Z-Image-Turbo LoRA no WaveSpeed: Aplique Estilos Personalizados (Até 3 LoRAs)
Use o Z-Image-Turbo LoRA para aplicar estilos personalizados, personagens e identidades de marca. Combine até 3 LoRAs, US$ 0,01/imagem. Inclui guia de treinamento (US$ 1,25/1000 etapas).

Olá, sou a Dora. Assim como eu, você também se cansou de ver seus mockups fugindo da identidade visual? Um azul que ficava puxando para o turquesa, uma marca que perdia os contornos nas bordas, uma foto de produto que parecia… quase certa. “Quase” serve para rascunhos, mas gera ruído. Então, na semana passada, experimentei o LoRA com Z-Image-Turbo no WaveSpeed. Não por novidade, mas para ver se conseguia transformar “bom o suficiente” em “pode publicar” sem precisar ficar babando em prompts.
Estas são minhas anotações: o que funcionou, onde travou, e como configurei para que ficasse fora do caminho assim que estivesse calibrado.
O que é LoRA?
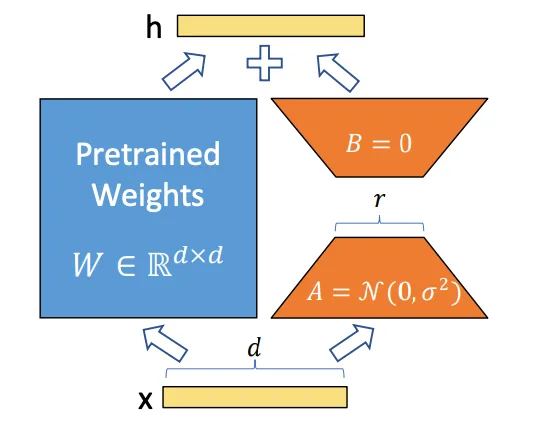 LoRA (Low-Rank Adaptation) é uma camada pequena e direcionada que empurra um modelo grande em direção a um estilo, personagem ou estética específicos, sem precisar retreinar o modelo inteiro. Pense nisso como uma lente suave que você pode adicionar ou remover. O modelo base mantém suas habilidades amplas; o LoRA ensina a ele uma preferência.
LoRA (Low-Rank Adaptation) é uma camada pequena e direcionada que empurra um modelo grande em direção a um estilo, personagem ou estética específicos, sem precisar retreinar o modelo inteiro. Pense nisso como uma lente suave que você pode adicionar ou remover. O modelo base mantém suas habilidades amplas; o LoRA ensina a ele uma preferência.
Na prática, os arquivos LoRA são compactos, rápidos de treinar e baratos de trocar. Essa última parte importa para fluxos de trabalho. Não quero um checkpoint de modelo separado para cada paleta de marca ou personagem. Quero um backbone rápido (Z-Image-Turbo) e alguns controles intercambiáveis.
Por que LoRA para Z-Image-Turbo?
 O Z-Image-Turbo no WaveSpeed é otimizado para velocidade. Ótimo para iterar, mas velocidade por si só não resolve o problema de “estilo consistente.” O LoRA preenche essa lacuna. Com ele posso:
O Z-Image-Turbo no WaveSpeed é otimizado para velocidade. Ótimo para iterar, mas velocidade por si só não resolve o problema de “estilo consistente.” O LoRA preenche essa lacuna. Com ele posso:
- manter o modelo base rápido,
- anexar um LoRA pronto para um visual ou personagem,
- ou treinar um LoRA personalizado pequeno para meus próprios assets.
O que me surpreendeu foi o quanto o parâmetro de escala me dava controle. Uma escala baixa (0.3–0.6) preservava os pontos fortes do modelo base. Uma mais alta (0.8–1.0) empurrava com mais força para o estilo aprendido, às vezes com força demais. Comecei baixo, fui aumentando até ficar certo. Esse hábito simples reduziu os re-renders em cerca de um terço ao longo da semana.
Usando LoRAs Prontos
Primeiro experimentei LoRAs prontos porque não queria treinar nada antes de conhecer os limites. O WaveSpeed trata o LoRA como um plug-in: aponta para um arquivo, define uma escala, pronto.
Encontrando LoRAs Compatíveis
A compatibilidade depende do formato e da família do modelo base. Se um LoRA foi treinado em um backbone de difusão similar (e indicado como compatível com Z-Image-Turbo ou sua linhagem), geralmente funcionava bem. Mantive uma lista de verificação curta:
- mesma família de modelo base ou adjacente,
- notas de versão se disponíveis (data + tag do modelo),
- uma galeria de prévia que mostra variedade, não só os melhores resultados selecionados.
