Desempenho de Codificação do Claude Mythos: O Que Isso Significa para Fluxos de Trabalho de IA para Devs
O Claude Mythos supostamente obtém pontuações dramaticamente mais altas em codificação do que o Opus 4.6. Veja o que isso significa para desenvolvedores que criam agentes de codificação com IA em 2026.

Todos se concentraram no susto de segurança cibernética quando a Fortune publicou uma manchete ousada dizendo: a Anthropic havia acidentalmente deixado quase 3.000 arquivos internos expostos, incluindo um rascunho de post de blog sobre seu modelo não lançado. Mas como alguém que passa todos os dias desenvolvendo com Claude, o que chamou minha atenção não foi o vazamento em si — foram as afirmações silenciosas e explosivas enterradas naquele rascunho sobre o desempenho em programação.
Disponível na WaveSpeedAI — preços transparentes por token, endpoint compatível com OpenAI. Claude Opus 4.7 API → · Claude Sonnet 4.6 API → · Abrir Playground →
Neste artigo, você e eu, Dora, não vamos perseguir hype ou pânico de segurança, mas ir direto ao que realmente importa para desenvolvedores e equipes que lançam produtos reais, detalhando exatamente o que sabemos (e o que não sabemos) sobre as capacidades de programação do Claude Mythos / Capybara.
O que o Rascunho Vazado Diz sobre o Desempenho de Programação do Claude Mythos
A afirmação precisa do rascunho vazado: “Comparado ao nosso melhor modelo anterior, Claude Opus 4.6, o Capybara obtém pontuações dramaticamente mais altas em testes de programação de software, raciocínio acadêmico e segurança cibernética, entre outros.”
Essa é a totalidade do que a Anthropic colocou por escrito sobre desempenho em programação. Nenhuma porcentagem do SWE-bench, nenhuma pontuação do Terminal-Bench, nenhuma tabela de comparação. A frase “dramaticamente mais altas” é o sinal real — vaga, mas não sem sentido.

Para contexto, o Opus 4.6 atualmente lidera os modelos disponíveis publicamente no SWE-bench Verified (~80,8%), Terminal-Bench 2.0 e Humanity’s Last Exam. O porta-voz oficial da Anthropic confirmou que o modelo representa “avanços significativos em raciocínio, programação e segurança cibernética.” O treinamento está completo, testes de acesso antecipado estão em andamento, e programação é explicitamente uma das três dimensões primárias de capacidade. Todo o resto é inferência.
Por que Programação é a Capacidade Mais Importante para Este Nível de Modelo
Contexto do Terminal-Bench 2.0 e Pontuações Atuais do Opus 4.6
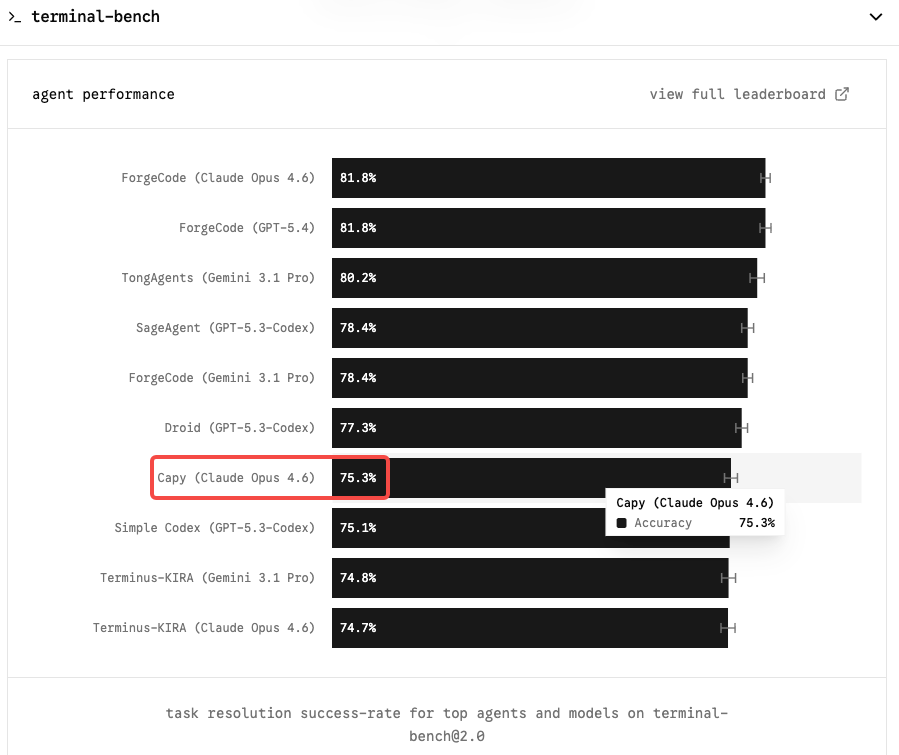
O Terminal-Bench 2.0 é o benchmark que mais importa para fluxos de trabalho de programação agêntica. Ao contrário do SWE-bench, que testa a resolução isolada de issues do GitHub, o Terminal-Bench avalia tarefas reais em um ambiente de terminal isolado — administração de sistemas, DevOps, fluxos de trabalho CLI de múltiplos passos. É mais difícil, mais representativo do uso em produção e menos suscetível à inflação causada por scaffolding.
