Gemini 3.1 Flash-Lite: Возможности, сценарии использования и сравнение с Flash
Gemini 3.1 Flash-Lite — самая экономичная инференс-модель Google. Возможности, реальные сценарии использования и прямое сравнение с Gemini Flash.

Я заметила кое-что странное, когда Google выпустил Gemini 3.1 Flash-Lite 3 марта. Обычно они сначала запускают более мощную модель Flash — или вообще пропускают уровень Lite. На этот раз они сразу перешли к бюджетному варианту. Это изменение заставило меня обратить внимание.
Доступно на WaveSpeedAI — прозрачная цена за токен, OpenAI-совместимый endpoint. Gemini 2.5 Pro API → · Gemini 2.5 Flash Lite API → · Открыть Playground →
Меня зовут Дора. Я тестировала её последний день, и что меня удивило — не только скорость. Это то, как ценовая структура внезапно сделала определённые рабочие процессы… доступными в том смысле, в котором они таковыми не были раньше.

Что такое Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite занимает нижнюю ступень в новейшей линейке моделей Google, но «нижняя» уже не означает того, что раньше. Согласно официальной документации Google, это их наиболее экономически эффективная модель Gemini, оптимизированная для сценариев с низкой задержкой и высоким трафиком. Она нацелена на соответствие производительности Gemini 2.5 Flash в ключевых областях, при этом будучи значительно быстрее и дешевле.
Место в линейке Gemini 3.1
Семейство Gemini 3 теперь имеет три чётких уровня. На вершине — Gemini 3.1 Pro — тяжеловес для сложных задач рассуждения. В середине находится Gemini 3 Flash, который сочетает интеллект уровня Pro со скоростью Flash. И теперь Flash-Lite занимает нишу высокого объёма и чувствительности к стоимости.
Что делает это интересным — Flash-Lite не является урезанной версией Flash. На самом деле она основана на архитектуре Gemini 3 Pro, затем оптимизированной специально для пропускной способности и задержки. Этот архитектурный выбор проявляется в бенчмарках — она не просто быстрее, она умнее, чем можно было бы ожидать за эту цену.
Как работает логика уровней Pro / Flash / Flash-Lite
Многоуровневый подход касается не функций — а распределения вычислений. Pro тратит больше токенов на обдумывание сложных задач. Flash балансирует между рассуждением и скоростью. Flash-Lite по умолчанию минимизирует внутреннее рассуждение, но это можно настроить.
Последний момент — новый. Google добавил то, что они называют «уровнями мышления» — минимальный, низкий, средний или высокий. Для простой задачи перевода устанавливаете минимальный и получаете мгновенный результат. Для чего-то, требующего большей точности, повышаете уровень и принимаете немного более высокую задержку и стоимость.
Я попробовала это с партией тикетов службы поддержки клиентов. При минимальном уровне мышления ответы возвращались менее чем за две секунды. При среднем — занимало пять секунд, но улавливало нюансы, которые быстрый проход упустил. Управление ощущается практичным.
