Claude Mythos vs Claude Opus 4.6: O Que o Vazamento Revela para Desenvolvedores
Claude Mythos vs Opus 4.6: o que o vazamento sugere sobre a diferença de capacidades e se os desenvolvedores devem esperar ou construir agora.

Enquanto estava no meio de um sprint trabalhando em uma integração com o Claude Code na semana passada, o vazamento do Mythos apareceu no meu feed. Três mensagens no Slack em dez minutos, todas variações da mesma pergunta: “Devemos pausar o desenvolvimento?” Esta é Dora, a entusiasta de IA que tem acompanhado a história de perto desde então — e acho que a resposta é mais matizada do que o hype sugere.
Disponível na WaveSpeedAI — preços transparentes por token, endpoint compatível com OpenAI. Claude Opus 4.6 API → · Claude Opus 4.7 API → · Abrir Playground →
Deixa eu explicar o que o vazamento realmente diz, o que o Opus 4.6 oferece atualmente, e como tomar uma decisão real sobre o timing.
Base: O Que o Claude Opus 4.6 Oferece Atualmente aos Desenvolvedores
Antes de entrar em especulações sobre o Mythos, vamos nos ancorar no que está realmente disponível e documentado hoje.
Desempenho em Codificação e Tarefas Agênticas
O Claude Opus 4.6 alcança 65,4% no Terminal-Bench 2.0 e 72,7% no OSWorld, tornando-o o modelo publicamente disponível mais poderoso da Anthropic para tarefas de codificação e uso de computador. Esse número do Terminal-Bench não é apenas um troféu de benchmark — ele representa capacidade agêntica real: depuração em múltiplas etapas, refatoração em larga escala e encadeamento autônomo de ferramentas em fluxos de trabalho estendidos.
O modelo foi construído para agentes que operam em fluxos de trabalho completos, e não apenas em prompts únicos, tornando-o especialmente eficaz para bases de código grandes, refatorações complexas e depuração em múltiplas etapas que se desenvolve ao longo do tempo. Se você está construindo agentes de codificação ou pipelines agênticos, este é o modelo que realmente fecha issues e entrega código com qualidade de produção.
O que importa operacionalmente: o Opus 4.6 divide tarefas complexas em subtarefas independentes, executa ferramentas e subagentes em paralelo e identifica bloqueios com precisão real. Esse é o comportamento que faz a diferença em automações adjacentes ao CI/CD real, não apenas em ambientes de demonstração.
Disponibilidade de API, Preços e Documentação
