O Que É SkyReels V4? O Primeiro Modelo Unificado de Vídeo e Áudio com IA Explicado
SkyReels V4 é a primeira IA open-source que gera vídeo e áudio juntos — em 1080p/32FPS. Veja o que faz, como funciona e por que isso é importante.

Olá, sou a Dora. Naquele dia gerei meu primeiro vídeo com o **SkyReels V4**. Quinze segundos de um gato caminhando por um beco encharcado de chuva ao entardecer. O vídeo ficou bom — 1080p, movimentos suaves, iluminação agradável. Mas o que me fez pausar foi o áudio. Passos espirrados em poças d’água. Tráfego ao longe. O eco suave das paredes do beco. Tudo gerado junto, perfeitamente sincronizado, sem eu tocar em nenhuma ferramenta de edição de áudio.
Essa foi a parte que pareceu diferente.
O Problema que Toda Ferramenta de IA para Vídeo Tinha Antes do V4
Por que a geração de apenas vídeo sempre pareceu incompleta
A maioria das ferramentas de IA para vídeo gera clipes silenciosos. Runway, Pika, até as versões anteriores do SkyReels — elas produzem visuais e param por aí. Você obtém uma bela cena de 10 segundos com ondas quebrando na praia, mas ela é completamente silenciosa. As ondas não quebram. O vento não sopra. Não há nenhum som ambiente.
Isso não é uma falha técnica. Gerar áudio sincronizado junto com vídeo é genuinamente difícil. O áudio precisa corresponder não apenas à cena em geral, mas a eventos visuais específicos — passos soando quando os pés tocam o chão, portas fechando quando elas se fecham, vozes sincronizadas com os movimentos dos lábios.
O gargalo de “adicionar áudio na pós-produção”
O fluxo de trabalho padrão se tornou: gerar vídeo, exportar, abrir um editor de áudio, adicionar efeitos sonoros ou música manualmente, sincronizar tudo à mão, exportar novamente. Para um clipe de 15 segundos, isso poderia levar de 20 a 30 minutos.
Tentei isso com saídas do Pika no mês passado. O vídeo parecia profissional. Mas encontrar os sons ambiente certos, cronometrá-los para combinar com as deixas visuais e evitar aquela sensação de “obviamente adicionado depois” consumiu mais tempo do que gerar o próprio vídeo. O fluxo de trabalho parecia quebrado — como comprar um carro mas ter que instalar o motor separadamente.
O que o SkyReels V4 Realmente É
Desenvolvido pela SkyworkAI (a linhagem V1/V2/V3 explicada)
A SkyworkAI lançou o SkyReels V1 no início de 2025 como um modelo básico de texto para vídeo. O V2 veio na sequência com arquitetura de forçamento por difusão que permitia geração de comprimento infinito por meio de sequências autorregressivas. O V3 foi lançado em janeiro de 2026 com aprendizado contextual multimodal — você podia alimentá-lo com imagens de referência, clipes de áudio ou vídeos existentes e ele geraria continuações coerentes.

O V4, que entrou em operação em 25 de fevereiro de 2026, representa um salto de tipo diferente. Enquanto o V3 adicionou recursos, o V4 reestruturou toda a arquitetura em torno de um sistema de fluxo duplo que gera vídeo e áudio simultaneamente.
O que “modelo fundacional unificado de vídeo e áudio” realmente significa
O artigo técnico descreve o V4 como usando um Transformador de Difusão Multimodal (MMDiT) com dois ramos paralelos. Um ramo sintetiza os quadros de vídeo. O outro gera áudio temporalmente alinhado. Ambos os ramos compartilham um codificador de texto baseado em modelos de linguagem de grande porte multimodais, o que significa que processam a mesma compreensão semântica do seu prompt e mantêm a sincronização durante toda a geração.
