Производительность Claude Mythos в программировании: что это значит для рабочих процессов ИИ-разработки
По имеющимся данным, Claude Mythos значительно превосходит Opus 4.6 в задачах программирования. Вот что это означает для разработчиков, создающих агентов ИИ-кодирования в 2026 году.

Все сосредоточились на угрозе кибербезопасности, когда Fortune опубликовал дерзкий заголовок: Anthropic случайно оставил открытыми почти 3 000 внутренних файлов, включая черновик поста в блоге, рекламирующего их не выпущенную модель. Но как человека, который каждый день работает с Claude, меня привлекло не само утечка — а тихие, взрывные утверждения, зарытые в том черновике о производительности при написании кода.
Доступно на WaveSpeedAI — прозрачная цена за токен, OpenAI-совместимый endpoint. Claude Opus 4.7 API → · Claude Sonnet 4.6 API → · Открыть Playground →
В этой статье я, Дора, и вы не будем гнаться за хайпом или паникой из-за безопасности, а сразу перейдём к тому, что реально важно для разработчиков и команд, выпускающих реальные продукты — разобрав именно то, что мы знаем (и чего не знаем) о возможностях Claude Mythos / Capybara в области программирования.
Что говорит слитый черновик о производительности Claude Mythos при написании кода
Точная цитата из слитого черновика: «По сравнению с нашей предыдущей лучшей моделью, Claude Opus 4.6, Capybara показывает значительно более высокие результаты в тестах на написание программного кода, академические рассуждения и кибербезопасность, среди прочего».
Это всё, что Anthropic написал о производительности при написании кода. Никакого процента SWE-bench, никакого результата Terminal-Bench, никакой сравнительной таблицы. Фраза «значительно более высокие» — это реальный сигнал: расплывчатый, но не бессмысленный.

Для контекста: Opus 4.6 в настоящее время лидирует среди публично доступных моделей по SWE-bench Verified (~80,8%), Terminal-Bench 2.0 и Humanity’s Last Exam. Официальный представитель Anthropic подтвердил, что модель представляет «значимые достижения в области рассуждений, написания кода и кибербезопасности». Обучение завершено, тестирование раннего доступа идёт, и написание кода явно входит в тройку основных направлений развития возможностей. Всё остальное — умозаключения.
Почему написание кода — важнейшая возможность для этого уровня модели
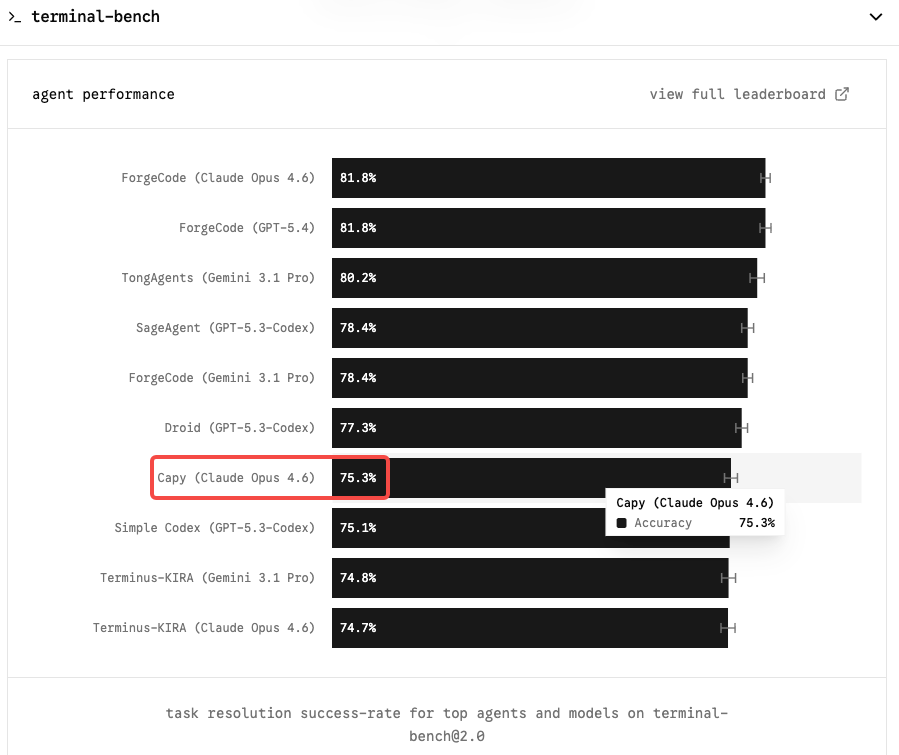
Контекст Terminal-Bench 2.0 и текущие результаты Opus 4.6
Terminal-Bench 2.0 — это бенчмарк, который имеет наибольшее значение для агентных рабочих процессов в области кодирования. В отличие от SWE-bench, который тестирует изолированное решение задач GitHub, Terminal-Bench оценивает реальные задачи в изолированной среде терминала — системное администрирование, DevOps, многошаговые CLI-рабочие процессы. Он сложнее, лучше отражает производственное использование и менее подвержен инфляции за счёт вспомогательных инструментов.
