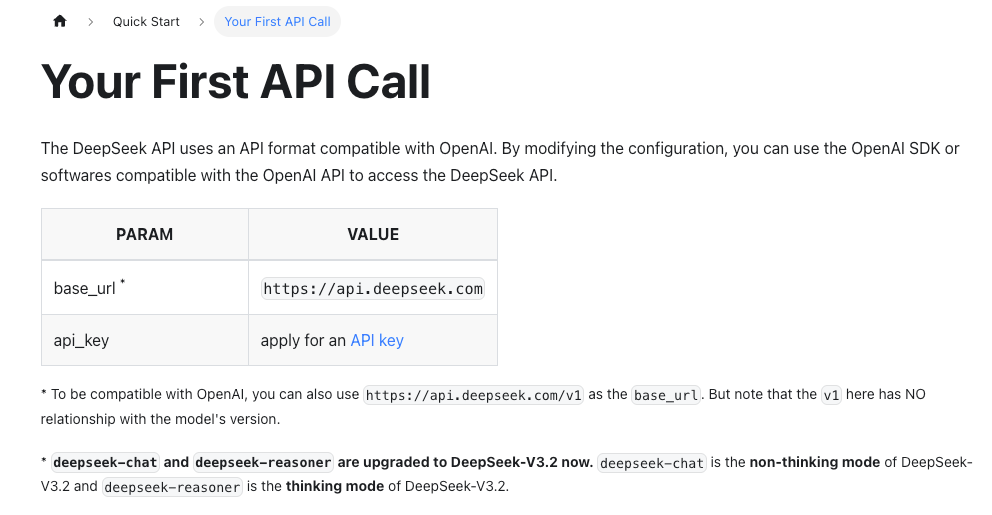
- 基础URL和模型名称比你想象的更新更频繁。我在每次运行前都会查看官方DeepSeek API文档来确认路径和可用模型。
- 我保持超时设置明确。这是个好习惯,一旦遇到速率限制或网络波动就会见效。
基本聊天请求
如果你在别处用过聊天补全,这个思路会很熟悉。DeepSeek提供了一个带有 messages=[{"role": "...", "content": "..."}] 的聊天端点。这很方便,因为我不需要重新构造我的提示词。
以下是我用requests发出的最简请求。模型名称因账户和地区而异,在我的测试中看到了deepseek-chat和deepseek-reasoner这样的引用。如果你的文档提到了”V4”模型字符串,就用那个。否则,选择你控制台中列出的最接近的通用聊天模型。
import os
import requests
API_KEY = os.environ["DEEPSEEK_API_KEY"]
BASE_URL = "https://api.deepseek.com/v1/chat/completions"
payload = {
"model": "deepseek-chat", # check docs/console for the exact model
"messages": [
{"role": "system", "content": "You are a concise assistant."},
{"role": "user", "content": "Give me two bullet points on the value of clear commit messages."}
],
"temperature": 0.3,
"max_tokens": 200
}
resp = requests.post(
BASE_URL,
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json=payload,
timeout=30
)
resp.raise_for_status()
data = resp.json()
content = data["choices"][0]["message"]["content"]
print(content)实践笔记
- 第一次运行波澜不惊(这令人安心)。结构与我预期的一致,迁移一个小型提示词库很快就完成了。
- 我保持低温度以获得可重复的答案。这听起来很明显,但排查问题时我还是会忘。
- 如果你需要确定性运行,也可以固定top_p和seed(如果API支持的话)。当文档没有说明时,我默认假设是非确定性的。
如果你在比较不同供应商,这里的优势是低摩擦。缺点是差异隐藏在细节中——错误响应体、token计数和流式传输格式。这些细节决定了你的集成是感觉稳固还是恼人。
代码生成示例
我不会让模型写完整的模块,那会变成一个清理工程。但对于小的辅助函数,比如”解析这个时间戳格式”或”用占位符起草SQL”,还挺方便的。 我使用了一个狭窄的提示词、一个明确的约定和较小的输出限制。这让模型不会跑偏,也让diff容易审查。
import requests, os
API_KEY = os.environ["DEEPSEEK_API_KEY"]
BASE_URL = "https://api.deepseek.com/v1/chat/completions"
messages = [
{"role": "system", "content": (
"You generate small, safe Python helpers. "
"Return only code inside one block."
)},
{"role": "user", "content": (
"Write a Python function `parse_yyyymmdd` that takes a string like '2026-01-31' "
"and returns a datetime.date. If invalid, return None. No external deps."
