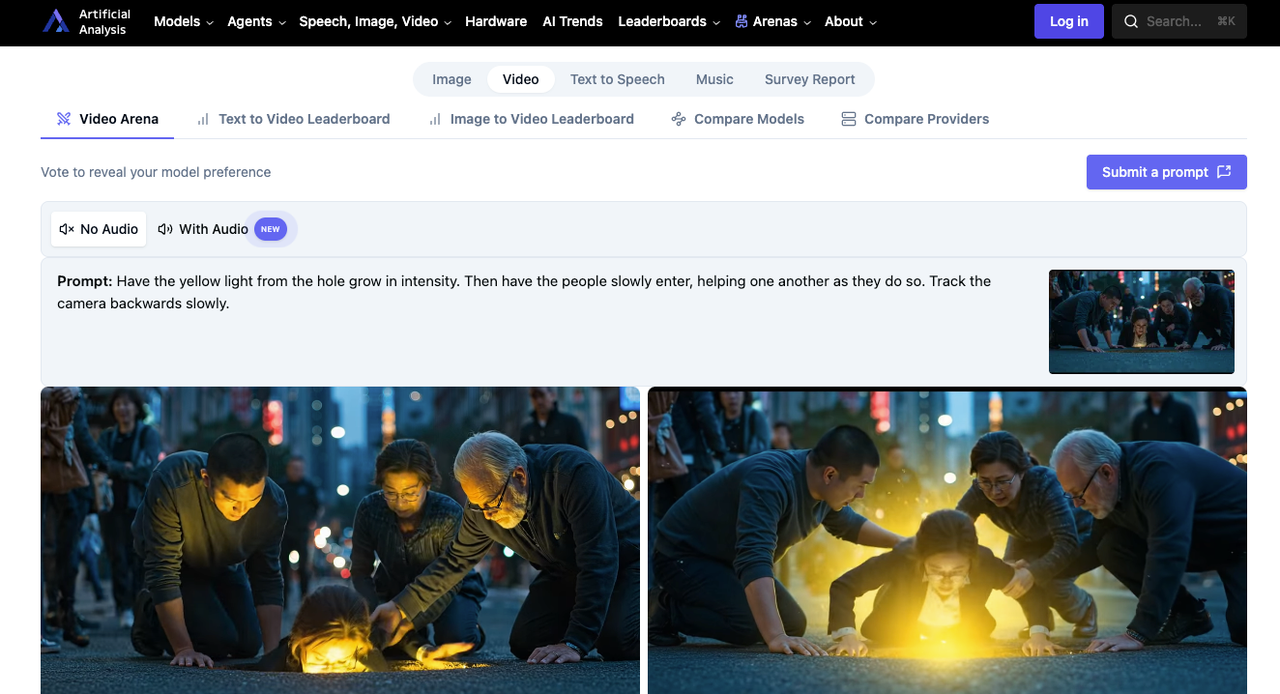
HappyHorse-1.0 vs Seedance 2.0: Qual Vence Agora?
HappyHorse-1.0 supera o Seedance 2.0 em T2V e I2V sem áudio — mas fica atrás no áudio e não tem API estável. Veja o que isso significa para os desenvolvedores.

Passei muito do meu tempo atualizando o placar do Artificial Analysis Video Arena. Oi, aqui é a Dora! Um modelo que eu nunca tinha ouvido falar — HappyHorse-1.0 — havia aparecido discretamente no fim de semana e tirado o Seedance 2.0 do primeiro lugar em dois dos quatro principais rankings. Ninguém parecia saber quem o criou. O próprio Artificial Analysis o chamou de uma entrada “pseudônima”. E minha timeline estava metade empolgação, metade confusão.
Então puxei os números, rastreei os caminhos de acesso e tentei descobrir a única questão que realmente importa para quem está desenvolvendo com esses modelos agora: qual deles você pode colocar em produção hoje?
A resposta não é tão simples quanto o placar parece.
