WAN 2.7: Controle de Primeiro e Último Frame — Guia para Desenvolvedores
Como usar o controle de primeiro e último frame do WAN 2.7 para geração de vídeo previsível — preparação de entrada, parâmetros de API e dicas de fluxo de trabalho em produção.

Ei, pessoal, a Dora está chegando. Fiquei vendo equipes descreverem o controle de primeiro/último quadro como “você só faz upload de duas imagens.” Isso é como descrever filas de trabalho assíncrono como “você só espera.” A mecânica não é difícil — mas as decisões de design de entrada são onde a maioria dos fluxos de trabalho em produção falha silenciosamente.
Este guia é para quem precisa de resultados repetíveis, não apenas de uma demo que funcionou uma vez.
O Que o Controle de Primeiro e Último Quadro Realmente Faz
O Problema Que Ele Resolve vs. I2V Padrão
O image-to-video (I2V) padrão ancora o quadro inicial e então o modelo improvisa. O resultado é o que a comunidade frequentemente chama de “deriva” — o sujeito, a posição da câmera ou a iluminação divergem gradualmente de qualquer estado-alvo que você tinha em mente. Para demonstrações de produtos ou sequências narrativas com um ponto de chegada obrigatório, isso é caro para corrigir em pós-produção.
A abordagem FLF2V do WAN usa um mecanismo adicional de ajuste de controle: os quadros inicial e final são tratados como condições de controle, e recursos semânticos de ambas as imagens são injetados no processo de geração. Isso mantém estilo, conteúdo e estrutura consistentes enquanto o modelo transforma dinamicamente entre eles.
Como Ambos os Quadros São Usados Durante a Geração
O modelo não simplesmente interpola valores de pixel. Ele usa recursos semânticos CLIP e mecanismos de cross-attention para manter o vídeo estável — esse design demonstrou reduzir o jitter do vídeo em comparação com abordagens de âncora única. Seu primeiro quadro define o estado inicial; seu último quadro restringe o destino. O caminho de movimento entre eles é inferido, não especificado, o que é tanto o poder quanto o principal modo de falha.
O Que o Modelo Infere Sobre o Caminho Entre Eles
Seu prompt de texto orienta como a transição acontece — não apenas que ela acontece. Se o seu prompt diz “o produto gira lentamente e revela sua face frontal,” essa descrição de movimento molda o caminho inferido. Sem um prompt, o modelo ainda tentará uma transição plausível, mas você terá muito menos controle sobre mudanças de direção, movimento de câmera ou ritmo.
Preparação de Entrada
Requisitos de Especificação de Imagem
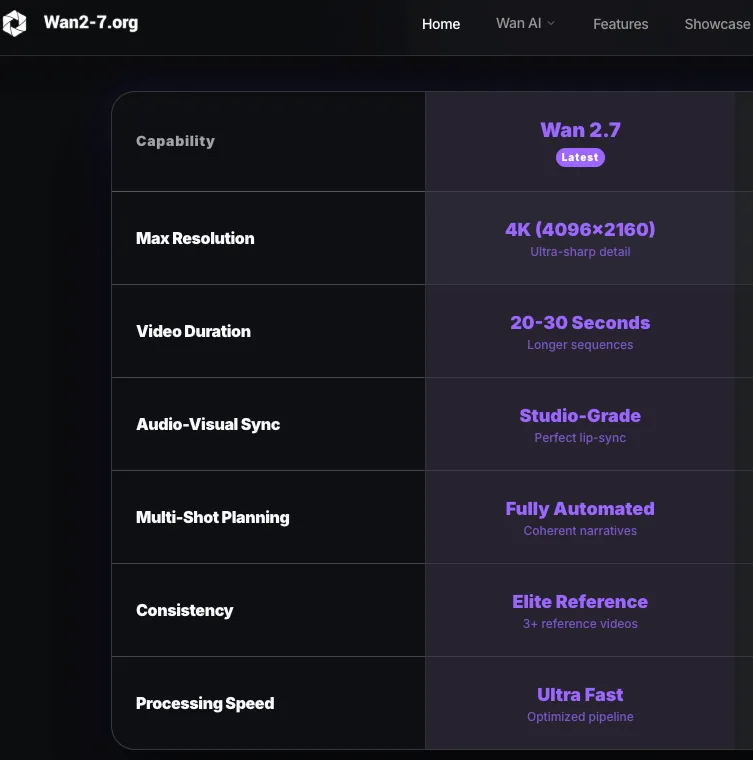
O modelo usa a proporção do seu primeiro quadro o mais próximo possível da saída alvo. Para uma entrada 3:4 (750×1000), uma configuração de saída 720P produzirá algo em torno de 816×1104 — não exatamente 3:4. Se você precisar de proporções exatas, planeje cortar ou adicionar letterbox em pós-produção. Para a série WAN em geral, 720p (1280×720 ou equivalente retrato) é a resolução recomendada para saída de qualidade; usar resoluções menores é uma estratégia válida para iterações de teste, mas não para versões finais.