)}
]
resp = requests.post(
BASE_URL,
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json={
"model": "deepseek-chat", # or your V4-capable model
"messages": messages,
"temperature": 0,
"max_tokens": 250
},
timeout=30
)
resp.raise_for_status()
code = resp.json()["choices"][0]["message"]["content"]
print(code)实践中有帮助的是:
- 我总是告诉它只返回代码。如果跳过这步,我会收到不需要的总结语句。
- 温度设为0减少了琐碎的修改。
- 我无论如何都会通读一遍逻辑。在我的运行中,它处理了ValueError,但我仍然为空白字符添加了额外的测试。现在多花两分钟,以后能省下几个小时的意外。
第一次用并没有节省时间。写了三四个小辅助函数之后,我注意到它减少了脑力消耗:更少的标签页切换,更少的”strptime的确切代码怎么写来着?“时刻。对我来说这就够了。
流式响应
对于任何可能变长的提示词,我都喜欢用流式传输。它让我在答案偏离时可以提前中止,也让长响应不那么令人焦虑。
在我的测试中,DeepSeek的流式传输使用了常见的模式:设置 stream=true 并读取数据行直到 [DONE]。我不需要特殊的客户端,requests 配合 iter_lines 就够了。
import os, json, requests
API_KEY = os.environ["DEEPSEEK_API_KEY"]
BASE_URL = "https://api.deepseek.com/v1/chat/completions"
payload = {
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "Be brief."},
{"role": "user", "content": "Summarize this: Streaming keeps the UI responsive and lets me stop early."}
],
"stream": True,
"temperature": 0.2,
}
with requests.post(
BASE_URL,
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json=payload,
stream=True,
timeout=60
) as r:
r.raise_for_status()
for line in r.iter_lines(decode_unicode=True):
if not line:
continue
if line.startswith("data: "):
chunk = line[len("data: "):]
if chunk == "[DONE]":
break
try:
obj = json.loads(chunk)
delta = obj["choices"][0]["delta"].get("content", "")
if delta:
print(delta, end="", flush=True)
except json.JSONDecodeError:
# I keep a small log when this happens: usually network blips
pass
print()两个我喜欢的小行为:
- 早期token到达很快(干净连接上一两秒钟)。不算科学测量,但当我把它接入CLI工具时足以感觉流畅。
[DONE]标记可靠地出现。这听起来微不足道,直到它不出现为止——缺失的终止符会让UI挂起。
如果你需要流式传输到Web应用,我建议在中间放一个薄的服务端层来规范化事件。多一个步骤,但能让你的前端保持简洁。
Server-Sent Events
在底层,你实际上是在读取Server-Sent Events。如果你更喜欢用辅助库,sseclient-py 可以用,但只要你防范了不完整的行和超时,自己处理也完全没问题。DeepSeek API文档上关于流式传输的页面足以让你顺利运行起来。
错误处理
 我遇到的大多数错误都是可预见的:缺少密钥、错误的模型名称,或者当我限制网络模拟旅途中的Wi-Fi时出现超时。
一个我反复使用的小模式:
我遇到的大多数错误都是可预见的:缺少密钥、错误的模型名称,或者当我限制网络模拟旅途中的Wi-Fi时出现超时。
一个我反复使用的小模式:
import httpx, time, os
API_KEY = os.environ["DEEPSEEK_API_KEY"]
BASE_URL = "https://api.deepseek.com/v1/chat/completions"
RETRIABLE = {408, 409, 425, 429, 500, 502, 503, 504}
async def chat_once(client, messages):
resp = await client.post(
BASE_URL,
headers={"Authorization": f"Bearer {API_KEY}"},
json={
"model": "deepseek-chat",
"messages": messages,
"temperature": 0.2,
"max_tokens": 300,
},
timeout=30,
)
if resp.status_code == 401:
raise RuntimeError("Unauthorized. Check DEEPSEEK_API_KEY and account access.")
if resp.status_code == 404:
raise RuntimeError("Endpoint or model not found. Confirm model name in console/docs.")
if resp.status_code in RETRIABLE:
raise RuntimeError(f"Retryable status: {resp.status_code}")
resp.raise_for_status()
return resp.json()
async def chat_with_retries(messages, attempts=4):
backoff = 0.5
async with httpx.AsyncClient() as client:
for i in range(attempts):
try:
return await chat_once(client, messages)
except RuntimeError as e:
msg = str(e)
if "Retryable status" in msg and i < attempts - 1:
time.sleep(backoff)
backoff *= 2
continue
raise一些实际注意事项:
- 速率限制:并行测试时我收到了429。指数退避有帮助,但我还加了小幅抖动(随机50-150ms)来避免惊群效应。
- 超时卫生:我为快速检查设置了较短的连接/读取超时(5-10秒),为大型提示词设置了较长的超时。超时不该全都默认30秒:那会掩盖问题。
- 错误响应体:当请求失败时,JSON响应体包含一条我可以记录到日志的消息。我仍然把它包装在自己的异常中,这样我能控制到达UI的内容。
如果你的代码库已经采用OpenAI风格的架构,这就很好处理:相同的消息格式,略有不同的细节。关键是对模型名称要严格,并在非2xx响应时记录完整的响应体,这样你就不用猜了。 从文档角度来说,我依赖官方DeepSeek API文档来获取参数名称和流式传输格式。每当供应商使用熟悉的端点时,很容易假设是一样的。我已经学会了先查文档,少在客户端之间复制粘贴。
谁可能会喜欢这个

- 如果你已经有一个Python聊天补全的封装,迁移路径很平缓。
- 如果你关心流式传输和简单的重试,它的行为是可预测的。
- 如果你需要非常具体的功能(函数调用模式、推理token或批量作业),你会想仔细阅读文档,并用一个小任务先做原型验证再正式投入。
我没有尝试在这里编排长的、多步骤的AI代理。我专注于小的、日常使用的提示词——那种能减少摩擦的类型。这正是DeepSeek V4 API配合Python感觉足够稳定、值得保留的地方。