Quando um LoRA parecia “perfeito demais,” eu suspeitava de overfitting. Nos meus testes, esses tendiam a entrar em colapso em prompts fora de uma faixa estreita. Os melhores conjuntos aguentavam quando eu mudava termos de iluminação ou câmera.
Parâmetros da API: path + scale
 A API do WaveSpeed usa uma estrutura simples por LoRA: um path (onde o arquivo LoRA está) e um scale (com que intensidade ele se aplica). O path pode ser um asset hospedado no WaveSpeed ou uma URL assinada que você controla. O scale é um float. Fiquei principalmente entre 0.35 e 0.7. Abaixo de 0.3, muitas vezes não conseguia perceber que estava ativo; acima de 0.8, às vezes destruía a composição.
A API do WaveSpeed usa uma estrutura simples por LoRA: um path (onde o arquivo LoRA está) e um scale (com que intensidade ele se aplica). O path pode ser um asset hospedado no WaveSpeed ou uma URL assinada que você controla. O scale é um float. Fiquei principalmente entre 0.35 e 0.7. Abaixo de 0.3, muitas vezes não conseguia perceber que estava ativo; acima de 0.8, às vezes destruía a composição.
Uma observação das execuções reais: se o seu path estiver errado ou o asset for privado sem o token correto, você nem sempre receberá um erro claro — apenas imagens que parecem do modelo base. Quando algo parecia suspeito e genérico demais, eu verificava o path novamente.
Empilhando Múltiplos LoRAs (Até 3)
Você pode empilhar até três LoRAs. Experimentei um para tratamento de cor, um para textura de marca, e um para características de personagem. Funcionou, mas só depois de equilibrar as escalas. Se dois LoRAs brigam (digamos, um insiste em grão suave de filme enquanto outro adiciona brilho nítido de produto), a imagem parece indecisa. Minha regra:
- começar cada um em 0.3,
- identificar o LoRA âncora (o visual inegociável),
- aumentar esse lentamente,
- ajustar os outros em incrementos de 0.05–0.1 até que complementem em vez de competir.
Empilhar me economizou tempo quando precisei tanto da identidade da marca quanto de um personagem recorrente. Não economizou tempo quando tentei forçar três estilos pesados ao mesmo tempo. Isso apenas me devolveu ao ciclo de tentativa e erro.
Implementação pela API
Veja como montei isso em um script pequeno. Usei prompts que realmente uso em produção: mockups de produto com variações de fundo, mais alguns retratos de personagens para documentação interna.
Estrutura do Parâmetro LoRA
O corpo da requisição inclui um array loras. Cada item:
- path: string (caminho de asset WaveSpeed ou URL assinada)
- scale: float (0.0–1.0; recomendo 0.3–0.7 para começar)
Os outros parâmetros do Z-Image-Turbo (prompt, negative_prompt, seed, steps, width/height) funcionam normalmente. Seeds me ajudaram a comparar mudanças de scale em condições iguais.
Exemplo de Código Python
import requests
API_KEY = "YOUR_WAVESPEED_KEY"
ENDPOINT = "https://api.wavespeed.ai/api/v3/wavespeed-ai/z-image/turbo"
payload = {
"prompt": "minimal product photo of a cobalt-blue bottle on soft textured linen, natural window light, 50mm, f2.8",
"negative_prompt": "text, watermark, harsh shadows, warped label",
"width": 768,
"height": 768,
"steps": 16,
"seed": 12345,
"loras": [
{"path": "wavespeed://assets/brand/linen_texture_lora.safetensors", "scale": 0.45},
{"path": "wavespeed://assets/brand/cobalt_hue_lora.safetensors", "scale": 0.55}
]
}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
r = requests.post(ENDPOINT, json=payload, headers=headers, timeout=60)
r.raise_for_status()
result = r.json()
# Espera imagens em base64 ou URLs dependendo das configurações da sua conta
print(result.get("images", []))Nas minhas execuções, 16 passos com Z-Image-Turbo foi suficiente para qualidade de prévia. Para imagens finais, fui para 22–24 passos. Isso adicionou ~0.3–0.6 segundos por imagem na minha conta, o que era aceitável.
Equilibrando as Escalas do LoRA
Iterava assim:
- fixar o seed,
- definir todos os LoRAs em 0.3,
- escolher o âncora e aumentá-lo em 0.1 até parecer certo,
- ajustar os outros em incrementos de 0.05–0.1.
Manter o seed fixo enquanto ajustava as escalas me ajudou a ver o efeito diretamente. Quando gostei do equilíbrio, desfixei o seed para variação. Isso não economizou tempo no começo — passei 15–20 minutos só para ter uma noção. Mas no terceiro dia, percebi que havia parado de ajustar prompts. As escalas carregavam o estilo, e eu focava em layout e copy.