Claude Opus 4.6 занимает первое место с 65,4% на Terminal-Bench 2.0 и 72,7% на OSWorld. Если модель уровня Capybara поднимет этот показатель в диапазон 75–85%, это станет настоящим шагом вперёд для любой команды, запускающей автономных агентов для написания кода.
На SWE-bench Verified картина более сжатая: шесть моделей теперь набирают баллы в пределах 0,8 пункта друг от друга. Opus 4.6 держится на уровне 80,8%; Gemini 3.1 Pro даёт 80,6% при стоимости $2/$12 за миллион токенов. Сырой SWE-bench больше не является значимым дифференциатором. Terminal-Bench и согласованность на длинных контекстах — вот где Opus 4.6 оправдывает свою премиальную цену — и где Mythos, вероятно, заявит о себе наиболее убедительно.
Что «значительно более высокие» означает структурно
В черновике «значительно более высокие» появляется рядом с «шагом вперёд» — той же фразой, что публично использовал представитель Anthropic. Ни один из этих терминов не является случайным. Переход от Opus 4.1 к Opus 4.6 был революционным улучшением внутри одного уровня. «Шаг вперёд» подразумевает нечто качественно иное — скорее как разрыв между Sonnet и Opus, нежели между двумя последовательными версиями Opus.
Модель, которая существенно превосходит Opus 4.6 в написании кода, стала бы значимым инструментом для разработки программного обеспечения, отладки и агентных рабочих процессов. Открытым остаётся вопрос: когда она станет доступной и по какой цене. Вот честная постановка вопроса. Заявление о производительности заслуживает доверия, учитывая последний послужной список Anthropic. Валидации пока просто нет.
Последствия для агентных рабочих процессов в области кодирования
Задачи написания кода с длинным контекстом
Наиболее непосредственное практическое значение модели уровня Capybara для команд разработчиков — это не сырые результаты бенчмарков, а то, что улучшенные рассуждения дают в масштабе.
Контекстное окно Claude Code в 1М теперь доступно в общем доступе для Opus 4.6, предоставляя ~830K используемых токенов после компрессии — достаточно для целых монорепозиториев и полных наборов документации. Модель, значительно превосходящая Opus 4.6 в написании кода и применённая к тому же окну, означает лучшее архитектурное понимание крупных кодовых баз и меньше ошибок рассуждения при рефакторинге нескольких файлов. Контекстное окно не изменится. Качество рассуждений внутри него изменится.
Для команд, которые сегодня занимаются анализом крупных кодовых баз — того рода работой, когда вы загружаете 50K+ строк исходного кода и просите модель понять всю картину целиком, — это наиболее важный практический путь обновления.
Многошаговые агенты отладки
Anthropic выпустил Agent Teams как экспериментальную функцию с релизом Opus 4.6, сделав значительный шаг в агентных рабочих процессах. Одна сессия выступает в роли руководителя команды — координирует работу, назначает задачи и синтезирует результаты. Участники команды работают независимо, каждый в своём контекстном окне, и напрямую общаются друг с другом.