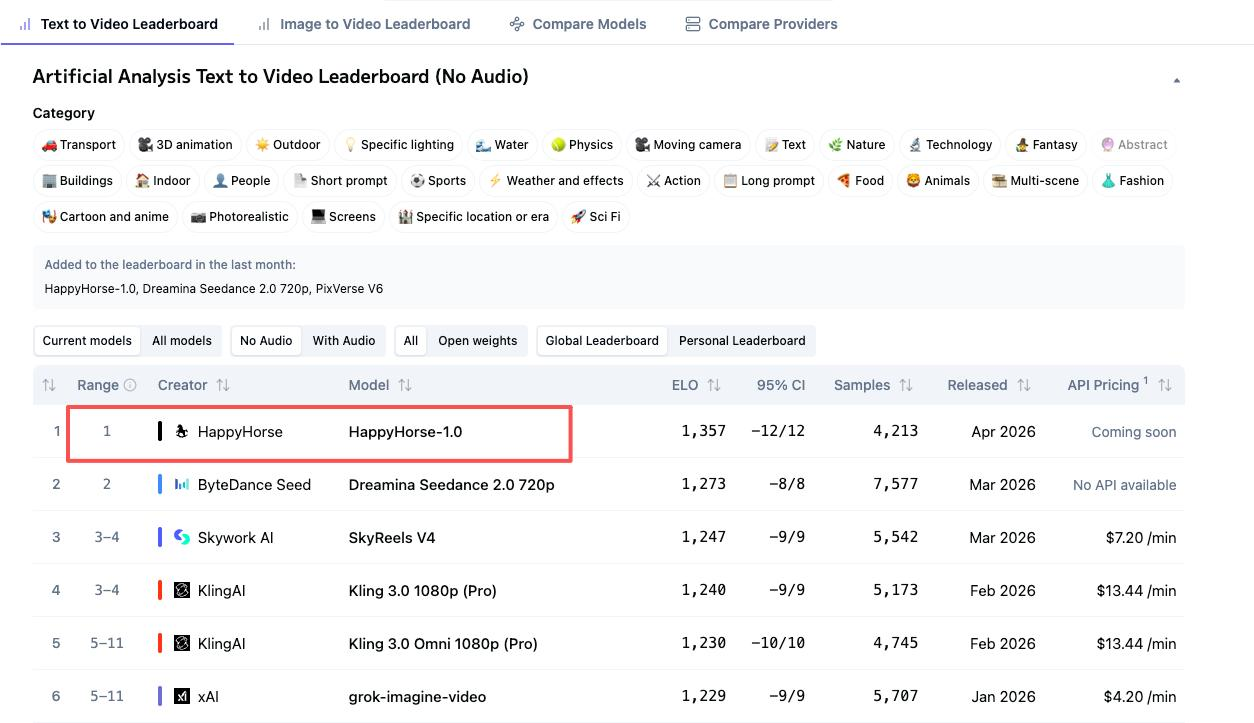
Os Quatro Números do Placar Que Importam
O HappyHorse e o Seedance 2.0 estão no topo de quatro rankings separados do Artificial Analysis. Mas suas posições se invertem dependendo de se o áudio faz parte da avaliação. Essa distinção importa mais do que a maioria das comparações reconhece.
T2V Sem Áudio: HappyHorse #1 (Elo 1333) vs Seedance 2.0 #2 (Elo 1273)
Esta é a melhor apresentação do HappyHorse. Uma diferença de 60 pontos de Elo em uma arena de votação cega é significativa — traduz-se grosso modo em usuários preferindo o output do HappyHorse cerca de 59% das vezes em confrontos diretos. Os votos aqui capturam qualidade de movimento visual, aderência ao prompt e coerência de cena sem nenhum áudio para influenciar a percepção.
T2V Com Áudio: Seedance 2.0 #1 (Elo 1219) vs HappyHorse #2 (Elo 1205)
Assim que o áudio entra em cena, o Seedance assume a liderança por 14 pontos. O Dual-Branch Diffusion Transformer da ByteDance gera vídeo e áudio simultaneamente em uma única passagem — um branch para frames de vídeo, outro para formas de onda de áudio, conectados por cross-attention. Essa escolha arquitetural compensa quando efeitos sonoros e diálogos sincronizados fazem parte do julgamento.
