Muse Spark vs Llama 4: A Mudança Estratégica da Meta
A Meta migrou do Llama de pesos abertos para o Muse Spark fechado. O que mudou, por que isso importa para desenvolvedores e se versões futuras de código aberto são realistas.

A Meta acaba de lançar uma nova série de modelos. Se você construiu algo com Llama 4 no último ano, provavelmente está se perguntando se deve continuar ou começar a planejar uma migração.
Sou Dora. Passei o dia de ontem lendo toda a documentação que a Meta publicou, cruzando referências com benchmarks de terceiros e tentando entender o que isso realmente significa para quem tem Llama em sua stack. Este texto detalha o que mudou, o que não mudou e onde os desenvolvedores estão agora.
O Que Mudou Entre o Llama 4 e o Muse Spark
Arquitetura: Nove Meses, do Zero
Meta Superintelligence Labs — a unidade formada após Alexandr Wang entrar como diretor de IA em meados de 2025 — reconstruiu toda a stack de IA do zero. Nova infraestrutura, nova arquitetura, novos pipelines de dados. Isso não é texto de marketing; é o que o próprio blog técnico da Meta afirma. O Muse Spark é o primeiro modelo dessa reconstrução.
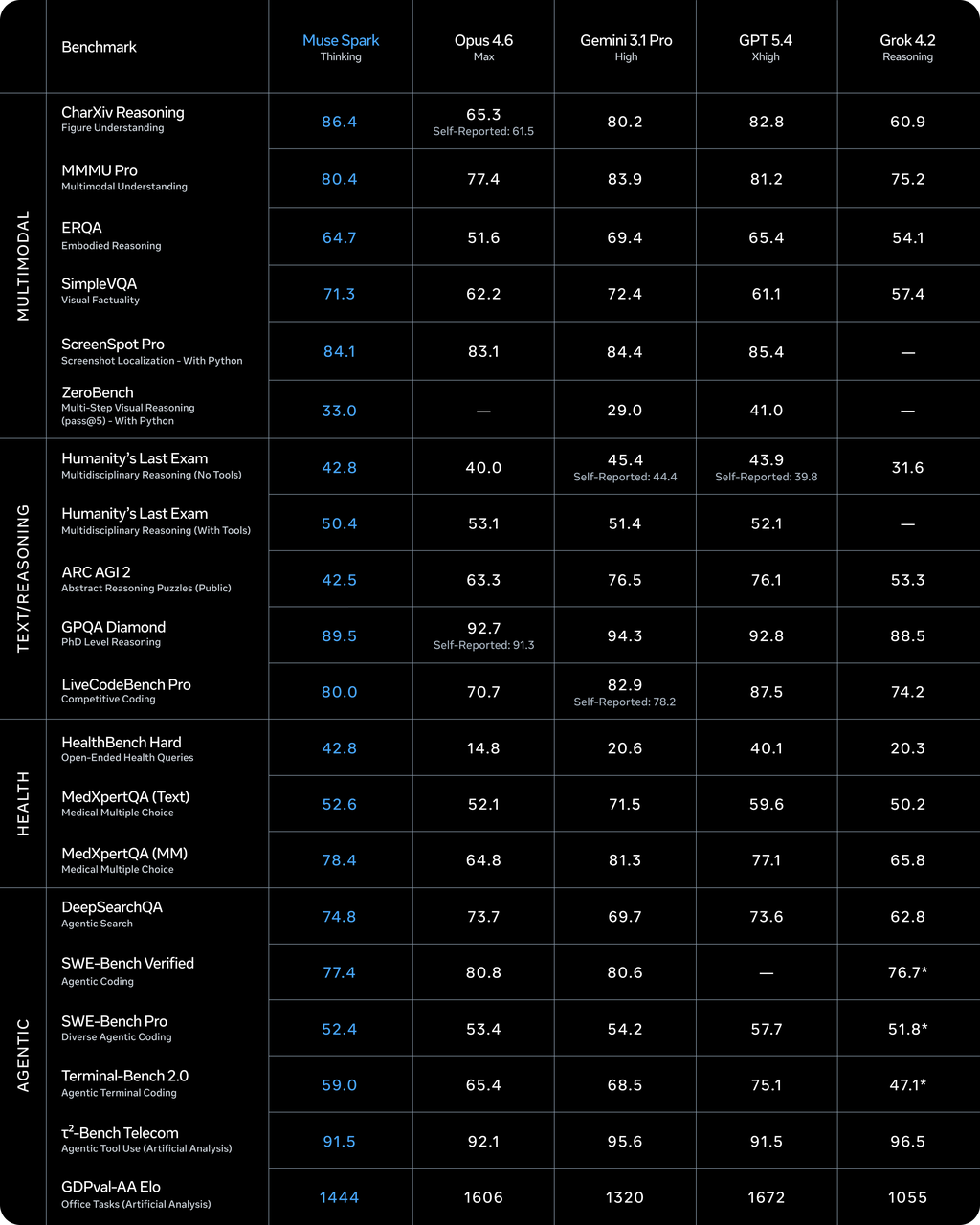
O Llama 4 usava uma arquitetura Mixture-of-Experts com pesos abertos. O Muse Spark é um modelo de raciocínio nativamente multimodal — ou seja, a visão não foi adicionada depois, foi integrada desde o início. Ele suporta uso de ferramentas, cadeia visual de pensamento e orquestração multi-agente. O Llama 4 não tinha nenhuma dessas como capacidades nativas.
O modelo também introduz modos de raciocínio em camadas: Instant para consultas casuais, Thinking para trabalho passo a passo, e um modo Contemplating que executa múltiplos sub-agentes em paralelo. Este último é a resposta da Meta ao Gemini Deep Think e ao raciocínio estendido do GPT Pro.
Eficiência: Afirmação da Meta, Não Conclusão Independente
