Gemini 3.1 Flash-Lite: Recursos, Casos de Uso e Como Se Compara ao Flash
Gemini 3.1 Flash-Lite é o modelo de inferência de menor custo do Google. Recursos, casos de uso reais e uma comparação direta com o Gemini Flash.

Percebi algo estranho quando o Google lançou o Gemini 3.1 Flash-Lite em 3 de março. Normalmente, eles lançam primeiro o modelo Flash mais capaz — ou pulam a camada Lite completamente. Desta vez, foram direto para a opção econômica. Essa mudança me fez prestar atenção.
Disponível na WaveSpeedAI — preços transparentes por token, endpoint compatível com OpenAI. Gemini 2.5 Pro API → · Gemini 2.5 Flash Lite API → · Abrir Playground →
Sou Dora. Tenho testado o modelo pelo último dia, e o que me surpreendeu não foi apenas a velocidade. Foi como a estrutura de preços de repente fez certos fluxos de trabalho parecerem… acessíveis de uma forma que não eram antes.

O Que É o Gemini 3.1 Flash-Lite
O Gemini 3.1 Flash-Lite ocupa a posição mais básica na nova linha de modelos do Google, mas “básico” não significa o que costumava significar. De acordo com a documentação oficial do Google, é o modelo Gemini mais econômico, otimizado para casos de uso com baixa latência e tráfego de alto volume. Ele visa corresponder ao desempenho do Gemini 2.5 Flash nas principais áreas de capacidade, sendo significativamente mais rápido e barato.
Seu lugar na linha Gemini 3.1
A família Gemini 3 agora tem três camadas bem definidas. No topo, está o Gemini 3.1 Pro — o peso-pesado para tarefas de raciocínio complexo. No meio fica o Gemini 3 Flash, que combina inteligência de nível Pro com velocidade Flash. E agora, o Flash-Lite ocupa o slot de alto volume e sensível a custos.
O que torna isso interessante é que o Flash-Lite não é uma versão simplificada do Flash. Na verdade, ele é baseado na arquitetura do Gemini 3 Pro, depois otimizado especificamente para throughput e latência. Essa escolha arquitetural aparece nos benchmarks — ele não é apenas mais rápido, é mais inteligente do que se esperaria pelo preço.
Como funciona a lógica de camadas Pro / Flash / Flash-Lite
A abordagem em camadas não é sobre recursos — é sobre alocação de computação. O Pro gasta mais tokens pensando em problemas complexos. O Flash equilibra raciocínio com velocidade. O Flash-Lite minimiza o raciocínio interno por padrão, mas você pode ajustá-lo.
Essa última parte é nova. O Google adicionou o que chamam de “níveis de raciocínio” — mínimo, baixo, médio ou alto. Para uma tarefa simples de tradução, você define como mínimo e obtém resultados instantâneos. Para algo que precisa de mais precisão, você aumenta e aceita latência e custo ligeiramente maiores.
Testei isso com um lote de tickets de suporte ao cliente. Com raciocínio mínimo, as respostas voltavam em menos de dois segundos. No médio, levava cinco segundos, mas captava nuances que a passagem rápida havia perdido. O controle parece prático.
Recursos Principais do Gemini 3.1 Flash-Lite
Custo de inferência ultrabaixo
O preço é de $0,25 por milhão de tokens de entrada e $1,50 por milhão de tokens de saída. Para ter uma perspectiva: o Gemini 3.1 Pro começa em $2,00 por milhão de tokens de entrada e $18 por milhão de tokens de saída para cargas de trabalho exigentes. O Flash-Lite custa aproximadamente um oitavo do Pro para tarefas básicas.
Mas o que me surpreendeu — também é mais barato que o Gemini 2.5 Flash (que custava $0,30/$2,50), apesar de ser mais capaz. Isso é incomum. Normalmente se paga mais por atualizações.
