DeepSeek V4 Context Caching: Reduza Custos em 90% com Prompts Repetidos
O preço de cache hit do DeepSeek é 90% mais barato. Aprenda a estruturar prompts para máxima utilização do cache.

Olá, sou Dora. Uma pequena coisa me atrapalhou semana passada: executei o mesmo prompt três vezes porque não conseguia lembrar onde deixei o rascunho mais recente. O resultado mal mudou, mas meu limite de requisições sim. Foi isso que me levou a pensar num cache do DeepSeek v4.
 Não espero milagres. Só quero menos chamadas desnecessárias, latência mais estável e um pouco de folga nos limites de requisições. Como o v4 ainda não está amplamente documentado, comecei analisando o que funciona na prática com o v3 e APIs semelhantes, e depois modelei alguns padrões do lado do cliente com os quais consigo conviver. Se a DeepSeek lançar um cache oficial para o v4, quero estar pronta para integrá-lo sem refazer todo o meu fluxo de trabalho.
Não espero milagres. Só quero menos chamadas desnecessárias, latência mais estável e um pouco de folga nos limites de requisições. Como o v4 ainda não está amplamente documentado, comecei analisando o que funciona na prática com o v3 e APIs semelhantes, e depois modelei alguns padrões do lado do cliente com os quais consigo conviver. Se a DeepSeek lançar um cache oficial para o v4, quero estar pronta para integrá-lo sem refazer todo o meu fluxo de trabalho.
Disponível na WaveSpeedAI — preços transparentes por token, endpoint compatível com OpenAI. DeepSeek V3.2 API → · DeepSeek R1 API →
É assim que estou abordando a questão do cache do deepseek v4: assumir limites, cachear o que é repetível, retentar com calma e monitorar os indicadores certos.
Limites de Requisições Esperados
Ainda não encontrei uma tabela clara e pública para o v4, então tratei isso como uma conexão de voo: assuma timing apertado e prepare-se para atrasos.
O que sei trabalhando com o DeepSeek v3 (e provedores similares) é simples o suficiente:
- Geralmente há dois limites que importam no dia a dia: requisições por minuto (RPM) e tokens por minuto (TPM). Erros 429 aparecem rapidamente ao fazer lote de requisições ou executar jobs em segundo plano.
- Picos às vezes passam, até que não passam mais. Cargas irregulares podem funcionar por um minuto e travar no seguinte.
- Os limites podem variar por chave, nível de conta e às vezes por IP. Isso faz os testes locais parecerem generosos e a produção, menos tolerante.
Então, quando penso em um cache do deepseek v4, estou combinando isso com um tratamento conservador dos limites de requisições. O objetivo não é espremer cada última chamada, mas suavizar a curva para não passar a tarde inteira perseguindo erros 429.
Com Base nos Limites Atuais do V3
Fiz alguns testes leves em janeiro de 2026 usando uma mistura de chamadas de geração e reranking nos endpoints do v3. Nada científico, apenas o suficiente para sentir os limites. Algumas anotações que fiz:
- Prompts com muitos tokens (janelas de contexto longas) atingem o TPM antes do RPM. Isso significa que cachear as partes pesadas compensa mesmo que os outputs mudem.
- Prompts curtos e repetidos (verificações de saúde, execuções de templates) atingem o RPM primeiro. Estes são candidatos ideais para um cache de resposta com TTL curto.
- Backoff funciona, mas backoff exponencial sozinho não é um plano. Ele precisa de uma fila para não explodir a concorrência enquanto “espera educadamente.”
Tudo isso para dizer: se o v4 espelhar os níveis do v3, estou esperando TPM apertado para contextos grandes, RPM razoável para uso interativo e penalidades rápidas para cargas de trabalho irregulares. Minha configuração assume que verei picos de 429 e 5xx durante períodos de pico e os trata como normais, não excepcionais.
Padrões do Lado do Cliente
Não estou esperando por um recurso oficial de cache do deepseek v4 para organizar meu lado. Estes são os padrões que coloquei na frente da API para poder plugar um cache do provedor mais tarde sem mudar meus hábitos.
Backoff Exponencial
Minha primeira tentativa usou um simples backoff exponencial (200ms, 400ms, 800ms, máximo em torno de 5–8s). Funcionou, mas pareceu irregular sob carga. O que ajudou:
- Adicionar jitter. Randomizo cada atraso um pouco (ex.: variância de 20–30%). Isso espalha as retentativas e evita tempestades de sincronização quando muitas chamadas falham ao mesmo tempo.