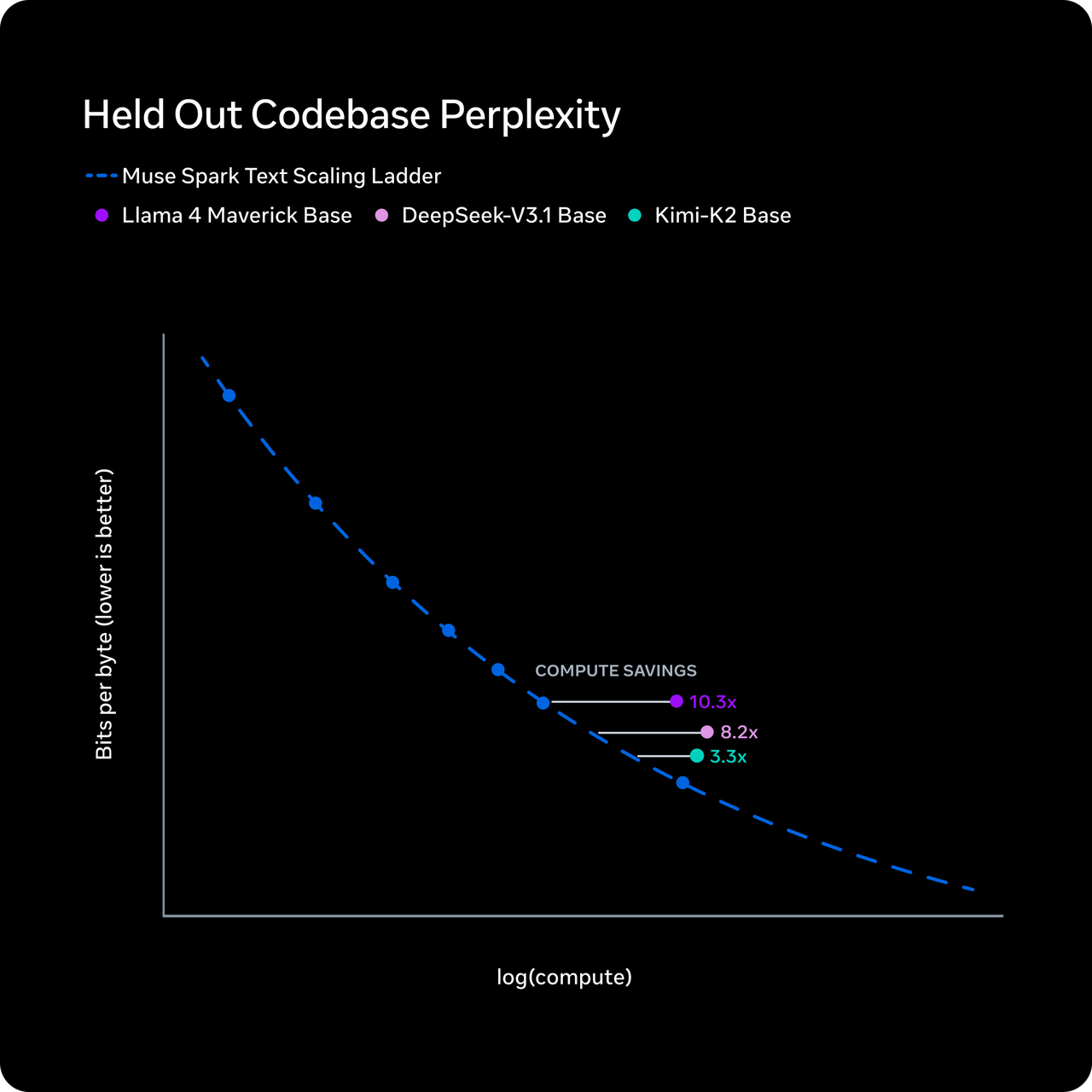
A Meta afirma que o Muse Spark atinge o nível de capacidade do Llama 4 Maverick usando mais de dez vezes menos computação. O mecanismo que eles descrevem é a “compressão de pensamento” — durante o aprendizado por reforço, o modelo é penalizado por tempo de raciocínio excessivo, forçando-o a raciocinar com menos tokens sem perder precisão.
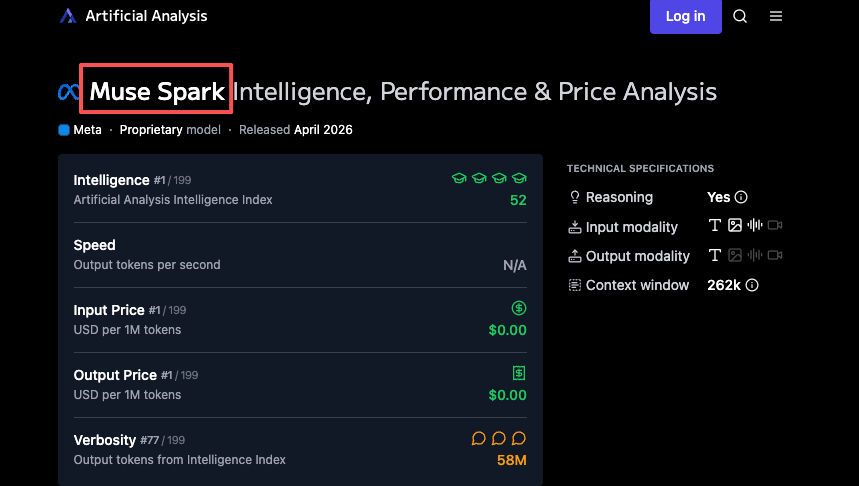
Quero ser precisa aqui: esta é a afirmação da Meta. Ela não foi replicada de forma independente. Os números de eficiência de tokens da Artificial Analysis mostram que o Muse Spark usou 58 milhões de tokens de saída para executar todo o seu Intelligence Index — comparável aos 57 milhões do Gemini 3.1 Pro e muito abaixo dos 157 milhões do Claude Opus 4.6 ou dos 120 milhões do GPT-5.4. Portanto, a história de eficiência tem algum suporte independente, pelo menos no lado da saída.