Alto throughput e baixa latência
O Google afirma que o Flash-Lite gera saída a 363 tokens por segundo, e nos meus testes isso parece preciso. Mais importante, o tempo até o primeiro token — o momento em que você para de esperar e começa a ver a saída — é 2,5 vezes mais rápido que o Gemini 2.5 Flash, de acordo com seus benchmarks internos.
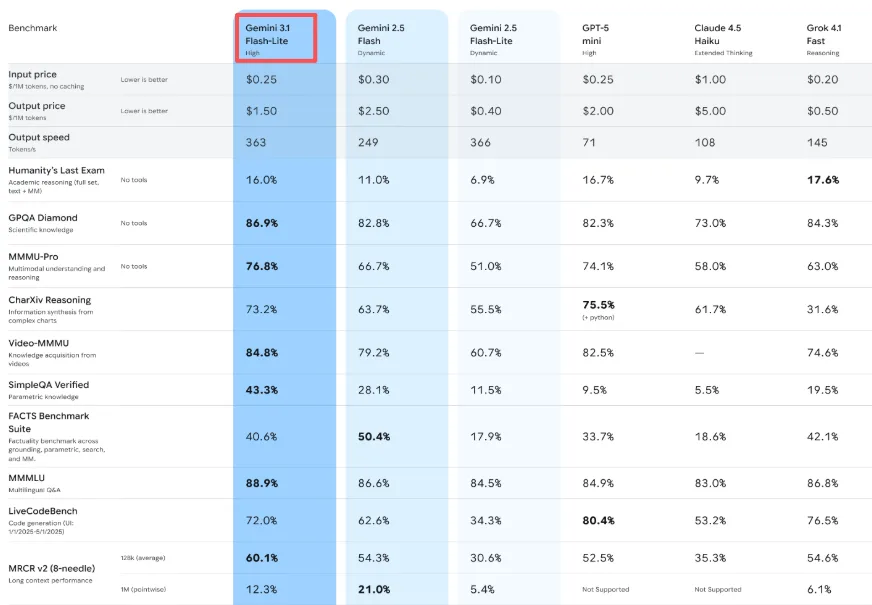
Percebi isso mais claramente ao construir um pipeline simples de moderação de conteúdo. A diferença entre uma espera de três segundos e uma de um segundo não parece muito. Mas quando você está processando centenas de itens, esse atraso se acumula. Com o Flash-Lite, o pipeline parecia responsivo em vez de lento.
Suporte a entrada multimodal
O Flash-Lite lida com texto, imagens, áudio e vídeo. A janela de contexto chega a 1 milhão de tokens, e pode gerar até 64.000 tokens de saída de texto.
Testei com uma combinação de imagens de produtos e descrições para um protótipo de e-commerce. Ele os marcou de forma consistente e rápida — usuários iniciais como a Whering relataram 100% de consistência na marcação de itens para categorias de moda complexas. Esse tipo de confiabilidade importa quando você está construindo sistemas que não podem se dar ao luxo de errar.
Janela de contexto longa
A janela de contexto de 1 milhão de tokens significa que você pode alimentá-lo com documentos inteiros, longos threads de conversa ou grandes conjuntos de dados sem precisar dividi-los em partes menores primeiro. Não uso a janela completa com frequência, mas quando uso — como ao analisar PDFs de múltiplas páginas — é a diferença entre um fluxo de trabalho tranquilo e um frustrante.
Gemini 3.1 Flash-Lite vs Flash: Comparação Direta
Quando usar o Flash-Lite
Use o Flash-Lite quando estiver executando milhares ou milhões de tarefas semelhantes. Pipelines de tradução, filas de moderação de conteúdo, análise de sentimento em escala, extração básica de dados — qualquer coisa onde a tarefa é bem definida e o custo por token importa mais do que raciocínio profundo.
Também descobri que funciona bem como um roteador. Você pode usar o Flash-Lite para classificar as solicitações recebidas como “simples” ou “complexas” e, em seguida, rotear as complexas para Flash ou Pro. Isso economiza dinheiro sem sacrificar qualidade onde importa.