- Limitar retentativas. Três tentativas para leituras idempotentes ou prompts cacheados. Uma tentativa para interações claramente voltadas ao usuário, a menos que a UI espere um spinner. Se demorar mais de ~10 segundos para estabilizar, prefiro falhar graciosamente a deixar alguém esperando.
- Distinguir 429 de 5xx. Um 429 sugere que devo desacelerar toda a fila. Um 5xx sugere uma falha breve: vou retentar algumas vezes e depois abrir o circuit breaker (mais sobre isso abaixo).
Uma pequena observação: o backoff não me economizou tempo no início. O que ele fez, após algumas execuções, foi reduzir o esforço mental. Parei de ficar vigiando o terminal, o que no meu mundo vale tanto quanto velocidade.
Fila de Requisições
Concorrência é onde geralmente me meto em apuros. Adicionei uma fila simples do lado do cliente com estas regras:
- Concorrência fixa (começar com 2–4 workers para tarefas em segundo plano, 1–2 para ações disparadas pela UI). Só aumento depois de um período tranquilo.
- Agendamento por tokens. Se consigo estimar os tokens, agendar prompts pesados primeiro durante janelas calmas, depois preencher com chamadas leves. Mantém o TPM mais estável.
- Filas com prioridade. Ações do usuário podem preemptar jobs em lote. Se alguém está esperando, o sistema cede espaço.
Também cacheo as partes caras antes:
- Scaffolds de prompt. Se o prompt do sistema e as ferramentas raramente mudam, faço um hash deles e uso o hash como chave de cache. Se o v4 lançar um cache de contexto do lado do servidor, vou passar essa chave adiante: por enquanto é apenas minha própria tag.
- Contexto recuperado. Cacheo chunks de RAG por fingerprint de conteúdo. Se a fonte não mudou, reutilizo o mesmo bloco de contexto em vez de buscar e re-embedar novamente.
Não é glamoroso, mas reduziu meus erros 429 em jobs em segundo plano em cerca de 70% ao longo de uma semana. Não mais rápido, apenas mais estável.
Circuit Breaker
Não esperava precisar disso. Então, numa tarde, o serviço começou a lançar erros 5xx por alguns minutos e minha lógica de retentativa felizmente os amplificou. O circuit breaker corrigiu isso.
Minhas regras são simples:
- Abrir o circuito se a taxa de erro ultrapassar um limite (digamos, >30% das chamadas falhando numa janela de 60–90 segundos) ou se a latência saltar além do P95 por duas janelas consecutivas.
- Com o circuito aberto, curto-circuitar as chamadas e usar fallback: servir respostas cacheadas se disponíveis, degradar funcionalidades (contexto menor, prompts mais simples) ou mostrar uma mensagem discreta explicando a pausa.
- Half-open após um período de backoff. Deixar passar um fio de requisições e observar as métricas. Se se mantiverem, fechar o circuito.
O que me surpreendeu foi como a UI ficou muito mais calma. Um “estamos pausando por um minuto” limpo é melhor do que um spinner que gira para sempre.
Monitoramento e Alertas
 Não gosto de combater incêndios às cegas. Para algo como um cache do deepseek v4, os sinais úteis são pequenos e entediantes.
Não gosto de combater incêndios às cegas. Para algo como um cache do deepseek v4, os sinais úteis são pequenos e entediantes.
O que monitoro:
- Taxa de acertos do cache. Dividida por tipo: scaffold de prompt, contexto recuperado e reutilização de resposta completa. Se os acertos de resposta completa subirem acima de ~25% para um fluxo de trabalho, verifico os TTLs novamente — posso estar cacheando demais e perdendo contexto fresco.
- TPM/RPM efetivo. Não apenas os números do provedor, mas o que passa depois do enfileiramento. Se o RPM efetivo permanece estável enquanto a entrada cresce, a fila está fazendo seu trabalho.
- Distribuição de retentativas. Quantas chamadas têm sucesso na primeira tentativa versus segunda/terceira. Uma deriva em direção a retentativas posteriores significa que a pressão está aumentando em algum lugar.
- Faixas de latência. P50 me diz o caminho feliz; P95 me diz o que os usuários sentem num dia ruim. Alerto no P95.