Formato: PNG ou JPEG de alta qualidade. Evite miniaturas comprimidas como quadros inicial/final — artefatos de compressão introduzem ruído que o modelo precisa interpretar como informação visual intencional.
Estratégias de Pareamento de Quadros Que Funcionam
Os pares mais fortes compartilham três coisas: direção de fonte de luz consistente, características de profundidade de campo correspondentes e um sujeito que seja espacialmente plausível em ambas as posições. Uma foto de produto em luz de estúdio difusa pareada com um quadro final mostrando o mesmo produto em um ângulo ligeiramente diferente funciona bem. Uma foto de embalagem para uma foto hero de estilo de vida funciona se a configuração de iluminação for semelhante.
Para sequências narrativas, pense no par como definindo um verbo: aberto → fechado, antes → depois, montando → completo. Quanto mais clara a relação semântica, mais coerente será o caminho inferido.
O Que Torna um Par de Quadros Ruim
Três culpados comuns:
Direção de iluminação inconsistente. Se o seu primeiro quadro tem a luz principal a 45° à esquerda e seu último quadro foi filmado com luz vinda de cima, o modelo tentará fazer a transição entre dois ambientes de sombra diferentes. O resultado é geralmente um salto de fonte de luz no meio do clipe que parece um erro de renderização.
Incompatibilidade espacial. Um plano geral amplo pareado com um close-up fechado força o modelo a inventar um movimento de câmera. Às vezes isso é intencional; geralmente não é. Mantenha a distância focal aproximadamente consistente, a menos que você esteja explicitamente solicitando um zoom ou afastamento.
Pistas de profundidade conflitantes. Bokeh no primeiro quadro, tudo em foco no último — o modelo interpretará isso como uma mudança de profundidade de campo e tentará animá-la. Isso nem sempre está errado, mas raramente é o que você pretendia.
Implementação de API
O seguinte reflete o padrão FLF2V documentado para a série WAN. Verifique os nomes de parâmetros atuais e os caminhos de endpoint na documentação do Alibaba Cloud Model Studio antes do uso em produção. As especificações da API do WAN 2.7 devem ser confirmadas no lançamento.
Estrutura do Payload
O padrão principal envolve duas entradas de imagem — uma via URL pública ou caminho de arquivo local — passadas como first_frame_url e last_frame_url, junto com um prompt de texto e configuração de resolução.
Padrão de Requisição Python (Pseudocódigo)
# Verifique o nome do modelo e o endpoint no lançamento — os nomes mudam entre versões
import os
from dashscope import VideoSynthesis
response = VideoSynthesis.async_call(
model="wan2.x-flf2v-<verify-at-launch>", # confirme a string exata do modelo
first_frame_url="https://your-cdn.com/start.png",
last_frame_url="https://your-cdn.com/end.png",
prompt="Câmera fixa. Comece na primeira imagem, termine na última. [descreva o movimento]",
negative_prompt="flicker, warping, blur",
resolution="720P", # verifique os valores aceitos
# parâmetro seed: bloqueie este quando tiver uma boa execução
)
task_id = response.output.task_idTratamento Assíncrono para Jobs Mais Longos
Tarefas de geração de image-to-video geralmente levam de 1 a 5 minutos. A API usa um padrão assíncrono de duas etapas: envie a tarefa, obtenha um ID de tarefa e então faça polling para o resultado. Incorpore o polling ao seu pipeline desde o início. Não assuma comportamento síncrono nem mesmo para chamadas de teste — timeouts descartarão resultados silenciosamente em implementações ingênuas.
Fluxo de Trabalho em Produção: Método Rascunho para Final
Etapa 1 — Construa um Par de Referência e Execute um Teste
Comece com um único par. Não faça processamento em lote até ter visto uma saída do começo ao fim. Use seu conteúdo alvo — não imagens de banco de imagens substitutas — porque as características espaciais e de iluminação precisam representar sua biblioteca de ativos real.
Etapa 2 — Valide o Caminho de Movimento Antes do Lote
Assista ao clipe completo uma vez em velocidade 0,5x. Observe: jitter no meio do clipe, deriva de identidade do sujeito em torno de 50–70% do clipe (é onde a maioria dos artefatos se concentra) e descontinuidade de iluminação. Se você observar qualquer um desses problemas, corrija o par de entrada antes de alterar o prompt.
Etapa 3 — Bloqueie Seu Melhor Seed para Consistência
Quando você tiver uma saída limpa, registre o valor do seed. O modelo FLF2V aceita um prompt opcional para orientar a lógica de ação e transformação intermediária. Um seed bloqueado mais um prompt bloqueado fornece uma unidade de geração reproduzível que você pode aplicar em pares de entrada semelhantes. É isso que torna a produção em lote previsível em vez de probabilística.
Etapa 4 — Escale para Geração em Lote
Estruture seu lote assim: um “par de teste” canônico que serve como âncora de qualidade, depois pares variantes gerados a partir da mesma configuração de filmagem controlada. A página do modelo no Hugging Face para WAN FLF2V documenta a versão de pesos abertos para equipes que executam inferência local junto com chamadas de API.
