Guia da API GPT Image 2 para Geração e Edição
Um guia prático da API GPT Image 2 para desenvolvedores, abordando geração, edição, design de fluxo de trabalho e considerações comuns de implementação.

Semana passada lancei uma pequena funcionalidade de produto que precisava de geração de imagens por trás de um botão. Dois dias após iniciar o desenvolvimento, percebi que as escolhas de integração que fiz no primeiro dia iriam definir o quanto de dor eu carregaria pelos próximos seis meses. Essa é a parte que ninguém avisa sobre a API do GPT Image 2. O hello-world é fácil. A postura em produção é onde as coisas ficam interessantes.
Sou a Dora. Escrevo notas de trabalho depois de lançar coisas, não antes. Isso é o que aprendi ao conectar o gpt-image-2 da OpenAI a um produto real, e o que eu diria a outro desenvolvedor ou equipe de engenharia de IA para considerar antes de enviar a primeira requisição.
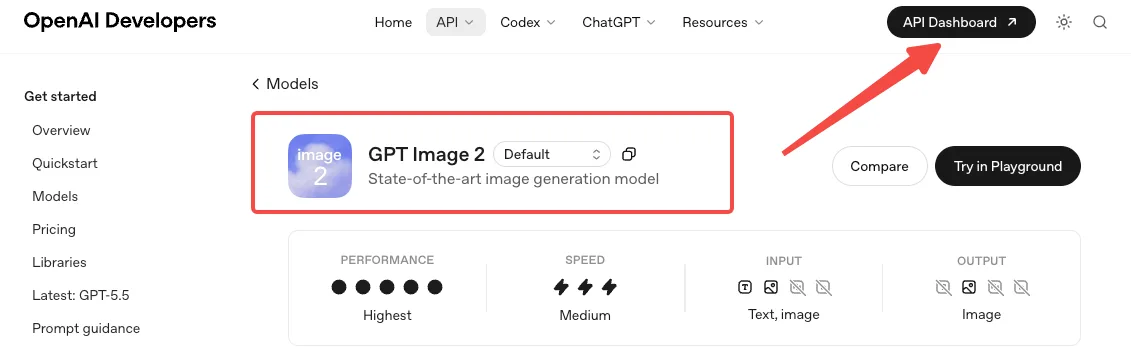
O Que Você Precisa Antes de Usar a API do GPT Image 2
Acesso ao modelo, endpoints e documentação principal
O GPT Image 2 foi lançado em 21 de abril de 2026. O ID do modelo é gpt-image-2. Antes da sua primeira chamada, pode ser necessário completar a Verificação de Organização da API no console do desenvolvedor — a OpenAI restringe a família GPT Image por trás disso.
Você tem três superfícies para escolher. A Image API expõe dois endpoints: images.generate para texto-para-imagem e images.edit para modificar imagens existentes com um prompt e máscara opcional. A terceira superfície é a Responses API, que expõe a geração de imagens como uma ferramenta integrada para fluxos conversacionais ou de múltiplas etapas.
Escolha pela tarefa, não pela novidade. Se seu produto é “usuário digita prompt, recebe imagem,” use a Image API. Se seu produto é “usuário tem uma conversa de ida e volta que às vezes produz imagens,” use a Responses API. Misturá-las porque uma parece mais sofisticada que a outra é uma armadilha de manutenção.
O que o GPT Image 2 suporta hoje
Duas coisas para internalizar cedo.
Ele não suporta fundos transparentes. Requisições com background: "transparent" falharão. Se você precisa de PNGs transparentes, direcione essas tarefas para o gpt-image-1.5 e aceite que agora você está mantendo dois caminhos de modelo.
A fidelidade de entrada é fixada. O parâmetro input_fidelity existe em modelos mais antigos, mas o gpt-image-2 sempre processa entradas com alta fidelidade. Omita o parâmetro ou sua requisição falhará. A implicação de custo: requisições de edição com imagens de referência consomem mais tokens de entrada do que você pode esperar dos seus dias com gpt-image-1.