- Taxonomia de erros. 429 vs 5xx vs timeouts. Cada um é resolvido com alavancas diferentes.
Alertas que não gritam:
- Latência P95 2x maior por 5 minutos. Me notifique apenas se persistir.
- Taxa de 429 acima de 5% por 10 minutos. Reduzir automaticamente a concorrência em um passo e estender a espera na fila; me avisar que aconteceu.
- Circuito aberto por mais de 3 minutos. Isso é um incidente real. Vou verificar o status do provedor e decidir se devo mudar de região ou pausar os jobs em lote.
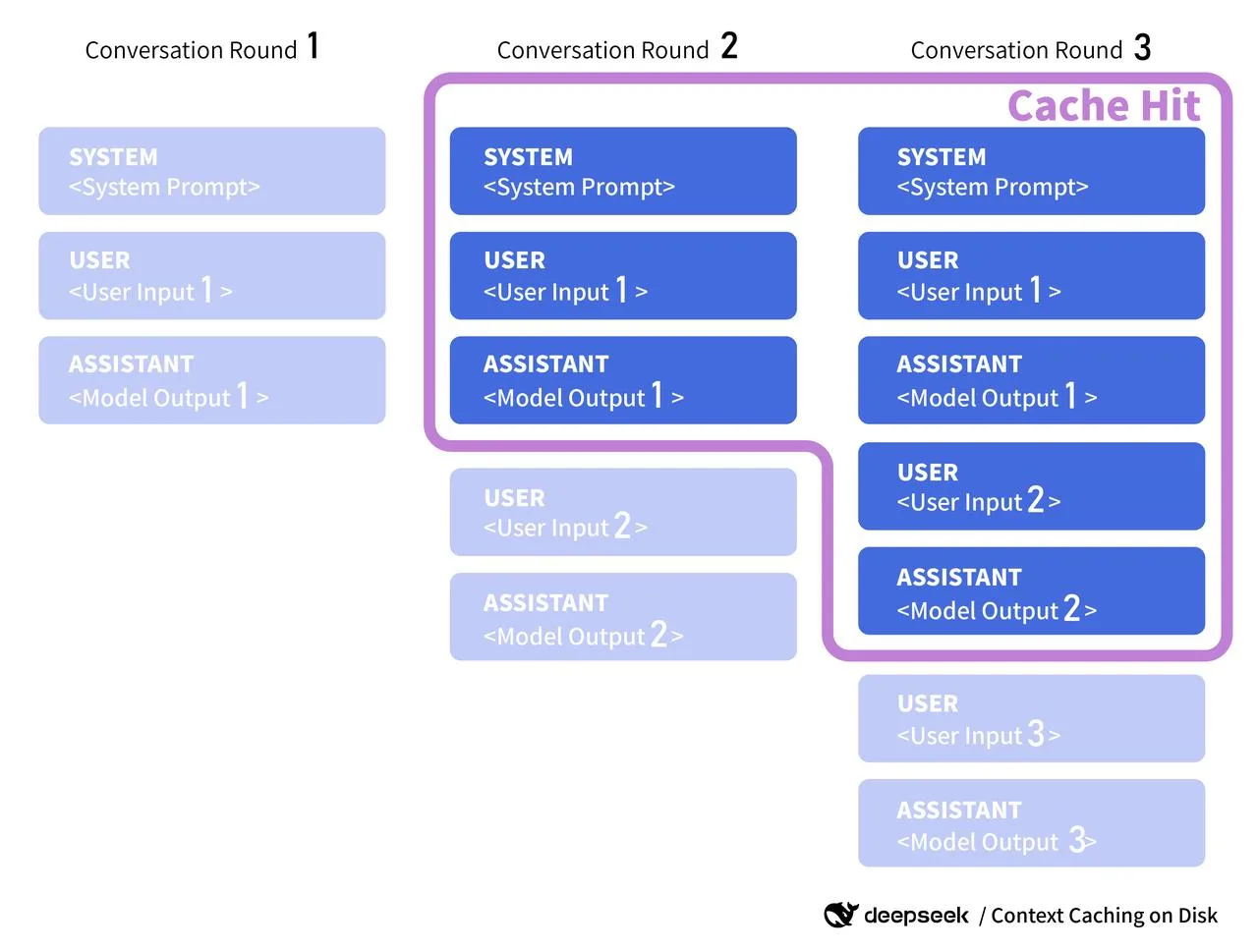 Uma palavra rápida sobre documentação oficial: quando a documentação do v4 chegar, vou procurar por qualquer coisa como cache de contexto do lado do servidor, chaves de cache ou tokens de reutilização. Alguns provedores expõem um cache_id que você pode anexar a um segmento de prefill compartilhado (pense: prompt de sistema longo). Se a DeepSeek fizer algo semelhante, vou alinhar minhas chaves de cliente com o formato deles e respeitar quaisquer regras de TTL ou invalidação que publiquem. Até lá, trato meu cache como consultivo: útil quando acerta, inofensivo quando erra.