I2V Sem Áudio: HappyHorse #1 (Elo 1392) vs Seedance 2.0 #2 (Elo 1355)
O maior Elo do HappyHorse em todas as quatro categorias. Uma vantagem de 37 pontos em image-to-video sem áudio sugere que o modelo é particularmente forte em seguir a composição da imagem de referência — mantendo a identidade do sujeito, o enquadramento e o estilo visual consistentes ao gerar movimento. Para equipes que fazem animação de produtos ou trabalho de conceito-para-movimento, este é o número que importa.
I2V Com Áudio: Seedance 2.0 #1 (Elo 1162) vs HappyHorse #2 (Elo 1161) — Praticamente Empatados
Um ponto. Isso está dentro de qualquer margem de erro razoável. Nenhum modelo tem vantagem real aqui. Trate esta categoria como empate até que votos significativamente maiores se acumulem.
O Que o Elo Realmente Mede — e Seus Limites para Decisões de Produção
Essas pontuações de Elo vêm de votos cegos de usuários em comparações lado a lado, usando um modelo Bradley-Terry adaptado dos rankings de xadrez. Os usuários veem dois vídeos gerados anonimamente a partir do mesmo prompt e escolhem o que preferem. É o mais próximo que temos de uma “verificação de vibe” em escala.
Mas o Elo não mede confiabilidade de API, velocidade de geração, custo por clipe, estabilidade de acesso, ou se você pode realmente chamar o modelo programaticamente. Uma posição no placar é um sinal de qualidade, não uma decisão de implantação.
Tabela de Comparação Principal
| Dimensão | HappyHorse-1.0 | Seedance 2.0 |
|---|---|---|
| Elo T2V (sem áudio) | 1333 (#1) | 1273 (#2) |
| Elo T2V (com áudio) | 1205 (#2) | 1219 (#1) |
| Elo I2V (sem áudio) | 1392 (#1) | 1355 (#2) |
| Elo I2V (com áudio) | 1161 (#2) | 1162 (#1) |
| Geração de áudio | Presente, inferior ao Seedance | Mais forte — sincronização dual-branch nativa |
| Provedor conhecido | Não — pseudônimo | Sim — ByteDance |
| Arquitetura (declarada) | Transformer de 40 camadas single-stream | Dual-Branch Diffusion Transformer |
| Pesos abertos | ”Em breve” declarado | Não |
| API estável | Nenhuma API pública disponível | Acesso do consumidor via Dreamina; API oficial pausada |
| Acesso hoje | Apenas sites de demonstração | Dreamina, CapCut Pro, apps chineses |
Onde o HappyHorse Se Destaca
Qualidade de movimento visual sem áudio: o que os votos cegos capturam
As diferenças de Elo nos rankings sem áudio — 60 pontos em T2V, 37 em I2V — não são triviais. Usuários em comparações cegas estão consistentemente escolhendo o HappyHorse pelo que as pessoas descrevem como movimento de câmera mais natural, movimento corporal mais suave e atmosfera de cena mais forte. Se o seu caso de uso é loops silenciosos de produtos, clipes sociais editados com música separada, ou B-roll que é mixado em pós-produção, isso é relevante.
Arquitetura Transformer single-stream (declarada) vs pipelines multi-stream
Os materiais de marketing do HappyHorse descrevem um Transformer de auto-atenção unificado de 40 camadas que processa tokens de texto, vídeo e áudio em uma única sequência — sem cross-attention entre branches separados. Se preciso, isso é arquitetonicamente distinto da abordagem dual-branch do Seedance. As primeiras e últimas 4 camadas supostamente usam projeções específicas de modalidade enquanto as 32 camadas intermediárias compartilham parâmetros entre todas as modalidades. Ainda não consigo verificar essas afirmações de forma independente. O GitHub e o hub de modelos estão listados como “em breve”.
Afirmações de áudio multilíngue
O HappyHorse afirma suporte nativo para sete idiomas — inglês, mandarim, cantonês, japonês, coreano, alemão e francês — com sincronização labial de baixa taxa de erro de palavras. O Seedance 2.0 suporta 8+ idiomas para sincronização labial em nível de fonema. No papel, são competitivos. Na prática, não consegui testar o output multilíngue do HappyHorse o suficiente para confirmar paridade.
