Z-Image-Turbo LoRA на WaveSpeed: применяйте пользовательские стили (до 3 LoRA)
Используйте Z-Image-Turbo LoRA для применения пользовательских стилей, персонажей и фирменного стиля. Комбинируйте до 3 LoRA, $0.01 за изображение. Включает руководство по обучению ($1.25 за 1000 шагов).

Привет, я Дора. Как и вы, я устала от того, что мои макеты постоянно уходили от фирменного стиля: синий цвет всё время смещался в сторону бирюзового, логотип размывался по краям, а фотография продукта выглядела… почти правильно. «Почти» допустимо для черновиков, но это создаёт лишний шум. На прошлой неделе я попробовала LoRA с Z-Image-Turbo на WaveSpeed. Не ради новизны, а чтобы понять, можно ли превратить «достаточно близко» в «да, отправляем» без постоянного присмотра за промптами.
Это мои заметки: что сработало, где застряло, и как я настроила всё так, чтобы оно не мешало, когда уже отрегулировано.
Что такое LoRA?
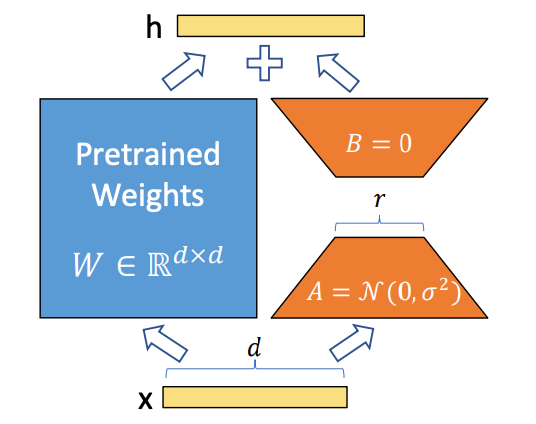 LoRA (Low-Rank Adaptation) — это небольшой, точечный слой, который направляет большую модель к определённому стилю, персонажу или эстетике, без переобучения всей модели. Представьте это как мягкую линзу, которую можно надеть или снять. Базовая модель сохраняет свои широкие возможности: LoRA обучает её предпочтению.
LoRA (Low-Rank Adaptation) — это небольшой, точечный слой, который направляет большую модель к определённому стилю, персонажу или эстетике, без переобучения всей модели. Представьте это как мягкую линзу, которую можно надеть или снять. Базовая модель сохраняет свои широкие возможности: LoRA обучает её предпочтению.
На практике файлы LoRA компактны, быстро обучаются и дёшево заменяются. Последнее важно для рабочих процессов. Мне не нужен отдельный чекпоинт модели для каждой фирменной палитры или персонажа. Мне нужна одна быстрая основа (Z-Image-Turbo) и несколько сменных регуляторов.
Почему LoRA для Z-Image-Turbo?