Uma palavra rápida sobre documentação oficial: quando a documentação do v4 chegar, vou procurar por qualquer coisa como cache de contexto do lado do servidor, chaves de cache ou tokens de reutilização. Alguns provedores expõem um cache_id que você pode anexar a um segmento de prefill compartilhado (pense: prompt de sistema longo). Se a DeepSeek fizer algo semelhante, vou alinhar minhas chaves de cliente com o formato deles e respeitar quaisquer regras de TTL ou invalidação que publiquem. Até lá, trato meu cache como consultivo: útil quando acerta, inofensivo quando erra.
Para quem esse setup serve:
- Pessoas com prompts repetíveis e contexto que muda lentamente (docs, centrais de ajuda, bases de conhecimento). O cache brilha aqui.
- Equipes com jobs em lote durante a noite. A fila e o circuit breaker reduzem surpresas.
- Qualquer pessoa cansada de jitter. Não é mais rápido, mas é mais calmo.
Quem pode pular:
- Chats altamente dinâmicos e específicos do usuário onde frescor supera reutilização. Cachear scaffolds, com certeza, mas não respostas completas.
- Projetos com tráfego muito baixo. Se você está enviando algumas chamadas por dia, o overhead não vale a pena.
Se quiser se aprofundar nos mecanismos, eu começaria com a documentação do provedor para limites de requisições e qualquer menção de cache de contexto ou reutilização. Quando a DeepSeek publicar os detalhes do v4, vou atualizar meu setup para correspondê-los e linkar a documentação diretamente. Por enquanto, o sistema aguenta: menos chamadas desperdiçadas, backpressure mais claro e uma UI que parece saber quando pausar.
Tenho uma pequena anotação colada perto da minha tela: “Não lute contra a fila.” Não é profundo, mas em dias movimentados é suficiente para me impedir de tentar passar mais uma requisição por uma janela que está se fechando.
Perguntas Frequentes
Como os circuit breakers melhoram a confiabilidade com um cache do deepseek v4?
Um circuit breaker abre quando as taxas de erro disparam ou a latência P95 salta, curto-circuitando temporariamente as chamadas. Com o circuito aberto, sirva respostas cacheadas, degrade funcionalidades (contexto menor) ou pause graciosamente. Após um período de resfriamento, abra parcialmente com um fio de requisições para testar a recuperação. Isso evita que as retentativas amplifiquem interrupções e acalma a UI.
O DeepSeek v4 oferece cache de contexto do lado do servidor ou chaves de cache?
No início de 2026, os detalhes públicos do DeepSeek v4 são limitados. Alguns provedores suportam cache_id ou segmentos de prefill reutilizáveis. Planeje com antecedência fazendo hash de prompts de sistema e ferramentas estáveis no lado do cliente. Se a DeepSeek expuser chaves de cache do lado do servidor mais tarde, alinhe seus hashes e respeite quaisquer regras de TTL/invalidação que publicarem.
Quais TTLs e regras de invalidação devo usar para cache de LLM?
Use TTLs curtos (5–30 minutos) para reutilização de resposta completa em verificações de saúde ou templates, e TTLs mais longos (horas–dias) para scaffolds estáveis e contexto recuperado vinculado a fingerprints de conteúdo. Invalide em atualizações de fonte, mudanças de modelo/versão ou edições no schema do prompt. Monitore as taxas de acerto; acertos de resposta completa >25% podem indicar excesso de cache.
Artigos relacionados
Apresentando o ByteDance Seedance 2.0 Mini no WaveSpeedAI

Claude Fable 5 com Fallback para Opus 4.8 Explicado
API do GLM-5.2: Preços, Contexto de 1M e Roteamento em Produção
Preços do GPT-5.4 Mini: Custo de Entrada, Cache e Saída
API MAI-Image-2.5: O Que os Desenvolvedores Precisam Saber