Como Gerar Imagens com GPT Image 2
Estrutura básica de requisição e opções de saída
Uma requisição de geração recebe um prompt, um tamanho, uma qualidade e um formato de saída. O formato padrão é PNG; você pode solicitar JPEG ou WebP, e JPEG é mais rápido que PNG quando a latência importa. O tamanho aceita predefinições ou dimensões personalizadas, com a restrição de que ambas as bordas devem ser múltiplas de 16, máximo de 3840px por borda, proporção menor que 3:1, e total de pixels entre 655.360 e 8.294.400.
O parâmetro n permite gerar múltiplas imagens em uma requisição. Útil quando você precisa de variações para comparar. Menos útil quando você está pagando por token de saída — o que você está.
Gerenciando tamanho, qualidade e trade-offs de fluxo de trabalho
É aqui que a maioria das equipes gasta dinheiro sem perceber. O GPT Image 2 é cobrado por token, não por imagem: entrada de imagem $8 por 1M de tokens, saída de imagem $30 por 1M de tokens, entrada de texto $5 por 1M de tokens. Entradas em cache são mais baratas. O processamento em lote reduz as taxas padrão pela metade.
O que isso significa em números práticos: em 1024x1024, a calculadora da OpenAI estima aproximadamente $0,006 para baixa qualidade, $0,053 para média, $0,211 para alta. Tamanhos retangulares como 1024x1536 ficam um pouco mais baratos com $0,005, $0,041 e $0,165. Essas são estimativas apenas de saída. Adicione tokens de entrada e tokens de referência de edição por cima.
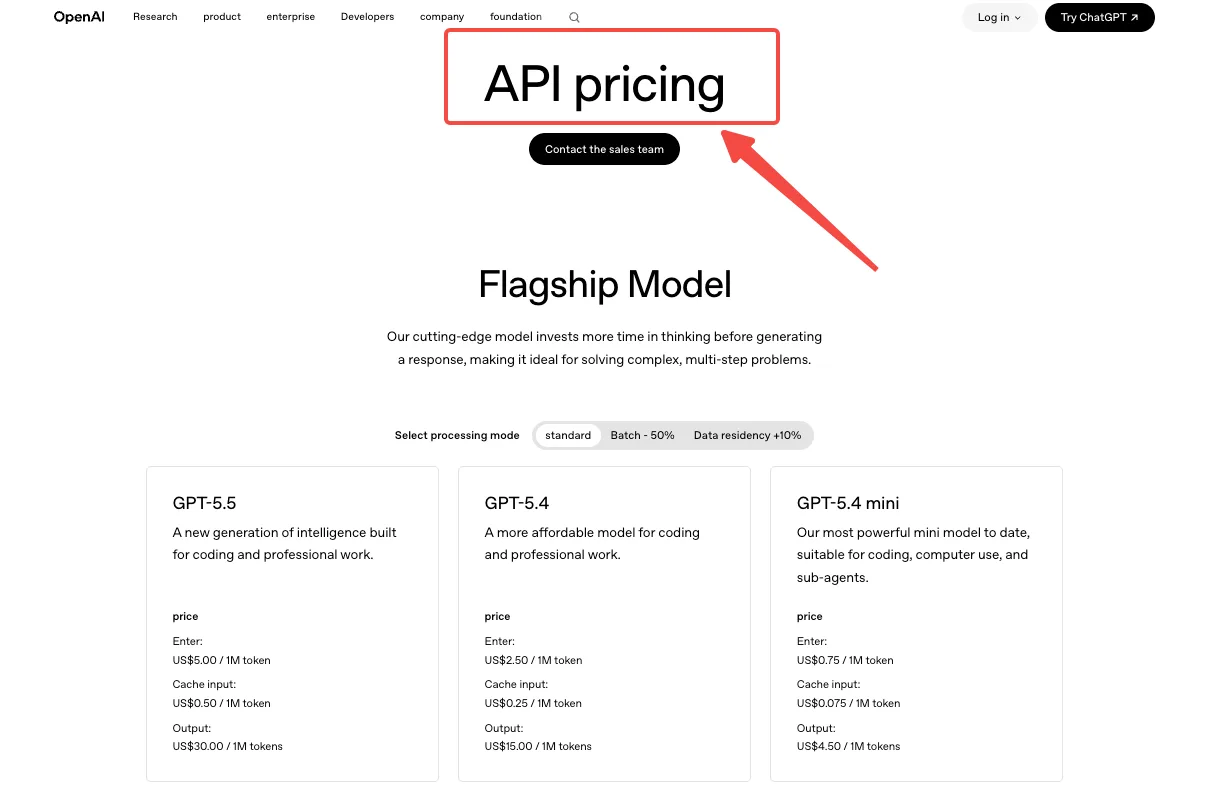
Então a questão do trade-off não é qual qualidade parece melhor. É: no meu volume, qual é a diferença de custo entre média e alta, e meu usuário realmente percebe isso? Para uma superfície de miniatura, baixa qualidade geralmente é suficiente. Para uma imagem principal que os usuários vão observar, alta qualidade justifica seu preço. Escolhi média como padrão e expus alta como uma opção. Essa única decisão mudou minha fatura mensal projetada em cerca de 4x.
Como Funciona a Edição de Imagens
Requisitos de entrada e cenários comuns de edição
O endpoint de edições recebe uma imagem, uma máscara opcional e um prompt descrevendo a alteração. Passe uma imagem para editá-la. Passe múltiplas imagens para combinar sujeitos, estilos ou referências em uma única saída. O modelo lida com inpainting e outpainting, e preserva as regiões sem máscara enquanto aplica seu prompt ao restante.