Lacuna nos Benchmarks: 18 para 52
De acordo com a Artificial Analysis, o Llama 4 Maverick pontuou 18 no Intelligence Index no lançamento. O Muse Spark pontuou 52. Isso o coloca em quarto lugar no geral — atrás do Gemini 3.1 Pro Preview e GPT-5.4 (ambos em 57) e do Claude Opus 4.6 (53).
Uma ressalva importante: a Artificial Analysis recebeu acesso antecipado da Meta para fazer benchmark do modelo. Eles realizaram suas próprias avaliações de forma independente, mas o acesso em si veio através da Meta. Esses ainda não são benchmarks públicos completamente independentes. As pontuações são uteis como direção, não como verdade absoluta.
Onde o Muse Spark lidera: benchmarks de saúde (42,8 no HealthBench Hard, à frente dos 40,1 do GPT-5.4), raciocínio visual (80,5% no MMMU-Pro, segundo apenas ao Gemini 3.1 Pro) e compreensão de gráficos.
Onde ele fica atrás: codificação (Terminal-Bench Hard, atrás do Claude Sonnet 4.6 e GPT-5.4), tarefas agênticas (GDPval-AA 1.427 ELO vs. 1.676 do GPT-5.4) e raciocínio abstrato (ARC-AGI-2 em 42,5 vs. 76+ para os principais concorrentes). A Meta reconheceu explicitamente essas lacunas em seu blog técnico, afirmando que continua investindo em “sistemas agênticos de longo horizonte e fluxos de trabalho de codificação.”
A Mudança de Aberto para Fechado
O Modelo Llama: Pesos Abertos, Ecossistema Comunitário
A proposta de valor do Llama era simples. Baixe os pesos, execute-os em seu próprio hardware, ajuste para seu caso de uso, pague apenas pela computação. A abordagem de peso aberto construiu um ecossistema — milhares de variantes ajustadas no Hugging Face, implantações auto-hospedadas em startups e empresas, toda uma indústria artesanal de modelos quantizados rodando em GPUs de consumo. O Llama 4 Scout cabe em um único H100. O Maverick roda em um RTX 5090 com quantização.
Esse ecossistema ainda existe. Esses modelos não foram removidos.
O Modelo Muse Spark: Fechado, Apenas API em Prévia Privada
O Muse Spark é proprietário. Sem pesos para download. Sem auto-hospedagem. Por enquanto, ele alimenta o Meta AI nos aplicativos da empresa — o site do Meta AI e, em breve, WhatsApp, Instagram, Facebook, Messenger e óculos AI Ray-Ban. Desenvolvedores externos podem solicitar uma prévia de API privada. Só isso.
Isso é mais fechado do que os modelos da OpenAI ou Anthropic, que pelo menos oferecem acesso público à API. Como a Fortune observou em sua cobertura, o Muse Spark é “ainda mais proprietário do que os modelos proprietários pagos oferecidos pelos rivais da Meta.”

“Esperamos Abrir o Código-Fonte de Versões Futuras”
O post do blog da Meta inclui essa frase. Zuckerberg escreveu no Threads sobre planos de lançar “modelos cada vez mais avançados que empurram a fronteira da inteligência e capacidades, incluindo novos modelos de código aberto.” Wang mencionou a abertura do código-fonte de versões futuras no X.
Sem prazo. Sem compromisso específico sobre qual modelo ou quando. Sem indicação se “versões futuras” significa que o próprio Muse Spark eventualmente será aberto, ou se um ramo separado de peso aberto continua em paralelo.