Aqui está a parte que importa para o seu cronograma de tomada de decisões. O Claude Opus 4.6 oferece raciocínio de última geração a $5 de entrada / $25 de saída por milhão de tokens — uma redução de 67% em relação à era do Opus 4.1, que custava $15/$75. A documentação completa da API do Claude é pública, versionada e estável. Você pode acessá-la via claude-opus-4-6 hoje.
Um recurso de destaque da geração 4.6 é que a janela de contexto completa de 1 milhão de tokens está incluída no preço padrão, eliminando as taxas adicionais por contexto longo que se aplicavam a modelos anteriores. Para equipes que lidam com a ingestão de grandes bases de código ou fluxos de trabalho de pesquisa longos, isso representa uma redução de custo significativa em comparação com gerações anteriores.
Alavancas de otimização de custos que estão totalmente documentadas e disponíveis agora mesmo:
O Que o Vazamento do Claude Mythos Diz Sobre a Diferença
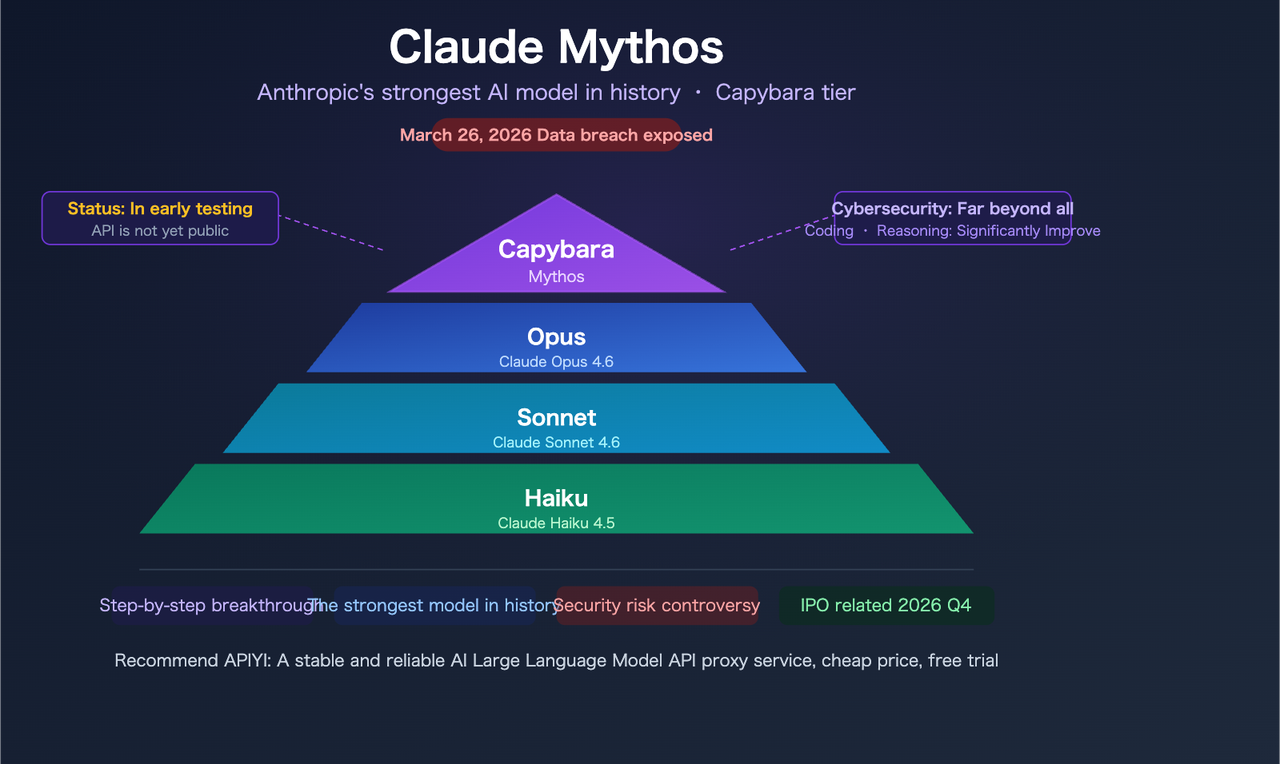
No início deste mês, a Fortune reportou que a Anthropic havia exposto acidentalmente quase 3.000 arquivos internos em um armazenamento de dados mal configurado e pesquisável publicamente. Entre eles: um rascunho de post de blog sobre um modelo chamado Claude Mythos — internamente também com o codinome “Capybara.”
Contexto importante antes de mergulhar: tudo abaixo vem de um documento de rascunho não verificado, não de um lançamento oficial. Sem benchmarks públicos, sem acesso à API, sem página de preços. A Anthropic confirmou que o modelo existe e está em testes limitados. Todo o resto ainda é rascunho.
Codificação — “Pontuações Dramaticamente Mais Altas” Explicadas
O blog vazado afirma: “Comparado ao nosso melhor modelo anterior, o Claude Opus 4.6, o Capybara obtém pontuações dramaticamente mais altas em testes de codificação de software, raciocínio acadêmico e cibersegurança, entre outros.” Essa é uma linguagem significativa vinda de um documento interno — “dramaticamente mais altas” não é um texto de marketing cauteloso, é uma afirmação interna forte.
O que não temos: números específicos. Nenhuma pontuação específica foi publicada além da linguagem qualitativa no rascunho. Qualquer pessoa que citar números exatos de benchmark do Mythos agora está fabricando-os. A leitura honesta aqui é que a avaliação interna da Anthropic mostrou uma diferença grande o suficiente para justificar um novo nível de produto — o que por si só é um sinal significativo, mas não é o mesmo que ter dados verificados.