O Claude Opus 4.6 ocupa o primeiro lugar com 65,4% no Terminal-Bench 2.0 e 72,7% no OSWorld. Um modelo do nível Capybara movendo esse número para a faixa de 75–85% seria uma mudança genuína para qualquer equipe executando agentes de programação autônomos.
No SWE-bench Verified, o panorama está mais comprimido: seis modelos agora pontuam dentro de 0,8 pontos um do outro. O Opus 4.6 fica em 80,8%; o Gemini 3.1 Pro entrega 80,6% a $2/$12 por milhão de tokens. O SWE-bench bruto não é mais um diferenciador significativo. O Terminal-Bench e a coerência em contextos longos são onde o Opus 4.6 justifica seu preço premium — e onde o Mythos provavelmente fará seu caso mais claro.
O que “Dramaticamente Mais Alto” Significa Estruturalmente
No rascunho, “dramaticamente mais alto” aparece ao lado de “mudança de patamar” — a mesma frase que o porta-voz da Anthropic usou publicamente. Nenhum dos termos é casual. O salto do Opus 4.1 para o Opus 4.6 foi uma melhoria geracional dentro do mesmo nível. “Mudança de patamar” implica algo diferente em natureza — mais parecido com a diferença entre Sonnet e Opus do que entre duas versões consecutivas do Opus.
Um modelo que supera significativamente o Opus 4.6 em programação seria uma ferramenta importante para desenvolvimento de software, depuração e fluxos de trabalho agênticos. A questão em aberto é quando ficará disponível e a que custo. Esse é o enquadramento honesto. A afirmação de desempenho é crível dado o histórico recente da Anthropic. A validação simplesmente ainda não chegou.
Implicações para Fluxos de Trabalho de Programação Agêntica
Tarefas de Código em Contexto Longo
A implicação prática mais imediata de um modelo do nível Capybara para equipes de programação não são as pontuações brutas de benchmark — é o que um raciocínio melhor faz em escala.
A janela de contexto de 1M do Claude Code agora está em GA para o Opus 4.6, fornecendo ~830K tokens utilizáveis após compactação — o suficiente para monorepos inteiros e conjuntos completos de documentação. Um modelo que supera dramaticamente o Opus 4.6 em programação, aplicado a essa mesma janela, significa melhor compreensão arquitetural em grandes bases de código e menos erros de raciocínio em refatorações de múltiplos arquivos. A janela de contexto não muda. A qualidade do raciocínio dentro dela mudaria.
Para equipes fazendo análise de grandes bases de código hoje — o tipo de trabalho onde você carrega 50K+ linhas de código-fonte e pede ao modelo para entender o quadro completo — esse é o caminho de atualização prático que mais importa.
Agentes de Depuração em Múltiplos Passos
A Anthropic lançou as Agent Teams como um recurso experimental com o lançamento do Opus 4.6, marcando um passo significativo nos fluxos de trabalho agênticos. Uma sessão age como líder da equipe — coordena o trabalho, atribui tarefas e sintetiza resultados. Os membros da equipe trabalham de forma independente, cada um em sua própria janela de contexto, e se comunicam diretamente entre si.