Onde o Seedance 2.0 Mantém Vantagem
Geração de áudio: ainda lidera em ambos os placares com áudio
O Seedance mantém o #1 em T2V e I2V com áudio. Sua arquitetura dual-branch — um branch gerando frames de vídeo, o outro gerando formas de onda de áudio, conectados via cross-attention para sincronização em nível de milissegundos — foi construída especificamente para isso. Quando seu output precisa de diálogo, som ambiente ou foley preciso por frame, a decisão arquitetural do Seedance de tratar o áudio como cidadão de primeira classe durante a geração (não como uma etapa de pós-processamento) lhe confere uma vantagem estrutural.
Provedor conhecido: ByteDance, identidade estável, ecossistema estabelecido
Você sabe quem fez o Seedance 2.0. A equipe de pesquisa Seed da ByteDance, liderada por Wu Yonghui (ex-Google Fellow, 17 anos no Google incluindo Google Brain), tem uma linhagem documentada do Pixeldance passando pelo Seedance 1.0, 1.5 Pro, e agora 2.0. HappyHorse? Na data de publicação, ninguém confirmou publicamente quem o construiu. O Artificial Analysis o adicionou como uma entrada pseudônima. Vários sites wrapper de terceiros apareceram horas após sua estreia na arena, mas nenhum afirma ser o desenvolvedor original.
Para decisões de produção, a procedência importa. Você precisa saber de quem está dependendo para atualizações de modelo, conformidade e continuidade.
Caminho de acesso: Dreamina tem pontos de entrada públicos
O Seedance 2.0 está acessível hoje através da plataforma Dreamina da ByteDance internacionalmente, com planos pagos a partir de aproximadamente $18/mês. A integração com o CapCut Pro foi lançada em mercados selecionados no final de março de 2026. Usuários chineses podem acessá-lo através do Jimeng com planos a partir de aproximadamente 69 RMB/mês (~$9,60 USD).
Dito isso — a API oficial do Seedance 2.0 permanece pausada desde meados de março de 2026 devido a disputas de direitos autorais relatadas. O acesso do consumidor funciona. O acesso programático via API em escala de produção requer verificação antes de você se comprometer com um pipeline em torno dele. Provedores terceirizados oferecem o Seedance v1.5 via API; a disponibilidade da API do Seedance 2.0 por canais oficiais precisa de confirmação pré-produção.
A Lacuna de Acesso É o Fator Decisivo Real
HappyHorse: sem API estável, sem pesos públicos, apenas demonstração na data de publicação
Apesar das afirmações de lançamento open-source, o GitHub e o hub de modelos do HappyHorse estão ambos listados como “em breve”. Existem múltiplos sites de demonstração e wrapper, mas nenhum oferece endpoints de API documentados com SLAs, limites de taxa ou precificação em torno dos quais você poderia construir um produto. Não encontrei um único provedor de API terceirizado atualmente servindo o HappyHorse-1.0 através de um endpoint estável e documentado.
Se você está avaliando para produção, este é o único fator mais importante. Um modelo que você não pode chamar de forma confiável não é um modelo que você pode colocar em produção.
Seedance 2.0: acessível via Dreamina — detalhes precisam de verificação
O acesso do consumidor através do Dreamina é funcional. A plataforma suporta o conjunto completo de recursos incluindo o sistema de referência @, edição multi-shot e geração audiovisual. Mas se seu fluxo de trabalho requer integração em nível de API, o cenário é menos estável. A API oficial BytePlus para o Seedance 2.0 está pausada desde março. Provedores terceirizados como fal.ai e PiAPI ofereceram o Seedance 1.5; o acesso programático ao Seedance 2.0 e sua estrutura de precificação associada devem ser confirmados diretamente antes de construir uma dependência de produção.
Por Que “#1 no Placar” e “Pronto para Produção” São Perguntas Diferentes
Continuo voltando a isso. O Elo diz qual modelo os usuários preferem em uma comparação controlada. Não diz se você consegue passar 10.000 gerações por ele na próxima terça-feira sem um erro 503. O HappyHorse pode genuinamente produzir vídeo silencioso melhor. Mas se você não pode chamá-lo de forma confiável, essa vantagem de qualidade vive na arena, não no seu pipeline.