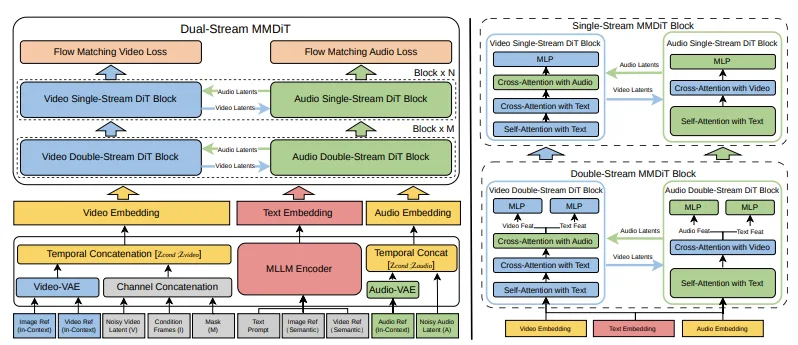
Isso não é geração de vídeo com áudio encaixado depois. É um único modelo que trata visão e som como saídas igualmente importantes, geradas juntas a partir da mesma compreensão latente da cena.
Na prática, isso significa que quando você solicita “uma mulher falando em um púlpito,” o modelo gera tanto o visual dos lábios dela se movendo quanto o áudio real do discurso, sincronizados no nível do quadro. Quando você gera “chuva forte em um telhado de metal,” você obtém tanto o visual da chuva escorrendo quanto o característico som de tamborilar metálico — não correspondência aproximada, mas gerados como um evento audiovisual unificado.
Principais Capacidades em Resumo
Geração conjunta de vídeo + áudio a partir de um único prompt
A geração a partir de um único prompt é a capacidade central. Você escreve “trovão rolando por uma paisagem desértica” e o V4 produz 15 segundos de nuvens se formando, relâmpagos brilhando e trovões sincronizados rumbando de acordo com o tempo visual. Nenhuma etapa separada de geração de áudio. Nenhum trabalho manual de sincronização.
Testei isso com cenas de diálogo. Solicitei “duas pessoas discutindo em um café movimentado” e obtive não apenas o visual da conversa, mas falatório de fundo, barulho de louças e as vozes dos falantes subindo e descendo com a intensidade de seus gestos. A sincronização labial não foi perfeita — notei alguns momentos em que o tempo derivou ligeiramente — mas foi melhor do que qualquer coisa que eu havia sincronizado manualmente.
Saída em 1080p / 32FPS / 15 segundos
Especificações técnicas: até 1080p de resolução, 32 quadros por segundo, duração máxima de 15 segundos. Para contexto, a maioria das ferramentas concorrentes chega no máximo a 720p ou exige tempos de geração significativamente mais longos para saída em HD.
O limite de 15 segundos importa mais do que parece. A maior parte do conteúdo de mídia social vive em fragmentos de 10 a 15 segundos. O YouTube Shorts tem um limite de 60 segundos. O Instagram Reels, de 90. Para esse caso de uso, 15 segundos com áudio sincronizado é mais útil do que 30 segundos de vídeo silencioso que precisam de pós-produção.
Entradas multimodais: texto, imagem, vídeo, máscara, referência de áudio
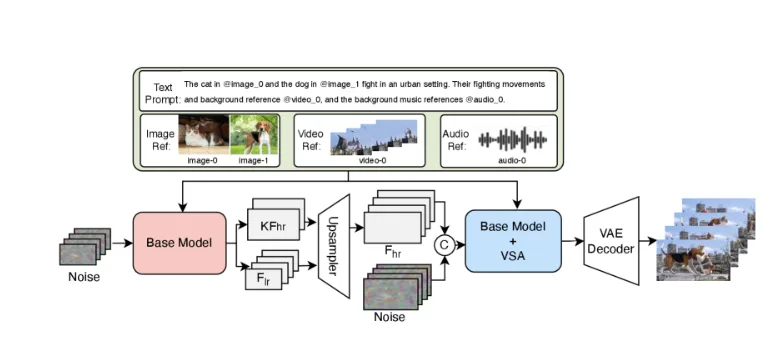
O V4 aceita cinco tipos de entrada: prompts de texto, imagens de referência, clipes de vídeo, máscaras binárias para inpainting e referências de áudio. Você pode combiná-los — fazer upload de uma imagem de uma pessoa específica, fornecer uma amostra de áudio de passos em cascalho e solicitar “caminhando por uma floresta ao amanhecer.” O modelo usa todas as três entradas para orientar a geração.