Os agentes de depuração em múltiplos passos são onde o valor composto de um modelo base melhor fica mais claro. Em uma configuração multi-agente, a qualidade do planejamento do líder determina o quão bem toda a operação é executada. Um modelo mais forte toma melhores decisões de decomposição de tarefas, escreve especificações de tarefas mais claras para subagentes e detecta erros de integração mais cedo.
O rascunho vazado apontou especificamente a programação de software ao lado da segurança cibernética como os domínios onde o Capybara supera “dramaticamente” o Opus 4.6. Se essa diferença for real e substancial em tarefas no estilo Terminal-Bench, ela se traduziria diretamente em agentes de depuração em múltiplos passos mais confiáveis que requerem menos intervenção humana para se recuperar de suposições incorretas.
Exploração Autônoma de Base de Código
Este é o caso de uso sobre o qual tenho mais curiosidade na prática. O Claude Code rastreia o problema pela sua base de código, identifica a causa raiz e implementa uma correção. A qualidade desse rastreamento é função da profundidade do raciocínio, não apenas do tamanho da janela de contexto.
Em um fluxo de trabalho típico de 2026, um desenvolvedor pode apresentar um requisito de alto nível e o agente líder vai decompô-lo em tarefas distintas, com membros da equipe utilizando o Model Context Protocol para acessar ferramentas externas, executar testes e realizar auditorias de segurança simultaneamente. Um modelo do nível Capybara funcionando como orquestrador nesse tipo de configuração tornaria todo o fluxo de trabalho mais autônomo — significando menos pedidos de esclarecimento, melhor decomposição inicial de tarefas e autocorreção mais confiável quando um subagente encontra um estado inesperado.
O que Desenvolvedores Devem Fazer Agora Enquanto o Mythos Não Está Disponível
Como Fazer Benchmark do Opus 4.6 para Seu Caso de Uso Atual
A coisa mais útil que você pode fazer agora é executar sua própria avaliação do Opus 4.6 — não contra benchmarks, mas contra sua carga de trabalho real. Benchmarks genéricos como o SWE-bench testam resolução isolada de issues com scaffolding padronizado. Seu agente de programação em produção tem uma estrutura de base de código específica, um conjunto específico de tarefas e um modo de falha específico. São esses que importam.
Uma avaliação de baseline prática para um agente de programação pode ser assim:
# Rastreamento simples de taxa de sucesso de tarefas
results = {
"task_id": [],
"model": [],
"success": [],
"turns_needed": [],
"context_used_tokens": [],
"cost_usd": []
}
# Execute as mesmas 20-30 tarefas representativas no Opus 4.6
# Rastreie: teve sucesso na primeira tentativa? Quantas rodadas?
# Que fração da janela de contexto de 1M foi consumida?
# Onde falhou — erro de raciocínio, uso de ferramenta ou estouro de contexto?A razão pela qual isso importa: quando o Mythos estiver disponível, você terá um baseline real para avaliar se a melhoria de capacidade justifica o prêmio de custo para seu fluxo de trabalho específico. “Dramaticamente mais alto” no conjunto de testes interno da Anthropic pode ou não se traduzir em uma diferença significativa na sua estrutura de base de código e distribuição de tarefas particulares.
O ‘melhor modelo’ é aquele que corresponde à forma como você se comunica com ele. Um modelo de nível intermediário em um excelente harness supera um modelo de fronteira em um ruim. A qualidade do seu harness — engenharia de prompt, configuração de ferramentas, estrutura do CLAUDE.md — é uma variável que você pode melhorar agora. O Mythos não vai consertar uma arquitetura de agente mal projetada.
Decisões de Arquitetura que Escalarão com um Modelo Mais Capaz
A boa notícia é que arquiteturas agênticas bem projetadas são agnósticas ao modelo na camada de roteamento. Os padrões que valem a pena construir agora:
Separe orquestração de execução. Um agente orquestrador que decompõe tarefas, atribui arquivos e revisa saídas — apoiado por subagentes especializados para implementação — pode trocar seu modelo base com uma única mudança de parâmetro. Construa essa separação agora e a atualização para o Mythos se torna uma atualização de configuração, não uma refatoração arquitetural.