Edições comuns que validei: troca de fundo em fotos de produtos, remoção de objetos, transferência de estilo entre duas imagens de referência e tradução de texto dentro de uma imagem. A afirmação de consistência de personagem — mesmo personagem em múltiplas cenas geradas — funciona para mim em sujeitos simples. Fica menos confiável à medida que a complexidade da cena aumenta.
Erros que aumentam o custo ou reduzem a consistência
Enviar entradas superdimensionadas. Como o GPT Image 2 processa cada entrada de imagem com alta fidelidade, uma foto de referência em 4K custa os mesmos tokens de entrada independentemente de sua saída ser uma miniatura ou um pôster. Redimensione as referências para o que a tarefa realmente precisa.
Prompts de edição vagos. “Melhore” produz mudanças imprevisíveis e frequentemente custa uma nova tentativa. “Mude o chapéu vermelho para veludo azul claro” preserva o restante da imagem e geralmente acerta de primeira.
n ilimitado. Pedir n=4 para “ver opções” parece inofensivo até você perceber que acabou de pagar 4x por uma requisição onde usará apenas uma saída.
Tratar edições como gerações para estimativa de custo. Edições frequentemente custam mais do que gerações do mesmo tamanho de saída, porque imagens de referência adicionam tokens de entrada. Planeje isso no seu modelo de preços antes do lançamento, não depois.
Considerações de Produção para Equipes
Tentativas, moderação e salvaguardas operacionais
Três coisas que não são opcionais em produção.
Tentativas com backoff exponencial. A geração de imagens pode levar até 2 minutos para prompts complexos, e você vai atingir limites de taxa. A orientação da OpenAI é tentar novamente com backoff exponencial mais jitter — o jitter importa porque tentativas sincronizadas de uma frota atingem o mesmo teto de taxa ao mesmo tempo.
Moderação, em duas camadas. O endpoint de geração de imagens tem um parâmetro moderation integrado (auto é o padrão; low é permissivo, mas ainda filtrado). Para prompts enviados por usuários, execute-os pelo endpoint gratuito omni-moderation-latest antes de enviá-los para o gpt-image-2 — ele aceita texto e imagens, e impede a maioria das requisições que violam políticas antes de você pagar pela geração. A referência da API de moderações tem o formato exato da requisição.