Quando usar Flash em vez disso
Se a tarefa requer raciocínio em múltiplas etapas, resolução criativa de problemas ou lidar com instruções ambíguas, o Flash é a melhor escolha. Custa o dobro, mas também é mais inteligente — especialmente para tarefas de codificação, onde corresponde ou supera o Pro em alguns benchmarks.
Testei ambos em uma tarefa que envolvia gerar componentes de UI a partir de prompts em linguagem natural. O Flash-Lite conseguia lidar com solicitações diretas (“criar um formulário de login”), mas tinha dificuldades com as vagas (“design algo moderno e limpo”). O Flash lidou com ambas.
Casos de Uso do Gemini 3.1 Flash-Lite
Roteamento de agentes de IA e classificação de tarefas
Um dos casos de uso mais elegantes que vi é usar o Flash-Lite como controlador de tráfego. Quando um usuário envia uma solicitação, o Flash-Lite a lê, determina a complexidade e a roteia para o modelo apropriado — Flash para tarefas médias, Pro para as difíceis.
Esse padrão já está sendo usado em ferramentas de produção. O Gemini CLI de código aberto usa o Flash-Lite exatamente para isso, e funciona porque o modelo é rápido e barato o suficiente para adicionar essa etapa de roteamento sem aumentar perceptivelmente a latência ou o custo.
Automação de chat e suporte de alto volume
O suporte ao cliente é onde as economias de custo realmente aparecem. Se você está lidando com dezenas de milhares de tickets de suporte diariamente, a diferença entre $0,25 e $2,00 por milhão de tokens de entrada escala rapidamente.
O Flash-Lite pode lidar com perguntas simples, extrair intenções e rotear tickets que precisam de atenção humana. Ele não vai resolver problemas técnicos complexos, mas não precisa. Ele só precisa ser confiável e rápido.
Moderação de conteúdo e marcação
Construí um pipeline de teste rápido para moderar conteúdo gerado por usuários — sinalizando spam, linguagem inadequada e postagens fora do tema. O Flash-Lite processou cerca de 500 itens em menos de um minuto, com precisão consistente.
A chave aqui é a consistência. Alguns modelos desviam ao longo do tempo ou dão respostas diferentes para entradas semelhantes. O Flash-Lite permaneceu previsível em execuções repetidas, o que importa quando você está construindo sistemas que precisam se comportar da mesma forma sempre.
Pipelines de pré-processamento de documentos
O Flash-Lite se destaca na extração de dados estruturados. Dado um lote de faturas ou recibos, ele pode extrair campos-chave — datas, valores, nomes de fornecedores — e emiti-los como JSON.
Testei isso com uma mistura de faturas em PDF, e ele lidou com a maioria delas de forma limpa. As que tiveram dificuldades eram digitalizações de baixa qualidade com texto ruim, mas isso é uma limitação da entrada, não do modelo.
O Que o Flash-Lite Significa para o Design de Infraestrutura de IA

O padrão de arquitetura de modelo em camadas
O lançamento do Flash-Lite completa o que está começando a parecer um padrão padrão da indústria: uma pilha de modelos de três camadas. Você tem um peso-pesado para problemas difíceis, uma opção equilibrada para uso cotidiano e um leve para trabalho repetitivo de alto volume.
Isso não é novo — a OpenAI tem GPT-5 / GPT-5 mini, a Anthropic tem Claude Opus / Sonnet / Haiku — mas a implementação do Google é interessante porque as diferenças de preço são maiores. O Flash-Lite é genuinamente barato em comparação ao Pro, o que torna certos fluxos de trabalho economicamente viáveis que não eram antes.
Roteador barato + raciocínador poderoso — por que isso importa
O padrão que continuo vendo é: use um modelo barato para decidir com que tipo de tarefa você está lidando, depois roteie para um modelo mais caro apenas quando necessário. Isso não é apenas sobre economizar dinheiro. Também melhora a latência para tarefas simples, porque você não está esperando um modelo peso-pesado inicializar.