Многошаговые агенты отладки — это именно то место, где накопительная ценность лучшей базовой модели становится наиболее очевидной. В мультиагентной системе качество планирования руководителя команды определяет, насколько хорошо работает вся операция. Более мощная модель принимает лучшие решения по декомпозиции задач, пишет более чёткие спецификации задач для субагентов и раньше выявляет ошибки интеграции.
В слитом черновике написание программного кода наряду с кибербезопасностью специально указывались как области, где Capybara «значительно» превосходит Opus 4.6. Если этот разрыв реален и существен в задачах типа Terminal-Bench, он напрямую выразится в более надёжных многошаговых агентах отладки, требующих меньшего вмешательства человека для исправления неверных предположений.
Самостоятельное исследование кодовой базы
Это сценарий использования, который меня лично интересует больше всего на практике. Claude Code отслеживает проблему в вашей кодовой базе, выявляет первопричину и реализует исправление. Качество этого отслеживания — функция глубины рассуждений, а не только размера контекстного окна.
В типичном рабочем процессе 2026 года разработчик может представить высокоуровневое требование, а ведущий агент декомпозирует его на отдельные задачи, причём участники команды используют Model Context Protocol для одновременного доступа к внешним инструментам, запуска тестов и проведения аудита безопасности. Модель уровня Capybara в роли оркестратора в подобной системе сделает весь рабочий процесс более автономным — то есть меньше запросов на уточнение, лучшая первоначальная декомпозиция задач и более надёжная самокоррекция, когда субагент попадает в неожиданное состояние.
Что делать разработчикам прямо сейчас, пока Mythos недоступен
Как протестировать Opus 4.6 для вашего текущего сценария использования
Самое полезное, что вы можете сделать прямо сейчас, — провести собственную оценку Opus 4.6 — не по бенчмаркам, а по вашей реальной рабочей нагрузке. Общие бенчмарки вроде SWE-bench тестируют изолированное решение задач со стандартизированными вспомогательными инструментами. Ваш производственный агент кодирования имеет конкретную структуру кодовой базы, конкретный набор задач и конкретный режим отказа. Именно это имеет значение.
Практическая базовая оценка агента кодирования может выглядеть так:
# Простое отслеживание успешности выполнения задач
results = {
"task_id": [],
"model": [],
"success": [],
"turns_needed": [],
"context_used_tokens": [],
"cost_usd": []
}
# Запустите те же 20-30 репрезентативных задач через Opus 4.6
# Отслеживайте: удалось ли с первой попытки? Сколько итераций?
# Какую долю контекстного окна в 1М токенов использовала задача?
# Где произошёл сбой — ошибка рассуждения, использование инструментов или переполнение контекста?Причина важности: когда Mythos станет доступен, у вас будет реальная база для оценки того, оправдывает ли улучшение возможностей ценовую надбавку для вашего конкретного рабочего процесса. «Значительно более высокие» результаты на внутреннем тестовом наборе Anthropic могут или не могут выражаться в значимой разнице для вашей конкретной структуры кодовой базы и распределения задач.
«Лучшая модель» — та, которая соответствует тому, как вы с ней общаетесь. Модель среднего уровня в хорошей системе превосходит передовую модель в плохой. Качество вашей системы — разработка промптов, конфигурация инструментов, структура CLAUDE.md — это переменная, которую вы можете улучшить прямо сейчас. Mythos не исправит плохо спроектированную агентную архитектуру.
Архитектурные решения, которые масштабируются с более мощной моделью
Хорошая новость в том, что хорошо спроектированные агентные архитектуры не зависят от конкретной модели на уровне маршрутизации. Паттерны, которые стоит строить уже сейчас:
Разделяйте оркестрацию и исполнение. Агент-оркестратор, который декомпозирует задачи, назначает файлы и проверяет результаты — поддерживаемый специализированными субагентами для реализации — может заменить базовую модель одним изменением параметра. Создайте это разделение сейчас, и обновление до Mythos станет изменением конфигурации, а не архитектурным рефакторингом.