Compare isso com o manifesto de Zuckerberg de 2024, intitulado “Open Source AI is the Path Forward” (IA de Código Aberto é o Caminho a Seguir), onde ele argumentou que abrir o Llama não prejudica a receita da Meta. Isso foi dezoito meses atrás. O cálculo estratégico claramente mudou. Como a análise do The Next Web colocou, o fechamento é um sinal de que a Meta agora se considera em uma corrida onde ceder inovações arquitetônicas custa mais do que ganha.
Aqui é onde meus dados terminam. Se futuros modelos Muse serão realmente abertos é especulação. Atualizarei quando houver algo concreto.
O Que Isso Significa para Desenvolvedores Usando Llama Atualmente
Llama Auto-Hospedado: Ainda Viável, Não Depreciado
Quando o VentureBeat perguntou diretamente à Meta se o desenvolvimento do Llama havia terminado, um porta-voz disse: “Nossos modelos Llama atuais continuarão disponíveis como código aberto.” Essa frase é cuidadosamente formulada. Confirma que os modelos existentes permanecem disponíveis. Não diz nada sobre o desenvolvimento futuro do Llama.
Se você está executando o Llama 4 Scout ou Maverick em produção hoje, nada mudou operacionalmente. Os pesos ainda estão no Hugging Face. Os ajustes da comunidade ainda funcionam. Sua infraestrutura não precisa se mover.
Trade-offs Operacionais: Hoje vs. Esperar
Aqui está a situação prática. Se você tem uma implantação Llama funcionando — pipeline de inferência ajustado, custos previsíveis, equipe familiarizada com os parâmetros — você tem uma quantidade conhecida. Os preços da API do Muse Spark não foram anunciados. O acesso público à API não foi anunciado. A prévia privada é apenas por convite.
Mudar de um modelo de peso aberto auto-hospedado para uma API fechada significa abrir mão do controle sobre latência, tempo de atividade, estrutura de custos e tratamento de dados. Para algumas equipes esse trade-off faz sentido. Para outras, não. O ponto é que você não pode sequer avaliar o trade-off ainda porque os termos de API do Muse Spark não existem publicamente.
Fluxos de Trabalho de Codificação: A Lacuna Reconhecida
Se sua implantação Llama lida com geração de código, revisão de código ou qualquer tarefa voltada para desenvolvedores, não há razão para olhar para o Muse Spark agora. A própria Meta disse isso — codificação é uma fraqueza atual. No Terminal-Bench Hard, o Muse Spark fica atrás tanto do Claude Sonnet 4.6 quanto do GPT-5.4. No GDPval-AA, que mede tarefas de trabalho do mundo real, ele pontua 1.427 ELO contra 1.648 do Claude Sonnet 4.6.
Funciona para minha frequência. A sua pode diferir. Mas os dados são claros sobre isso.
Por Que a Meta Fez Essa Mudança
Llama 4: O Tropeço Reconhecido
O Llama 4 foi lançado em abril de 2025 com recepção mista. A controvérsia sobre benchmarks — a Meta usou uma “versão experimental de chat” especializada e não lançada para impulsionar pontuações no LMArena — prejudicou a credibilidade. Os modelos em si eram sólidos para sua classe de peso, mas não moveram a fronteira. Em meados de 2025, a narrativa era que a Meta havia ficado para trás da OpenAI, Anthropic e Google.
O Mandato de Wang
Em junho de 2025, a Meta gastou $14,3 bilhões para adquirir uma participação não votante de 49% na Scale AI e trouxe o co-fundador Alexandr Wang como diretor de IA. O mandato era explícito: alcançar. O Meta Superintelligence Labs foi formado. Pesquisadores foram recrutados da OpenAI, Anthropic e Google com pacotes salariais que supostamente chegavam a centenas de milhões quando o patrimônio era incluído.
Nove meses depois, o Muse Spark é o primeiro resultado. Se ele justifica o investimento depende do que vem a seguir — este modelo é deliberadamente pequeno e rápido, com versões maiores já em desenvolvimento.