Ключевые возможности Gemini 3.1 Flash-Lite
Сверхнизкая стоимость инференса
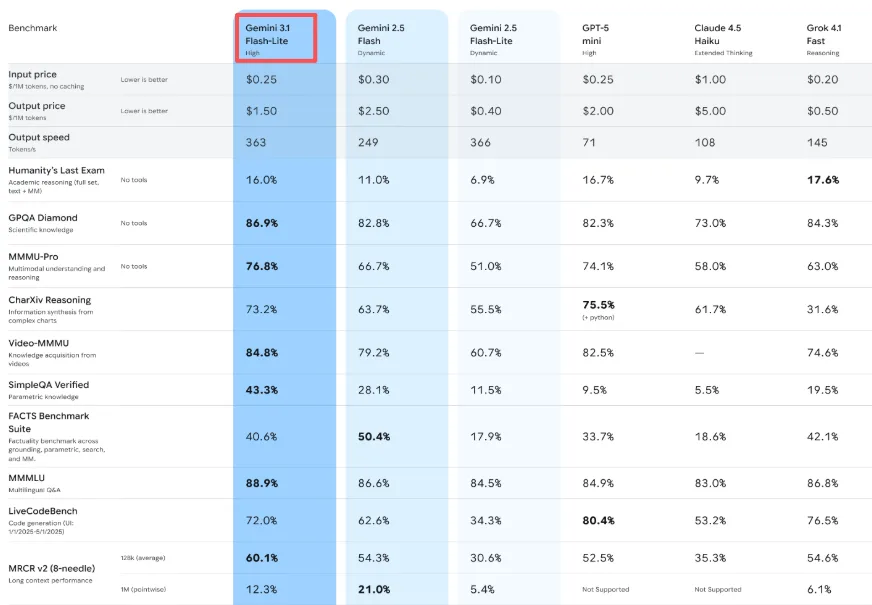
Цена составляет $0,25 за миллион входных токенов и $1,50 за миллион выходных токенов. Для сравнения: Gemini 3.1 Pro начинается от $2,00 за миллион входных токенов и $18 за миллион выходных токенов для требовательных задач. Flash-Lite стоит примерно в восемь раз дешевле Pro для базовых задач.
Но вот что меня удивило — она также дешевле Gemini 2.5 Flash (который стоил $0,30/$2,50), несмотря на большую мощность. Это необычно. Обычно за обновления платишь больше.
Высокая пропускная способность и низкая задержка
Google утверждает, что Flash-Lite генерирует вывод со скоростью 363 токена в секунду, и в моих тестах это ощущается достоверным. Что ещё важнее, время до первого токена — момент, когда вы перестаёте ждать и начинаете видеть вывод — в 2,5 раза быстрее, чем у Gemini 2.5 Flash, согласно их внутренним бенчмаркам.
Я заметила это особенно при построении простого конвейера модерации контента. Разница между трёхсекундным ожиданием и однесекундным не кажется значительной. Но когда вы обрабатываете сотни элементов, эта задержка накапливается. С Flash-Lite конвейер ощущался отзывчивым, а не медлительным.
Поддержка мультимодальных входных данных
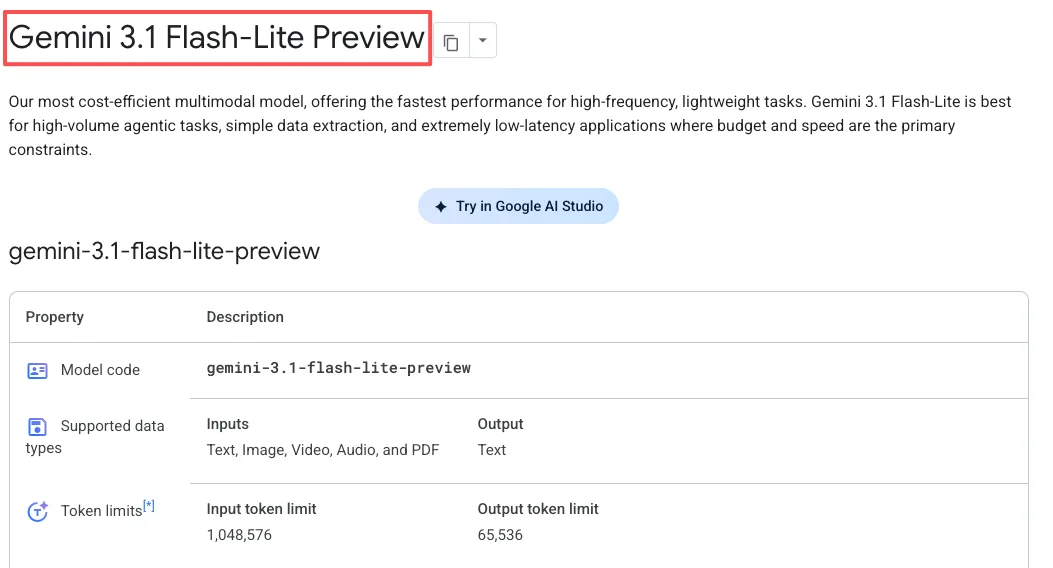
Flash-Lite обрабатывает текст, изображения, аудио и видео. Контекстное окно расширяется до 1 миллиона токенов, и модель может генерировать до 64 000 токенов текстового вывода.