Onde Este Recurso Se Encaixa (e Onde Não Se Encaixa)
Ideal para: sequências de demonstração de produtos onde o ponto de chegada importa (foto de embalagem → revelação de recurso), tomadas de continuidade narrativa com um antes/depois definido, caminhos de câmera controlados onde você precisa de estabilidade espacial em múltiplos clipes de uma série.
Não ideal para: movimento altamente dinâmico com mudanças bruscas de direção (o modelo as suavizará, frequentemente perdendo o drama), transições espaciais ambíguas onde os quadros inicial e final não compartilham uma relação semântica clara, ou cenários que exigem sincronização precisa de quadros — o modelo controla o ritmo, não você.
Padrões de Falha Comuns e Correções
Artefato de movimento no meio do clipe. Geralmente causado por incompatibilidade espacial no par de entrada. O modelo “se compromete” com um caminho de interpolação cedo, e a inconsistência aparece por volta do ponto médio. Correção: estreite a relação entre os quadros antes de alterar o prompt.
Inconsistência de estilo de quadro. Se o seu primeiro quadro é uma renderização estilizada e o seu último é uma fotografia, o modelo tentará misturar os estilos visuais. Isso raramente produz saída limpa. Combine o tratamento das imagens — ambas renderizações, ambas fotos, ambas ilustrações.
Modelo ignorando o último quadro. Isso acontece quando o prompt descreve um movimento que não pode terminar logicamente no seu último quadro. O modelo prioriza a coerência do prompt em detrimento da aderência ao quadro quando há conflito. Escreva seu prompt para chegar ao último quadro, não apenas para partir do primeiro.
Perguntas Frequentes
- Posso usar primeiro/último quadro com text-to-video ou apenas com I2V? O modo FLF2V é uma extensão do I2V. Ambas as entradas de quadro são obrigatórias. O T2V padrão não aceita restrições de quadro final por design.
- Qual formato de imagem funciona melhor para entradas de quadro? PNG para qualquer coisa que requeira bordas limpas ou manipulação de transparência. JPEG de alta qualidade (>90 de qualidade) está bom para fotografia. Evite WebP se sua plataforma não tiver confirmado suporte.
- Isso custa mais do que o I2V padrão? O preço depende da resolução — 720p custa aproximadamente o dobro de 480p por geração. O próprio FLF2V não tem um adicional separado nos preços documentados, mas confirme com sua plataforma específica.
- Como lidar com movimentos que exigem mudanças bruscas de direção? Divida a sequência em múltiplos clipes com quadros intermediários como pontos de chegada. Encadeie-os em pós-produção em vez de tentar que uma única geração lide com movimento descontínuo.
- Posso combinar isso com o modo de entrada em grade 9? Esses são modos de entrada separados. O WAN 2.7 suporta controle de primeiro/último quadro e image-to-video em grade 9 como recursos distintos. Eles não são atualmente combinados em uma única chamada — verifique no lançamento se isso mudar.
Conclusão
O espaço de design interessante com o controle de primeiro/último quadro não é a chamada de API — é o par de entrada. É aí que está a real alavancagem de produção, e é onde a maioria das equipes subinveste. Um par de quadros bem projetado com uma relação semântica clara superará consistentemente um prompt perfeito pareado com uma entrada incompatível.
Para equipes que constroem pipelines em lote: trate sua biblioteca de pares de entrada como um ativo de primeira classe, não como um detalhe secundário. Uma vez que você tenha um seed bloqueado e um formato de par validado, o lado da geração se torna rotineiro. A comunidade ComfyUI documentou configurações de fluxo de trabalho WAN FLF2V em detalhes, caso você também esteja executando inferência local junto com chamadas de API — vale a leitura pelo insight no nível de nó sobre como o condicionamento de quadro realmente funciona.
Fico voltando a algo silencioso aqui: a restrição é o recurso. Dar ao modelo um destino força você a ser preciso sobre o que realmente quer. Isso não é uma limitação — é uma disciplina que tende a produzir melhor resultado do que a geração de final aberto jamais produz.
Continue explorando fluxos de trabalho de vídeo com IA:
- Veja como o controle de primeiro/último quadro se compara a outros modelos de geração de vídeo
- Entenda como manter a consistência de personagens em clipes de vídeo gerados
- Explore casos de uso reais para geração de vídeo com IA em fluxos de trabalho de produção
- Aprenda como entradas de referência de múltiplas imagens melhoram o controle de geração
- Veja como os pipelines de image-to-video são usados em diferentes ferramentas
Artigos relacionados
Apresentando o ByteDance Seedance 2.0 Mini no WaveSpeedAI

Claude Fable 5 com Fallback para Opus 4.8 Explicado
API do GLM-5.2: Preços, Contexto de 1M e Roteamento em Produção
Preços do GPT-5.4 Mini: Custo de Entrada, Cache e Saída
API MAI-Image-2.5: O Que os Desenvolvedores Precisam Saber