Treinando LoRAs Personalizados
Depois dos prontos, treinei um LoRA pequeno para a forma de garrafa e o estilo de rótulo de um cliente. Fiz isso para cortar a troca de mensagens onde o ângulo do gargalo e o brilho do rótulo continuavam derivando.
Preparando os Dados de Treinamento (Upload ZIP)
Reuni 18 imagens, limpei os fundos e mantive os metadados consistentes. Zipei tudo em uma pasta simples, nomes de arquivo em minúsculas, sem espaços, e fiz o upload. Adicionei 3–4 legendas por imagem quando o texto do rótulo importava. Quando não importava, deixei as legendas mínimas. Mais legendas ajudaram o rótulo a manter a legibilidade.
Uma pequena fricção: imagens quase idênticas não ajudavam. Removi as duplicatas próximas e vi menos overfitting.
Parâmetros de Treinamento
Mantive leve:
- resolução: recortes quadrados de 768,
- tamanho do batch: 1,
- taxa de aprendizado: padrão conservador,
- passos de treinamento: 3.000–6.000 para estilo + forma,
- rank da rede (r): moderado; aumentar deixava mais “alto” do que eu queria.
Quando ultrapassei ~8.000 passos, começou a impor a garrafa em prompts onde não pedi. Não ideal. Menos passos com um dataset mais limpo ganhou.
Preço: $1,25 por 1.000 Passos
 Minhas duas execuções (3.500 e 5.000 passos) custaram $10,63 no total a $1,25 por 1.000 passos. É razoável se o LoRA se pagar por alguns meses.
Minhas duas execuções (3.500 e 5.000 passos) custaram $10,63 no total a $1,25 por 1.000 passos. É razoável se o LoRA se pagar por alguns meses.
Orçamento Típico de Treinamento
O que eu orçaria agora:
- LoRA somente de estilo: 2.000–4.000 passos ($2,50–$5,00),
- personagem com expressões: 5.000–8.000 passos ($6,25–$10,00),
- forma do produto + detalhes do rótulo: 3.000–6.000 passos ($3,75–$7,50).
Eu faria uma rodada mais curta primeiro, verificaria os resultados, depois completaria se fosse promissor. Duas execuções menores ganham de uma longa sessão de overfitting.
Casos de Uso
Estes são os pontos onde o LoRA no Z-Image-Turbo me ajudou a entregar mais rápido — não todo dia, mas de forma confiável quando a tarefa se encaixava.

Consistência de Estilo de Marca
Se você está cansado de redigitar dicas de marca em cada prompt, um LoRA de estilo suave em 0.4–0.6 mantém cor, contraste e textura alinhados. Usei isso para variantes de redes sociais e banners web. Não os tornou brilhantes; apenas os tornou consistentes. Esse é o ponto. Economizei talvez 5–7 minutos por entrega ao pular a segunda rodada de “ajustar a vibe.”
LoRAs de Personagem
Para documentação interna e um mascote leve que aparece nas telas de onboarding, um LoRA de personagem manteve as características estáveis em diferentes ângulos. Empilhá-lo com um tratamento de cor suave funcionou, mas só depois de reduzir a escala do personagem para 0.35. Qualquer coisa mais alta e ele atropelava a iluminação. Uma vez calibrado, removeu uma carga mental estranha: parei de me preocupar se o rosto iria derivar.
Estéticas Específicas de Produto
O LoRA personalizado de garrafa reduziu a distorção do rótulo e preservou a geometria do gargalo em close-ups. Não era perfeito — reflexos apertados ainda precisavam de algumas tentativas — mas diminuiu o número de renders inutilizáveis. A vitória silenciosa foi a previsibilidade. Quando digitei “ângulo de três quartos em linho,” recebi isso, não uma variante surpresa.
Quem pode gostar: pessoas que já sabem o que querem e estão cansadas de brigar com o modelo. Quem não vai gostar: quem explora estilos novos e selvagens a cada vez. LoRA é um estabilizador. Brilha quando você valoriza menos surpresas em vez de mais fogos de artifício.
Artigos relacionados
Apresentando o ByteDance Seedance 2.0 Mini no WaveSpeedAI

Claude Fable 5 com Fallback para Opus 4.8 Explicado
API do GLM-5.2: Preços, Contexto de 1M e Roteamento em Produção
Preços do GPT-5.4 Mini: Custo de Entrada, Cache e Saída
API MAI-Image-2.5: O Que os Desenvolvedores Precisam Saber