Я тестировала её с набором изображений товаров и описаний для прототипа электронной коммерции. Она отмечала их последовательно и быстро — ранние пользователи, такие как Whering, сообщали о 100% последовательности в маркировке для сложных категорий моды. Такая надёжность важна, когда вы строите системы, которые не могут позволить себе отклонений.
Большое контекстное окно
Контекстное окно в 1 миллион токенов означает, что вы можете передавать в него целые документы, длинные цепочки разговоров или большие наборы данных без предварительного разбиения на более мелкие части. Я редко использую полное окно, но когда использую — например, при анализе многостраничных PDF — это разница между плавным рабочим процессом и раздражающим.
Gemini 3.1 Flash-Lite vs Flash: прямое сравнение
Когда использовать Flash-Lite
Используйте Flash-Lite, когда вы выполняете тысячи или миллионы похожих задач. Конвейеры перевода, очереди модерации контента, анализ тональности в масштабе, базовое извлечение данных — всё, где задача чётко определена, а стоимость за токен важнее глубокого рассуждения.
Я также обнаружила, что она хорошо работает как маршрутизатор. Можно использовать Flash-Lite для классификации входящих запросов как «простых» или «сложных», а затем направлять сложные в Flash или Pro. Это экономит деньги без потери качества там, где это важно.
Когда вместо этого использовать Flash
Если задача требует многоэтапного рассуждения, творческого решения проблем или обработки неоднозначных инструкций, Flash — лучший выбор. Она в два раза дороже, но и умнее — особенно для задач кодирования, где она соответствует или превосходит Pro по некоторым бенчмаркам.
Я тестировала обе на задаче генерации UI-компонентов из подсказок на естественном языке. Flash-Lite справлялась с прямолинейными запросами («создай форму входа»), но затруднялась с расплывчатыми («создай что-то современное и чистое»). Flash справилась с обоими.
Варианты использования Gemini 3.1 Flash-Lite
Маршрутизация AI-агентов и классификация задач
Один из самых чистых вариантов использования, которые я видела, — это использование Flash-Lite в качестве диспетчера трафика. Когда пользователь отправляет запрос, Flash-Lite читает его, определяет сложность и направляет в соответствующую модель — Flash для средних задач, Pro для сложных.
Этот шаблон уже используется в производственных инструментах. Open-source Gemini CLI использует Flash-Lite именно для этого, и это работает, потому что модель достаточно быстра и дёшева, чтобы добавить этот шаг маршрутизации без заметного увеличения задержки или стоимости.
Чат и автоматизация поддержки при высоком объёме
Служба поддержки клиентов — это то место, где экономия действительно проявляется. Если вы обрабатываете десятки тысяч тикетов ежедневно, разница между $0,25 и $2,00 за миллион входных токенов быстро накапливается.
Flash-Lite может обрабатывать простые вопросы, извлекать намерения и направлять тикеты, требующие внимания человека. Она не решит сложные технические проблемы, но и не должна. Ей просто нужно быть надёжной и быстрой.
Модерация и маркировка контента
Я построила быстрый тестовый конвейер для модерации пользовательского контента — отмечая спам, неприемлемые выражения и нерелевантные публикации. Flash-Lite обработала около 500 элементов менее чем за минуту с последовательной точностью.