Melhorias no Raciocínio Acadêmico
O rascunho vazado agrupa o raciocínio acadêmico junto com a codificação como uma capacidade diferenciada chave. A Anthropic descreve o Mythos como “um modelo de uso geral com avanços significativos em raciocínio, codificação e cibersegurança.” Para desenvolvedores que constroem assistentes de pesquisa, pipelines de análise de documentos ou fluxos de trabalho de raciocínio jurídico/financeiro, isso vale a pena acompanhar — o Opus 4.6 já alcança 90,2% no BigLaw Bench, e se o Mythos expandir esse limite, a área de superfície de casos de uso se amplia consideravelmente.
Capacidades de Cibersegurança: Novo Território
Esta é a dimensão de capacidade que está recebendo mais cobertura — e por boas razões. O rascunho vazado descreve o modelo como “atualmente muito à frente de qualquer outro modelo de IA em capacidades cibernéticas” e avisa que ele “pressagia uma onda futura de modelos que podem explorar vulnerabilidades de maneiras que superam em muito os esforços dos defensores.”
Documentos internos vazados alertam que o modelo poderia aumentar significativamente os riscos de cibersegurança ao encontrar e explorar vulnerabilidades de software rapidamente, potencialmente acelerando uma corrida armamentista cibernética. É por isso que o lançamento inicial da Anthropic está restrito a organizações focadas em defesa cibernética — um movimento incomum que sinaliza preocupação genuína com o uso indevido, não apenas teatro de segurança padrão.
A tensão de uso dual aqui é real. O atual Opus 4.6 da Anthropic já demonstrou capacidade de identificar vulnerabilidades previamente desconhecidas em bases de código de produção, uma capacidade que a empresa reconheceu como de uso dual — ajudando tanto hackers quanto defensores. O Mythos parece levar essa capacidade significativamente mais longe, o que explica o lançamento cauteloso.
Este É um Novo Nível, Não Uma Atualização de Versão — Por Que Isso Importa
Capybara Acima do Opus Estruturalmente
O rascunho vazado afirma: “Capybara é um novo nome para um novo nível de modelo: maior e mais inteligente do que nossos modelos Opus — que eram, até agora, os mais poderosos.” Isso é estruturalmente diferente do Opus 4.5 → Opus 4.6. A Anthropic atualmente tem três níveis: Haiku, Sonnet, Opus. O Capybara adicionaria um quarto acima de todos eles.
Isso importa para como você arquiteta seus sistemas. Se você está construindo com a suposição de que o Opus é sempre o teto, um novo nível acima dele significa possíveis atualizações de capacidade que não são apenas melhorias incrementais de ajuste fino — elas representam uma classe diferente de taxas de sucesso em tarefas.
Preços: Mais Caro por Design
Ainda não existem preços oficiais, mas o sinal estrutural é claro. O blog de rascunho observa que o modelo é caro de executar e ainda não está pronto para lançamento geral. Dado que o Capybara fica acima do Opus em um novo nível, espere preços acima dos atuais $5/$25 por milhão de tokens para o Opus 4.6. Quanto acima é genuinamente desconhecido — mas planeje que seja significativamente mais alto, não apenas um pequeno incremento.
Isso não é necessariamente uma má notícia. A redução de preço de 67% do Opus 4.1 para o Opus 4.6 mostra que a Anthropic aprendeu a reduzir os preços de destaque ao longo das gerações. Um lançamento do Capybara a preços premium hoje não significa que ele ficará assim em 12 meses. O padrão sugere que a verdadeira questão de ROI é se o salto de capacidade justifica o custo na sua distribuição específica de tarefas.