Registrar no grão certo. Registre ID do modelo, tamanho, qualidade, contagem de tokens de prompt, contagem de tokens de saída, latência, ID da requisição e estimativa de custo final por requisição. Quando algo der errado em escala, esses são os dados que permitem diagnosticar. Quando algo der certo, são os dados que permitem decidir se vale escalar mais. Fixe um snapshot específico do modelo em produção em vez do alias flutuante, para que o comportamento não mude sob você. O guia de melhores práticas de produção cobre rotação de chaves, monitoramento e o restante da camada operacional.
Quando manter a integração direta simples vs adicionar uma camada de plataforma
Essa é a questão com a qual fiquei mais tempo.
A integração direta com a OpenAI é a resposta certa quando seu produto usa um modelo de imagem, sua equipe tem experiência em operações de API, e seu tráfego é previsível o suficiente para que a propriedade de limites de taxa e o faturamento de primeira parte importem mais do que a conveniência.
Uma camada de plataforma — e sim, eu trabalho em uma na WaveSpeedAI — ganha seu lugar em situações diferentes. Você está roteando entre múltiplos modelos de imagem (gpt-image-2 para tipografia, um modelo diferente para PNGs transparentes, outro para vídeo). Você precisa de preços planos por chamada para previsibilidade orçamentária em vez de cálculos de tokens. Você quer uma única superfície de integração que sobreviva a mudanças de provedor sem reescrever seus pontos de chamada.
Nenhuma resposta é universal. O teste honesto: conte quantos provedores de modelos seu produto chama hoje, multiplique por quantos você chamará em doze meses, e pergunte-se se deseja manter todas essas integrações por conta própria.
Perguntas Frequentes
Qual endpoint os desenvolvedores devem usar para o GPT Image 2?
Use images.generate para texto-para-imagem, images.edit para modificar uma imagem existente com um prompt e máscara opcional, e a ferramenta de imagem da Responses API quando a geração precisa existir dentro de uma conversa de múltiplos turnos.
O GPT Image 2 suporta edições de imagem?
Sim. O endpoint images.edit aceita uma ou mais imagens de referência mais um prompt, e suporta inpainting e outpainting com máscara. Todas as entradas de imagem são processadas automaticamente com alta fidelidade.
O que as equipes devem registrar e monitorar em produção?
No mínimo: ID do snapshot do modelo, tamanho, qualidade, contagens de tokens de entrada e saída, latência, ID da requisição, contagem de tentativas, resultado da moderação e custo estimado final por requisição. É isso que permite reconstruir qualquer incidente e prever gastos.
Quando uma integração simples de API deixa de ser suficiente?
Quando você está chamando mais de um provedor de imagens, quando modos de falha precisam de fallback entre provedores, ou quando o financeiro pede preços previsíveis por chamada em vez de variabilidade baseada em tokens. Abaixo desses limites, a integração direta continua sendo a escolha mais limpa.
Como evito que injeção de prompt e saídas inseguras vazem para a produção?
Execute prompts de usuários pelo endpoint de moderação antes da geração, defina o parâmetro moderation da API de imagem como auto, registre cada requisição sinalizada e siga as melhores práticas de segurança da OpenAI — incluindo revisão humana para superfícies de alto risco e red-teaming antes do lançamento.
Conclusão
A API do GPT Image 2 não é difícil de conectar. A primeira requisição leva uma tarde. As decisões que importam — padrões de qualidade, modelagem de custo de edição, camadas de moderação, comportamento de tentativas, se adicionar uma camada de plataforma — são as que silenciosamente se acumulam por meses após o lançamento. Escolha-as deliberadamente. Execute o piloto pequeno primeiro. O restante vem depois.
Artigos relacionados
Apresentando o ByteDance Seedance 2.0 Mini no WaveSpeedAI

Claude Fable 5 com Fallback para Opus 4.8 Explicado
API do GLM-5.2: Preços, Contexto de 1M e Roteamento em Produção
Preços do GPT-5.4 Mini: Custo de Entrada, Cache e Saída
API MAI-Image-2.5: O Que os Desenvolvedores Precisam Saber