Ключ здесь — последовательность. Некоторые модели дрейфуют со временем или дают разные ответы на похожие входные данные. Flash-Lite оставалась предсказуемой в повторных прогонах, что важно при построении систем, которые должны вести себя одинаково каждый раз.
Конвейеры предобработки документов
Flash-Lite отлично справляется со структурированным извлечением данных. Получив партию счетов или квитанций, она может извлечь ключевые поля — даты, суммы, названия поставщиков — и вывести их в формате JSON.
Я тестировала это с набором PDF-счетов, и она справилась с большинством из них чисто. С теми, с которыми она испытывала трудности, были сканы низкого качества с плохим текстом, но это ограничение входных данных, а не модели.
Что Flash-Lite означает для проектирования AI-инфраструктуры

Паттерн многоуровневой архитектуры моделей
Выпуск Flash-Lite завершает то, что начинает ощущаться как отраслевой стандартный паттерн: трёхуровневый стек моделей. Есть тяжеловес для сложных задач, сбалансированный вариант для повседневного использования и лёгкий вариант для высокообъёмной повторяющейся работы.
Это не ново — у OpenAI есть GPT-5 / GPT-5 mini, у Anthropic есть Claude Opus / Sonnet / Haiku — но реализация Google интересна тем, что ценовые разрывы шире. Flash-Lite действительно дёшев по сравнению с Pro, что делает определённые рабочие процессы экономически жизнеспособными там, где раньше они таковыми не были.
Дешёвый маршрутизатор + мощный решатель — почему это важно
Паттерн, который я продолжаю наблюдать: используйте дешёвую модель, чтобы определить, с каким типом задачи вы имеете дело, а затем направляйте в более дорогую модель только при необходимости. Это не только про экономию денег. Это также улучшает задержку для простых задач, поскольку вы не ждёте, пока тяжеловесная модель запустится.
Я попробовала это со смешанной партией из 100 задач — половина простых, половина сложных. Используя Flash-Lite в качестве маршрутизатора, простые задачи завершались за секунды, а сложные направлялись во Flash. Общая стоимость была примерно на 40% ниже, чем при прогоне всего через Flash, без потери качества на сложных задачах.
Эта архитектура работает только в том случае, если маршрутизатор достаточно быстр и дёшев, чтобы не стать узким местом. Flash-Lite является таковым.
Текущая доступность и статус API
Gemini 3.1 Flash-Lite доступна сейчас в предварительной версии через Gemini API в Google AI Studio и Vertex AI. Она недоступна в потребительском приложении Gemini — это ориентировано на разработчиков.
Модели предварительной версии могут измениться до стабильного выпуска, и у них более строгие ограничения скорости. На практике я не достигала этих ограничений при обычном тестировании, но если вы планируете производственное развёртывание в серьёзных масштабах, это стоит отслеживать.
Модель также активно обновляется. Примечания к выпускам Google показывают постоянные улучшения следования инструкциям, качества аудиовхода и возможностей рассуждения. Это ещё ранние дни — вероятно, она станет лучше в течение следующих нескольких месяцев.
Мысль напоследок
К чему я продолжаю возвращаться — это не скорость и не стоимость. Это тот факт, что Flash-Lite заставляет определённые рабочие процессы ощущаться не как эксперименты, а как утилиты. Когда стоимость снижается достаточно, вы перестаёте спрашивать «стоит ли использовать AI для этого?» и начинаете спрашивать «как мне построить это так, чтобы оно масштабировалось?»
Этот сдвиг — от новинки к инфраструктуре — это то, где инструменты начинают оставаться надолго.
Похожие статьи
Представляем ByteDance Seedance 2.0 Mini на WaveSpeedAI

Claude Fable 5: резервный переход на Opus 4.8 — объяснение
GLM-5.2 API: цены, контекст 1M и маршрутизация в продакшене
Цены на GPT-5.4 Mini: стоимость входных, кэшированных и выходных токенов
MAI-Image-2.5 API: что нужно знать разработчикам