Tentei isso com um lote misto de 100 tarefas — metade simples, metade complexas. Usando o Flash-Lite como roteador, as tarefas simples terminaram em segundos, e as complexas foram roteadas para o Flash. O custo total foi cerca de 40% menor do que executar tudo pelo Flash, sem perda de qualidade nas tarefas complexas.
Essa arquitetura só funciona se o roteador for rápido e barato o suficiente para não se tornar o gargalo. O Flash-Lite é.
Disponibilidade Atual e Status da API
O Gemini 3.1 Flash-Lite está disponível agora em pré-visualização através da API Gemini no Google AI Studio e do Vertex AI. Ele não está no aplicativo Gemini para consumidores — este é focado em desenvolvedores.
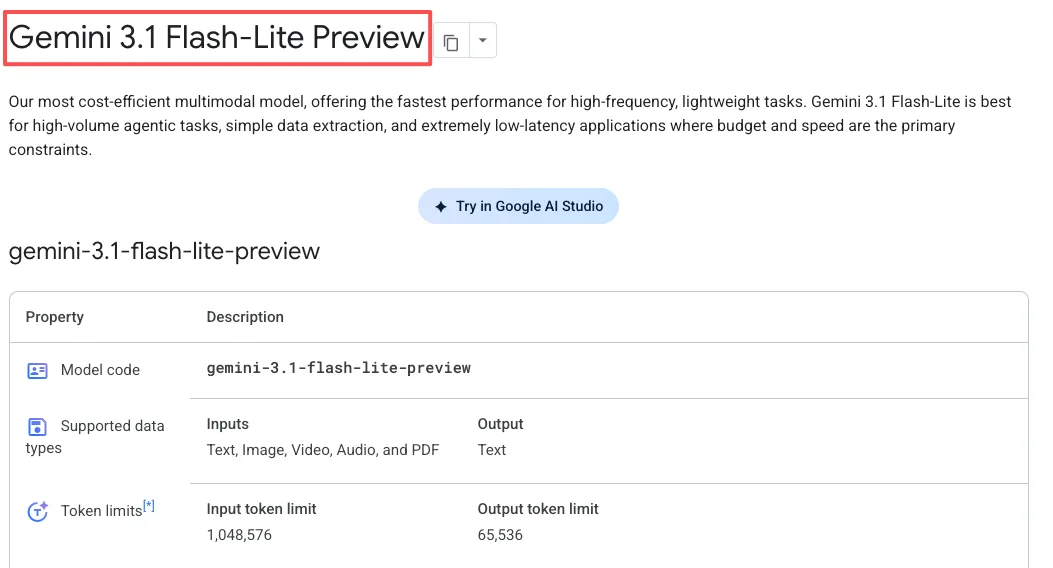
Modelos em pré-visualização podem mudar antes de se tornarem estáveis, e têm limites de taxa mais restritos. Na prática, não atingi esses limites em testes normais, mas se você está planejando implantação em produção em escala séria, é algo a observar.
O modelo também está sendo atualizado ativamente. As notas de versão do Google mostram melhorias contínuas no seguimento de instruções, qualidade de entrada de áudio e capacidades de raciocínio. Ainda são os primeiros dias — provavelmente ficará melhor nos próximos meses.
Um pensamento persistente
O que continuo voltando não é a velocidade ou o custo. É o fato de que o Flash-Lite faz certos fluxos de trabalho parecerem menos experimentos e mais utilitários. Quando o custo cai o suficiente, você para de perguntar “devo usar IA para isso?” e começa a perguntar “como construo isso para que escale?”
Essa mudança — da novidade para a infraestrutura — é onde as ferramentas começam a persistir.
Artigos relacionados
Apresentando o ByteDance Seedance 2.0 Mini no WaveSpeedAI

Claude Fable 5 com Fallback para Opus 4.8 Explicado
API do GLM-5.2: Preços, Contexto de 1M e Roteamento em Produção
Preços do GPT-5.4 Mini: Custo de Entrada, Cache e Saída
API MAI-Image-2.5: O Que os Desenvolvedores Precisam Saber