Use o CLAUDE.md como contexto de runtime, não como prompt específico de sessão. O arquivo CLAUDE.md serve como a “constituição” para agentes de IA dentro de um repositório — fornecendo o contexto necessário sobre arquitetura do projeto, padrões de código e comandos de build que permitem que agentes operem sem microgerenciamento humano. Um CLAUDE.md bem estruturado reduz os custos de exploração por tarefa no Opus 4.6 hoje e ampliará os ganhos de um modelo mais forte amanhã.
Projete para a janela de contexto de 1M, não contra ela. Equipes que já reestruturaram sua estratégia de carregamento de arquivos, lógica de chunking e gerenciamento de contexto para trabalhar dentro da janela de 1M estarão posicionadas para aproveitar ao máximo a capacidade de raciocínio do Mythos nessa mesma janela. Não construa soluções alternativas para limites de contexto que assumam que o teto não vai subir.
O que Observar no Lançamento para Equipes Focadas em Programação
Os sinais que mais importam para desenvolvedores são diferentes dos sinais corporativos gerais. Para equipes focadas em programação especificamente:
Pontuações SWE-bench e Terminal-Bench no lançamento. A Anthropic historicamente publica essas junto com os lançamentos de modelos. Se o Mythos cumprir a promessa de “dramaticamente mais alto”, você esperaria que as pontuações do Terminal-Bench 2.0 se movessem significativamente acima dos 65,4% do Opus 4.6. Um salto para 75%+ validaria a afirmação para fluxos de trabalho agênticos.
Atualização da string de modelo do Claude Code. Verifique a documentação do Claude Code e a visão geral dos modelos da API para um novo alias de modelo. O Claude Code historicamente atualizou seu modelo padrão dentro de dias após um novo lançamento flagship. Se o Mythos for lançado na API pública, é aqui que ele aparecerá primeiro para equipes de programação.
Anúncio de compatibilidade das Agent Teams. As Agent Teams foram lançadas como experimentais com o Opus 4.6. Se o Mythos se integra nativamente com as Agent Teams no lançamento — ou requer uma configuração separada — determinará a rapidez com que as equipes podem movê-lo para fluxos de trabalho multi-agente.
O changelog da Anthropic e a documentação de preços. Essas duas páginas são o sinal confiável mais antecipado antes de qualquer anúncio na imprensa. Uma nova string de modelo e uma nova linha de preços aparecerão aqui primeiro.
Perguntas Frequentes
O Claude Mythos está disponível para tarefas de programação agora?
Não. No início de abril de 2026, não há endpoint de API público para o Claude Mythos ou o nível Capybara. O Claude Mythos / Capybara está disponível apenas para um pequeno grupo de clientes de acesso antecipado selecionados pela Anthropic, sem API pública, sem precificação anunciada e sem data de lançamento confirmada. O Claude Opus 4.6 — 80,8% no SWE-bench Verified, 65,4% no Terminal-Bench 2.0 — continua sendo a melhor opção disponível publicamente.
O Claude Mythos funcionará com o Claude Code?
Quase certamente sim, eventualmente. A arquitetura do Claude Code é agnóstica ao modelo; mudar para um novo flagship é uma única mudança de parâmetro. Mas isso não está confirmado para o Mythos no lançamento.
Devo esperar pelo Mythos para construir minha ferramenta de programação com IA?
Não. A Anthropic declarou que precisa se tornar “muito mais eficiente antes de qualquer lançamento geral.” Construir no Opus 4.6 agora significa que sua arquitetura está validada em produção quando o Mythos chegar. A atualização será uma troca de string de modelo. As equipes que esperarem estarão tentando recuperar o atraso.
Posts Anteriores:
Artigos relacionados
Apresentando o ByteDance Seedance 2.0 Mini no WaveSpeedAI

Claude Fable 5 com Fallback para Opus 4.8 Explicado

API do GLM-5.2: Preços, Contexto de 1M e Roteamento em Produção

Preços do GPT-5.4 Mini: Custo de Entrada, Cache e Saída

API MAI-Image-2.5: O Que os Desenvolvedores Precisam Saber