Framework de Decisão
Qualidade de áudio é inegociável → Seedance 2.0. Ele lidera em ambos os placares com áudio e sua arquitetura dual-branch gera som sincronizado nativamente. Se seus clipes precisam de diálogo, áudio ambiente ou efeitos sonoros precisos por frame, o Seedance é a escolha mais forte hoje.
Fidelidade de movimento visual é sua prioridade e você está disposto a esperar → Monitore o HappyHorse. As lideranças de Elo sem áudio são reais. Se os pesos abertos e o acesso via API se materializarem conforme prometido, o HappyHorse pode se tornar atraente para fluxos de trabalho voltados a conteúdo silencioso. Mas “em breve” não é um SLA.
Você precisa de uma API de produção hoje → Seedance 2.0 é a aposta mais segura. Não porque seja perfeito — a pausa na API oficial é uma limitação real — mas porque o Dreamina fornece um caminho de acesso funcional com precificação documentada, e provedores terceirizados estão ativamente preparando endpoints do Seedance 2.0. O HappyHorse ainda não tem infraestrutura equivalente.
FAQ
O HappyHorse-1.0 é realmente melhor que o Seedance 2.0?
Depende do que você está medindo. O HappyHorse lidera em qualidade visual em comparações sem áudio (Elo 1333 vs 1273 para T2V, 1392 vs 1355 para I2V). O Seedance lidera quando o áudio faz parte da avaliação. Nenhum domina todas as quatro categorias. “Melhor” só faz sentido em relação ao seu caso de uso específico e se o áudio importa.
Por que o HappyHorse lidera sem áudio mas fica atrás com áudio?
Provavelmente arquitetura. O HappyHorse afirma um Transformer unificado único processando todas as modalidades em uma sequência. O Seedance 2.0 usa um design dual-branch construído especificamente onde branches separados de vídeo e áudio são conectados por cross-attention. Esse branch de áudio especializado parece dar ao Seedance uma vantagem quando qualidade de som e sincronização estão sendo julgadas junto com os visuais.
Posso acessar o HappyHorse-1.0 via API hoje?
Não através de nenhum endpoint estável e documentado que eu consegui verificar em 8 de abril de 2026. Múltiplos sites wrapper oferecem acesso de demonstração via navegador, mas nenhum publica documentação de API, limites de taxa ou SLAs de nível de produção. O GitHub oficial e o hub de modelos estão ambos listados como “em breve.”
Quão confiável é o placar do Artificial Analysis para decisões de produção?
É o sinal crowdsourced mais credível para qualidade de vídeo percebida — votos cegos, ranking baseado em Elo, preferências humanas reais. Mas mede uma coisa: qual output os usuários preferem lado a lado. Não leva em conta velocidade de geração, custo, confiabilidade, tempo de atividade da API ou estabilidade de acesso. Use-o como uma entrada de qualidade, não como uma decisão completa de aquisição.
O HappyHorse-1.0 receberá melhorias de áudio em versões futuras?
Não existe roadmap público. O modelo apareceu na arena há menos de uma semana sob um pseudônimo. Se o lançamento open-source “em breve” acontecer, contribuições da comunidade poderiam melhorar a qualidade do áudio. Mas não há cronograma, nenhuma equipe de desenvolvimento confirmada e nenhum plano de v2 anunciado. Qualquer coisa além do que está atualmente no placar é especulação.
Há algo interessante acontecendo na lacuna entre o que um placar diz e o que um desenvolvedor pode realmente usar. Os números do HappyHorse são genuinamente impressionantes — mas números sem acesso são apenas números. Continuarei monitorando para ver esse repositório do GitHub entrar no ar. Até lá, a comparação não é realmente sobre qual modelo é melhor. É sobre qual modelo está disponível.
Experimente o HappyHorse-1.0 no WaveSpeedAI
O HappyHorse-1.0 já está disponível no WaveSpeedAI:
Posts anteriores:
Artigos relacionados
Apresentando o ByteDance Seedance 2.0 Mini no WaveSpeedAI

Claude Fable 5 com Fallback para Opus 4.8 Explicado

API do GLM-5.2: Preços, Contexto de 1M e Roteamento em Produção

Preços do GPT-5.4 Mini: Custo de Entrada, Cache e Saída

API MAI-Image-2.5: O Que os Desenvolvedores Precisam Saber