Testei o prompt multimodal com uma imagem de referência de um estilo arquitetônico específico e um clipe de áudio de ambience de rua. O vídeo gerado manteve os detalhes arquitetônicos da imagem enquanto sobrepunha os sons ambiente da referência de áudio. Não perfeitamente — alguns elementos de áudio pareciam genéricos — mas a capacidade funcionou.
Três tarefas em uma: gerar, inpaint, editar
Além da geração, o V4 lida com inpainting e edição por meio de concatenação de canais. Forneça um vídeo e uma máscara indicando quais regiões modificar, e o modelo regenera apenas essas áreas enquanto preserva o restante. Isso permite tarefas como remover objetos, mudar fundos ou substituir elementos específicos sem regenerar o clipe inteiro.
Como o V4 se Compara ao que Veio Antes
Evolução do V4 em relação ao SkyReels V1/V2/V3
O V1 era apenas texto para vídeo. O V2 adicionou comprimento por meio do forçamento por difusão. O V3 introduziu entradas multimodais, mas ainda gerava vídeo sem áudio nativo. O V4 é o primeiro a tratar o áudio como uma saída de primeira classe gerada simultaneamente com o vídeo.
Quem Deve Prestar Atenção ao SkyReels V4?

Criadores de conteúdo e cineastas
Qualquer pessoa produzindo conteúdo de formato curto para plataformas sociais se beneficia imediatamente. A compressão do fluxo de trabalho — do prompt ao clipe audiovisual finalizado — remove o gargalo que fazia as ferramentas de IA para vídeo parecerem criar mais trabalho do que economizavam.
Observei um amigo cineasta usar o V4 para gerar imagens B-roll para um documentário. Prompts como “time-lapse das luzes da cidade acendendo ao entardecer” ou “close-up de chuva no vidro da janela” com sons ambiente apropriados. As saídas não eram indistinguíveis de imagens reais, mas eram boas o suficiente para planos de fundo, e ficavam prontas em menos de 60 segundos cada, em vez de exigirem locações ou licenciamento de imagens de arquivo.
Desenvolvedores construindo pipelines de vídeo
Se você está construindo aplicações que geram ou manipulam vídeo, a interface unificada do V4 para geração, inpainting e edição simplifica a pilha. Em vez de encadear modelos separados para geração de vídeo, síntese de áudio e correção de sincronização, uma única chamada de API lida com todo o fluxo.
A arquitetura do modelo está documentada em detalhes, e a SkyworkAI tem histórico de disponibilizar versões anteriores como código aberto, o que sugere que o acesso para desenvolvedores se expandirá. Os pesos do V3 já estão disponíveis no Hugging Face e no GitHub.
Status de Acesso Atual e o que Está por Vir
Em 2 de março de 2026, o V4 está em pré-visualização limitada. O site oficial oferece um nível gratuito com limites diários de geração, mas ainda sem acesso à API. Com base na linha do tempo do V3 — que passou da publicação do artigo à API pública em cerca de duas semanas — eu esperaria disponibilidade mais ampla até meados de março.
O artigo técnico observa que trabalhos futuros incluem a extensão além de 15 segundos e a melhoria do controle de áudio refinado. Essas limitações parecem significativas agora, especialmente o limite de duração. Mas para o problema específico que o V4 resolve — gerar clipes audiovisuais curtos e sincronizados sem pós-produção — ele funciona melhor do que qualquer outra coisa que testei.
Mantive o V4 no meu fluxo de trabalho desde aquele primeiro teste. Não para tudo — ainda há tarefas em que imagens filmadas ou vídeos de arquivo fazem mais sentido. Mas para B-roll rápido, cenas ambientes ou trechos de mídia social onde o áudio sincronizado importa, o V4 removeu fricção suficiente para que eu o use primeiro agora.
A arquitetura unificada parece menos um recurso incremental e mais a correção de algo que deveria ter funcionado assim desde o início.
Artigos relacionados
Apresentando o ByteDance Seedance 2.0 Mini no WaveSpeedAI

Claude Fable 5 com Fallback para Opus 4.8 Explicado
API do GLM-5.2: Preços, Contexto de 1M e Roteamento em Produção
Preços do GPT-5.4 Mini: Custo de Entrada, Cache e Saída
API MAI-Image-2.5: O Que os Desenvolvedores Precisam Saber