Используйте CLAUDE.md как контекст времени выполнения, а не сессионно-специфичные промпты. Файл CLAUDE.md служит «конституцией» для ИИ-агентов в репозитории — предоставляя необходимый контекст об архитектуре проекта, стандартах кодирования и командах сборки, которые позволяют агентам работать без постоянного контроля человека. Хорошо структурированный CLAUDE.md снижает затраты на исследование каждой задачи в Opus 4.6 сегодня и усилит преимущества более мощной модели завтра.
Проектируйте для контекстного окна в 1М токенов, а не вопреки ему. Команды, которые уже перестроили свою стратегию загрузки файлов, логику чанкования и управление контекстом для работы в рамках окна в 1М, будут готовы в полной мере воспользоваться возможностями рассуждений Mythos в том же окне. Не создавайте обходных путей для ограничений контекста, исходя из предположения, что потолок не поднимется.
На что обращать внимание при запуске для команд, ориентированных на написание кода
Сигналы, наиболее важные для разработчиков, отличаются от общих корпоративных сигналов. Конкретно для команд, ориентированных на написание кода:
Результаты SWE-bench и Terminal-Bench при запуске. Anthropic исторически публикует их одновременно с выпуском моделей. Если Mythos оправдает заявление о «значительно более высоких» результатах, можно ожидать, что результаты Terminal-Bench 2.0 существенно превысят 65,4% Opus 4.6. Прыжок до 75%+ подтвердит это заявление для агентных рабочих процессов.
Обновление строки модели Claude Code. Следите за документацией Claude Code и обзором моделей API на предмет нового псевдонима модели. Claude Code исторически обновлял свою модель по умолчанию в течение нескольких дней после выпуска нового флагмана. Если Mythos выйдет в публичный API, именно здесь он проявится первым для команд, занимающихся написанием кода.
Объявление о совместимости с Agent Teams. Agent Teams вышел как экспериментальная функция с Opus 4.6. От того, интегрируется ли Mythos нативно с Agent Teams при запуске — или потребует отдельной конфигурации, — зависит, как быстро команды смогут внедрить его в мультиагентные рабочие процессы.
Журнал изменений Anthropic и документация по ценообразованию. Эти две страницы — самый ранний надёжный сигнал до любого пресс-объявления. Новая строка модели и новая строка цен появятся здесь первыми.
FAQ
Доступен ли Claude Mythos сейчас для задач написания кода?
Нет. По состоянию на начало апреля 2026 года публичного API-эндпоинта для Claude Mythos или уровня Capybara не существует. Claude Mythos / Capybara доступен только небольшой группе клиентов раннего доступа, выбранных Anthropic, — без публичного API, без объявленного ценообразования и без подтверждённой даты выпуска. Claude Opus 4.6 — 80,8% на SWE-bench Verified, 65,4% на Terminal-Bench 2.0 — остаётся лучшим публично доступным вариантом.
Будет ли Claude Mythos работать с Claude Code?
Почти наверняка да, со временем. Архитектура Claude Code не зависит от конкретной модели; переключение на новый флагман — это изменение одного параметра. Но для Mythos при запуске это не подтверждено.
Стоит ли ждать Mythos, прежде чем создавать инструмент для написания кода с ИИ?
Нет. Anthropic заявил, что ему необходимо стать «значительно более эффективным до любого публичного выпуска». Создание на основе Opus 4.6 сейчас означает, что ваша архитектура прошла производственную проверку к моменту прихода Mythos. Обновление будет сменой строки модели. Команды, которые ждут, будут наверстывать упущенное.
Предыдущие публикации:
Похожие статьи
Представляем ByteDance Seedance 2.0 Mini на WaveSpeedAI

Claude Fable 5: резервный переход на Opus 4.8 — объяснение

GLM-5.2 API: цены, контекст 1M и маршрутизация в продакшене

Цены на GPT-5.4 Mini: стоимость входных, кэшированных и выходных токенов

MAI-Image-2.5 API: что нужно знать разработчикам