Pressão Competitiva
A matemática é simples. OpenAI e Anthropic são coletivamente avaliadas em mais de $1 trilhão. O Gemini do Google ganhou tração nos mercados de consumo e desenvolvedor. A Meta estava gastando $72 bilhões em infraestrutura de IA em 2025, aumentando para uma previsão guiada de $115–135 bilhões em 2026, e não tinha nenhum modelo competitivo de fronteira para mostrar. Algo precisava mudar.
Framework de Decisão para Desenvolvedores
Fique com o Llama Se:
Você precisa de pesos abertos — para auto-hospedagem, ajuste fino, conformidade local ou controle de custos. Você está executando fluxos de trabalho pesados em codificação onde o Muse Spark tem lacunas reconhecidas. Você precisa de infraestrutura previsível e autogerenciada que não dependa de uma lista de espera de API privada. Você já investiu em ferramentas específicas do Llama (pipelines de quantização, adaptadores LoRA, avaliações personalizadas).
Acompanhe o Muse Spark Se:
Você está construindo dentro do ecossistema de produtos da Meta — qualquer coisa que se integre ao Instagram, WhatsApp, Facebook ou Messenger. Você precisa de forte compreensão multimodal, particularmente raciocínio visual ou tarefas relacionadas à saúde. Você está disposto a esperar pelo acesso público à API e pode avaliar quando os preços e termos estiverem disponíveis.
Nenhum Cobre:
Geração de imagens. Geração de vídeos. Estas são categorias de modelos separadas. O Muse Spark é apenas de saída de texto, e o Llama 4 é apenas de saída de texto. Se você precisa de capacidades de geração, está olhando para ferramentas completamente diferentes.
FAQ

Ainda posso usar o Llama 4 após o lançamento do Muse Spark?
Sim. O Llama 4 Scout e Maverick permanecem disponíveis no Hugging Face e através dos parceiros de API da Meta. Nada foi depreciado ou removido.
A Meta vai lançar os pesos do Muse Spark?
A Meta disse que “espera abrir o código-fonte de versões futuras do modelo.” Não há prazo, nenhum compromisso específico sobre o próprio Muse Spark e nenhuma indicação do que “versões futuras” significa na prática. Trate isso como aspiração, não como plano.
O Muse Spark é melhor que o Llama 4 para codificação?
Não. A Meta reconhece explicitamente a codificação como uma lacuna atual. Em benchmarks específicos de codificação, o Muse Spark fica atrás do Claude Sonnet 4.6 e GPT-5.4. Se codificação é seu caso de uso principal, o Llama 4 Maverick com ajuste fino ou um modelo de codificação específico é uma opção melhor hoje.
Quando vem o próximo modelo Muse?
A Meta descreveu o Muse Spark como “o primeiro passo” com “modelos maiores já em desenvolvimento.” Sem datas. Sem nomes. Sem especificações além de confirmar que existem.
Isso afeta o ecossistema mais amplo de IA de código aberto?
É um sinal, não um golpe fatal. Os modelos Llama de peso aberto da Meta permanecem disponíveis. Outras organizações — Mistral, DeepSeek, Qwen da Alibaba — continuam lançando modelos abertos. Mas a Meta era o maior financiador corporativo único de modelos de fronteira de peso aberto. Se o investimento de fronteira deles mudar permanentemente para modelos fechados, o ecossistema perde seu colaborador mais bem financiado. Isso importa ao longo de anos, não semanas.
É isso. Mais informações quando a API for pública.
Posts anteriores:
Artigos relacionados
Apresentando o ByteDance Seedance 2.0 Mini no WaveSpeedAI

Claude Fable 5 com Fallback para Opus 4.8 Explicado

API do GLM-5.2: Preços, Contexto de 1M e Roteamento em Produção

Preços do GPT-5.4 Mini: Custo de Entrada, Cache e Saída

API MAI-Image-2.5: O Que os Desenvolvedores Precisam Saber