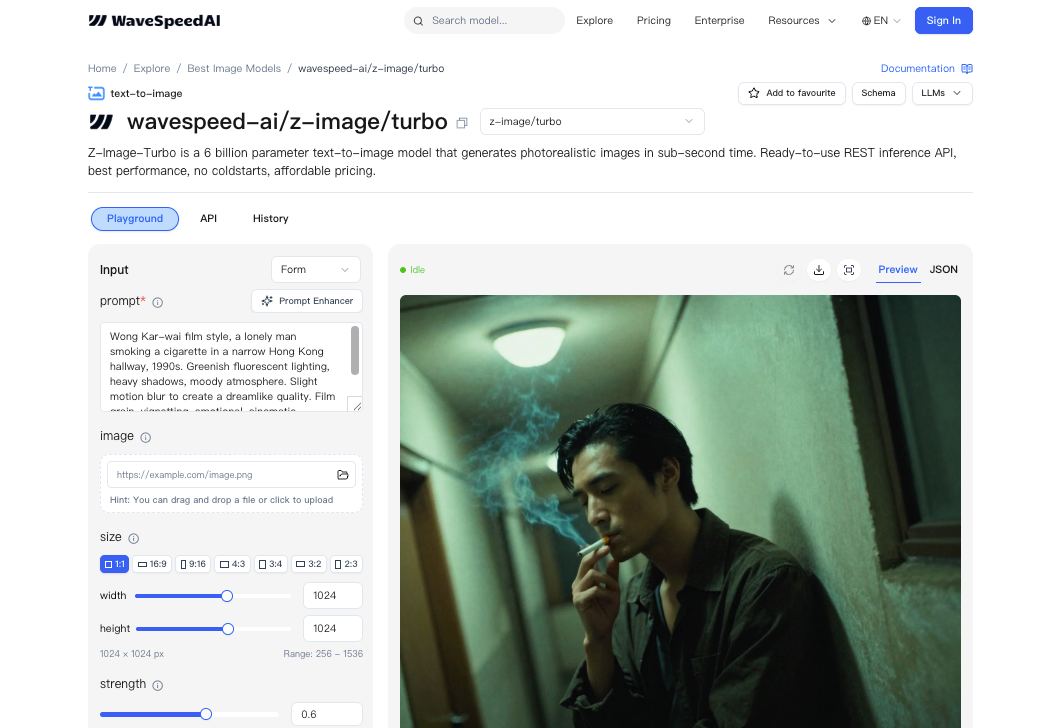 Z-Image-Turbo на WaveSpeed настроен на скорость. Отлично для итераций, но скорость сама по себе не решает проблему «единого стиля». LoRA заполняет этот пробел. Я могу:
Z-Image-Turbo на WaveSpeed настроен на скорость. Отлично для итераций, но скорость сама по себе не решает проблему «единого стиля». LoRA заполняет этот пробел. Я могу:
- сохранять базовую модель быстрой,
- подключать готовую LoRA для определённого вида или персонажа,
- или обучить маленькую кастомную LoRA для своих ресурсов.
Меня удивило, насколько большой контроль давал параметр scale. Небольшое значение (0,3–0,6) сохраняло сильные стороны базовой модели. Более высокое (0,8–1,0) сильнее вдавливалось в выученный стиль — иногда слишком сильно. Я начинала с низкого значения, затем поднимала, пока не казалось правильным. Эта простая привычка за неделю сократила повторные рендеры примерно на треть.
Использование готовых LoRA
Сначала я пробовала готовые LoRA, потому что не хотела ничего обучать, пока не разберусь с границами. WaveSpeed обращается с LoRA как с плагином: укажи файл, задай scale, и вперёд.
Поиск совместимых LoRA
Совместимость зависит от формата и семейства базовых моделей. Если LoRA была обучена на похожей диффузионной основе (и отмечена как совместимая с Z-Image-Turbo или его предшественниками), она, как правило, работала корректно. Я держала короткий чеклист:
- то же или смежное семейство базовых моделей,
- примечания к версии, если есть (дата + тег модели),
- галерея предпросмотра, показывающая разнообразие, а не только отборные удачные результаты.
Когда LoRA выглядела «слишком идеально», я предполагала переобучение. В моих тестах такие LoRA обычно ломались на промптах, выходящих за рамки узкого диапазона. Более качественные наборы держались, когда я меняла освещение или параметры камеры.
Параметры API: path + scale
 API WaveSpeed использует простую структуру для каждой LoRA: path (где находится файл LoRA) и scale (насколько сильно она применяется). Path может быть размещённым ресурсом WaveSpeed или подписанным URL, которым вы управляете. Scale — это число с плавающей точкой. Я работала преимущественно в диапазоне 0,35–0,7. Ниже 0,3 я часто не могла понять, включена ли LoRA; выше 0,8 она иногда разрушала композицию.
API WaveSpeed использует простую структуру для каждой LoRA: path (где находится файл LoRA) и scale (насколько сильно она применяется). Path может быть размещённым ресурсом WaveSpeed или подписанным URL, которым вы управляете. Scale — это число с плавающей точкой. Я работала преимущественно в диапазоне 0,35–0,7. Ниже 0,3 я часто не могла понять, включена ли LoRA; выше 0,8 она иногда разрушала композицию.