Sua Equipe Deveria Esperar pelo Claude Mythos?
Esta é a decisão real pela qual você está aqui. Aqui está o framework honesto.
Se Você Está Construindo Agentes de Codificação ou Fluxos de Trabalho Agênticos
Construa agora com o Opus 4.6. A diferença de capacidade pode ser real, mas esperar por um modelo não lançado sem um cronograma público não é uma estratégia de produto. O Opus 4.6 já é o modelo publicamente disponível mais forte para codificação agêntica — Terminal-Bench 2.0 com 65,4% é uma linha de base significativa que suporta casos de uso de produção hoje.
O ponto mais importante: as decisões arquiteturais que você toma agora — estratégia de cache de prompts, orquestração de subagentes, padrões de uso de ferramentas — vão se transferir diretamente para o Mythos quando ele for lançado. Construa no Opus 4.6, projete para roteamento agnóstico de modelo, e você estará em uma posição muito melhor para migrar do que as equipes que esperaram e começaram do zero.
Se Sua Prioridade É Eficiência de Custo em Escala
Definitivamente construa agora. Espera-se que o Mythos seja mais caro do que o Opus 4.6, e não há indicação de um nível de orçamento equivalente no lançamento. Se você está executando cargas de trabalho de alto volume onde $5/$25 por milhão de tokens já requer otimização cuidadosa com processamento em lote e cache de prompts, o Mythos provavelmente não será seu modelo padrão — mesmo depois de estar disponível publicamente. Use o tempo para otimizar seus fluxos de trabalho do Opus 4.6; essas economias são reais e estão disponíveis hoje.
A matemática que vale a pena fazer: uma equipe gastando $2.500/mês no Opus 4.6 padrão pode realisticamente chegar a ~$250/mês com mixagem de modelos, processamento em lote e cache. Essa redução de 90% se acumula significativamente ao longo dos meses que você passaria esperando.
Se Seu Caso de Uso Envolve Pesquisa de Vulnerabilidades ou Segurança
Este é o único caso em que esperar faz sentido — mas você pode não ter escolha. O grupo de acesso inicial ao Mythos está focado em pesquisadores de segurança e defensores — o objetivo é preparar defesas antes que as capacidades ofensivas do modelo se tornem amplamente disponíveis. Se sua equipe trabalha em pesquisa de segurança ofensiva ou ferramentas defensivas, a medida certa é se candidatar ao acesso antecipado pelos canais da Anthropic e continuar construindo no Opus 4.6 enquanto isso.
Para ferramentas de segurança empresarial geral (varredura de código, conformidade, triagem de vulnerabilidades), o Opus 4.6 já é capaz e totalmente disponível. O Mythos provavelmente estende o teto, não o piso.
O Que Fazer Enquanto o Mythos Não Está Disponível Publicamente
Concretamente, veja como evitar esforço desperdiçado enquanto permanece posicionado para adotar o Mythos de forma eficiente:
Projete para roteamento agnóstico de modelo. Abstraia suas chamadas de modelo por trás de uma camada de roteamento para que trocar claude-opus-4-6 por uma futura string de modelo claude-capybara-* seja uma mudança de configuração, não uma reescrita arquitetural. Esta é uma boa prática independentemente do Mythos — ela também permite que você roteie tarefas sensíveis ao custo para o Sonnet 4.6 hoje.
# Exemplo: wrapper de roteamento agnóstico de modelo
import anthropic
MODEL_CONFIG = {
"flagship": "claude-opus-4-6", # troque aqui quando o Mythos for lançado
"balanced": "claude-sonnet-4-6",
"fast": "claude-haiku-4-5-20251001"
}
def call_claude(task_tier: str, messages: list, **kwargs):
client = anthropic.Anthropic()
return client.messages.create(
model=MODEL_CONFIG[task_tier],
max_tokens=1024,
messages=messages,
**kwargs
)Implemente o cache de prompts agora. De acordo com a documentação de cache de prompts da Anthropic, as gravações em cache incorrem em uma taxa adicional de 25% na primeira utilização, e depois são lidas com 90% de desconto nas utilizações subsequentes. Para fluxos de trabalho agênticos com prompts de sistema repetidos ou grandes blocos de contexto, esta é a única otimização de custo de maior alavancagem disponível — e funcionará da mesma forma no Mythos.
Acompanhe o cadência oficial de lançamento. A Anthropic confirmou testes com clientes de acesso antecipado. O modelo de lançamento gradual que a Anthropic está usando — primeiros parceiros de segurança, depois acesso mais amplo — sugere que a disponibilidade geral da API provavelmente estará disponível em semanas a meses, não em dias.
Avalie sua distribuição de tarefas honestamente. Se 80% das suas chamadas de API são resumo de documentos, perguntas e respostas ou extração estruturada, os avanços de codificação e cibersegurança do Mythos podem não fazer muita diferença para você. O Opus 4.6 já é suficientemente forte para essas cargas de trabalho. Reserve sua avaliação do Mythos para as tarefas onde você está atualmente atingindo o teto do Opus.
FAQ
P: Posso usar o Claude Mythos hoje?
Não. No final de março de 2026, o Claude Mythos (Capybara) está disponível apenas para um pequeno grupo de clientes de acesso antecipado, especificamente aqueles que trabalham em aplicações de defesa cibernética. Não há API pública, sem documentação e sem data de lançamento anunciada. O Claude Opus 4.6, acessível via claude-opus-4-6 na API da Anthropic, permanece o modelo publicamente disponível mais forte.
P: O Opus 4.6 ainda é o melhor modelo Claude público?
Sim. O Claude Opus 4.6 e o Sonnet 4.6 continuam sendo os modelos Claude publicamente disponíveis mais capazes — e já são notavelmente poderosos para codificação, raciocínio e tarefas complexas. O Opus 4.6 lidera os rankings públicos para codificação agêntica e está totalmente documentado com acesso estável à API na plataforma da Anthropic, AWS Bedrock, Google Vertex AI e Microsoft Foundry.
P: Quanto mais caro será o Claude Mythos?
Desconhecido. O rascunho vazado confirma que o modelo é “caro de executar,” e o novo nível Capybara situado acima do Opus estruturalmente implica um prêmio de preço acima dos atuais $5/$25 por milhão de tokens para o Opus 4.6. Nenhum preço oficial foi publicado. O precedente histórico mostra que a Anthropic reduz os preços dos modelos de destaque ao longo das gerações de modelos, então os preços do lançamento antecipado podem não refletir o custo de longo prazo.
Posts Anteriores:
Artigos relacionados
Apresentando o ByteDance Seedance 2.0 Mini no WaveSpeedAI

Claude Fable 5 com Fallback para Opus 4.8 Explicado

API do GLM-5.2: Preços, Contexto de 1M e Roteamento em Produção

Preços do GPT-5.4 Mini: Custo de Entrada, Cache e Saída

API MAI-Image-2.5: O Que os Desenvolvedores Precisam Saber