Небольшое замечание по реальным запускам: если путь неверен или ресурс приватный без нужного токена, вы не всегда получите явную ошибку — просто изображения будут выглядеть как базовая модель. Когда что-то казалось подозрительно обычным, я перепроверяла путь.
Стекирование нескольких LoRA (до 3)
Можно стекировать до трёх LoRA. Я попробовала одну для цветовой обработки, одну для фирменной текстуры и одну для черт персонажа. Это сработало, но только после того, как я сбалансировала их значения scale. Если две LoRA конфликтуют (например, одна настаивает на мягком зерне плёнки, а другая добавляет чёткий блеск продукта), изображение выглядит нерешительным. Моё правило:
- начинать каждую с 0,3,
- определить якорную LoRA (обязательный вид),
- медленно поднимать её значение,
- слегка настраивать остальные, чтобы они дополняли, а не конкурировали.
Стекирование сэкономило мне время, когда нужны были и фирменный стиль, и повторяющийся персонаж. Оно не экономило время, когда я пыталась одновременно использовать три тяжёлых стиля. Это просто возвращало меня к методу проб и ошибок.
Реализация через API
Вот как я реализовала это в небольшом скрипте. Я использовала промпты, которые реально применяю в работе: макеты продуктов с вариантами фона, плюс несколько снимков персонажей для внутренней документации.
Структура параметра LoRA
Тело запроса включает массив loras. Каждый элемент:
- path: строка (путь к ресурсу WaveSpeed или подписанный URL)
- scale: число с плавающей точкой (0,0–1,0; рекомендую начинать с 0,3–0,7)
Остальные параметры Z-Image-Turbo (prompt, negative_prompt, seed, steps, width/height) работают как обычно. Seeds помогали мне сравнивать изменения scale на равных условиях.
Пример кода на Python
import requests
API_KEY = "YOUR_WAVESPEED_KEY"
ENDPOINT = "https://api.wavespeed.ai/api/v3/wavespeed-ai/z-image/turbo"
payload = {
"prompt": "minimal product photo of a cobalt-blue bottle on soft textured linen, natural window light, 50mm, f2.8",
"negative_prompt": "text, watermark, harsh shadows, warped label",
"width": 768,
"height": 768,
"steps": 16,
"seed": 12345,
"loras": [
{"path": "wavespeed://assets/brand/linen_texture_lora.safetensors", "scale": 0.45},
{"path": "wavespeed://assets/brand/cobalt_hue_lora.safetensors", "scale": 0.55}
]
}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
r = requests.post(ENDPOINT, json=payload, headers=headers, timeout=60)
r.raise_for_status()
result = r.json()
# Ожидайте изображения в base64 или URL в зависимости от настроек вашего аккаунта
print(result.get("images", []))В моих запусках 16 шагов с Z-Image-Turbo было достаточно для качества предпросмотра. Для финальных изображений я поднимала до 22–24 шагов. Это добавляло ~0,3–0,6 секунды на изображение в моём аккаунте, что было приемлемо.
Балансировка значений LoRA scale
Я итерировала так:
- фиксировала seed,
- устанавливала все LoRA на 0,3,
- выбирала якорную LoRA и поднимала её на 0,1, пока не казалось правильным,
- корректировала остальные с шагом 0,05–0,1.
Фиксированный seed при настройке scale помогал видеть эффект напрямую. Когда баланс нравился, я убирала фиксацию seed для разнообразия. Это не сэкономило время сразу — я потратила 15–20 минут только на понимание ощущений. Но на третий день заметила, что перестала редактировать промпты. Значения scale несли стиль, а я сосредоточилась на макете и тексте.
Обучение кастомных LoRA
После готовых LoRA я обучила небольшую LoRA для формы бутылки и стиля этикетки клиента. Я сделала это, чтобы устранить постоянные правки, когда угол горлышка и блеск этикетки продолжали уплывать.
Подготовка данных для обучения (загрузка ZIP)
Я собрала 18 изображений, очистила фоны и сохранила метаданные единообразными. Запаковала их в zip — простая папка, строчные имена файлов без пробелов — и загрузила. Добавила 3–4 подписи на изображение, когда текст этикетки был важен. Когда нет — оставляла подписи минимальными. Больше подписей помогло тексту этикетки оставаться читаемым.
Небольшое неудобство: почти идентичные изображения не помогали. Я удалила дубли и увидела меньше переобучения.
Параметры обучения
Я придерживалась лёгкого подхода:
- разрешение: квадратные кропы 768,
- размер батча: 1,
- скорость обучения: консервативное значение по умолчанию,
- шаги обучения: 3 000–6 000 для стиля и формы,
- ранг сети (r): умеренный: высокое значение делало результат «громче», чем мне нужно.
Когда я превышала ~8 000 шагов, модель начинала навязывать бутылку в промпты, где я её не запрашивала. Нежелательно. Меньше шагов плюс более чистый датасет побеждали.
Цена: $1,25 за 1 000 шагов
 Мои два запуска (3 500 и 5 000 шагов) обошлись в $10,63 суммарно по $1,25 за 1 000 шагов. Это разумно, если LoRA оправдывает себя несколько месяцев.
Мои два запуска (3 500 и 5 000 шагов) обошлись в $10,63 суммарно по $1,25 за 1 000 шагов. Это разумно, если LoRA оправдывает себя несколько месяцев.
Типичный бюджет на обучение
Что бы я закладывала сейчас:
- LoRA только на стиль: 2 000–4 000 шагов ($2,50–$5,00),
- персонаж с выражениями лица: 5 000–8 000 шагов ($6,25–$10,00),
- форма продукта + детали этикетки: 3 000–6 000 шагов ($3,75–$7,50).
Сначала я бы делала один более короткий прогон, проверяла результаты, а затем добавляла шаги, если это перспективно. Два небольших прогона лучше одной долгой сессии с переобучением.
Сценарии использования
Это те ситуации, где LoRA на Z-Image-Turbo помогала мне работать быстрее — не каждый день, но надёжно, когда задача подходила.

Единообразие фирменного стиля
Если вы устали повторно вводить подсказки о бренде в каждый промпт, мягкая LoRA стиля на 0,4–0,6 держит цвет, контраст и текстуру в норме. Я использовала это для вариантов в социальных сетях и веб-баннеров. Это не делало их блестящими — просто делало единообразными. В этом и смысл. Я экономила примерно 5–7 минут на каждый результат, пропуская второй раунд «исправь настроение».
LoRA персонажей
Для внутренней документации и лёгкого маскота, появляющегося на экранах онбординга, LoRA персонажа удерживала черты постоянными при разных ракурсах. Стекирование с мягкой цветовой обработкой работало, но только после того, как я снизила scale персонажа до 0,35. При более высоком значении он заглушал освещение. После настройки это сняло странную умственную нагрузку: я перестала беспокоиться о том, уплывёт ли лицо.
Специфическая эстетика продукта
Кастомная LoRA бутылки снизила искажение этикетки и сохранила геометрию горлышка в крупных планах. Не идеально — чёткие отражения всё ещё требовали пары попыток, — но это сократило количество непригодных рендеров. Тихая победа — предсказуемость. Когда я вводила «угол три четверти на льне», я получала именно это, а не случайный вариант.
Кому это может понравиться: тем, кто уже знает, чего хочет, и устал спорить с моделью. Кому нет: тем, кто каждый раз исследует совершенно новые стили. LoRA — это стабилизатор. Он блистает, когда цените меньше сюрпризов, а не больше фейерверков.
Похожие статьи
Представляем ByteDance Seedance 2.0 Mini на WaveSpeedAI

Claude Fable 5: резервный переход на Opus 4.8 — объяснение

GLM-5.2 API: цены, контекст 1M и маршрутизация в продакшене

Цены на GPT-5.4 Mini: стоимость входных, кэшированных и выходных токенов

MAI-Image-2.5 API: что нужно знать разработчикам
