HappyHorse-1.0이 갑자기 비디오 리더보드 1위에 오른 이유는?
HappyHorse-1.0은 공개된 팀도 없이 Artificial Analysis에서 1위를 차지했습니다. Elo가 브랜드보다 영상 품질을 어떻게 평가하는지, 그리고 개발자들에게 그 의미가 무엇인지 알아보세요.

안녕하세요, 여러분. Dora입니다. 이번 주 제 피드에서 누군가가 “HappyHorse가 대체 뭐야?”라는 질문을 몇 번이나 했는지 세어봤습니다. 여섯 번입니다. 여섯 개의 별개 스레드. 그리고 각각에는 약간씩 다른 소문이 붙어 있었습니다 — WAN 2.7이라느니, ByteDance의 스텔스 출시라느니, Alibaba에서 나온 거라느니. 아무도 확실히 모릅니다. 모두가 동의하는 것은 딱 하나: 2026년 4월 7~8일경 Artificial Analysis 동영상 리더보드에 등장해 텍스트-투-비디오와 이미지-투-비디오 모두에서 즉시 1위를 차지했다는 겁니다.
그것이 사실입니다. 그 이후의 모든 것 — 누가 만들었는지, 언제 가중치가 공개되는지, 1위를 유지할지 — 은 아직 미결입니다.
이 글은 리더보드가 실제로 무엇을 측정하는지, 왜 알려지지 않은 모델이 정당하게 최상위에 오를 수 있는지, 그리고 개발자로서 그 정보를 가지고 무엇을 해야 하고 하지 말아야 하는지에 대한 이야기입니다.
Artificial Analysis 비디오 아레나의 작동 방식
순위를 신뢰하기 전에 그 순위가 무엇을 측정하는지 이해해야 합니다. Artificial Analysis 비디오 아레나는 모델 개발자가 자신의 점수를 제출하는 벤치마크가 아닙니다 — 블라인드 사용자 투표 시스템입니다.
사용자가 보는 것(과 보지 못하는 것)
아레나에 접속하면 동일한 텍스트 프롬프트나 입력 이미지에서 생성된 두 개의 영상이 표시되고, 어느 것이 더 마음에 드는지 선택합니다. 어떤 모델이 어떤 영상을 만들었는지 알 수 없습니다. 라벨 없음. 맥락 없음. 그냥 두 클립뿐입니다.
Artificial Analysis가 직접 이렇게 설명합니다: “사용자들은 어떤 모델이 각 영상을 만들었는지 모르는 상태에서 동일한 텍스트 프롬프트로 생성된 두 영상을 비교합니다.” 그게 핵심입니다. 자체 보고 없음, 개발자가 제공한 벤치마크 없음, 결과에 영향을 미치는 마케팅 페이지 없음.
Elo: 신뢰할 수 있는 신호, 하지만 완벽하지는 않음
이 순위는 Elo 시스템을 사용합니다 — 경쟁 체스에서 빌려온 것과 동일한 방식입니다. 두 모델이 투표에서 맞붙을 때마다 승자는 Elo 포인트를 얻고 패자는 잃습니다. Elo가 높은 모델은 다른 모델과의 대결에서 꾸준히 더 많이 이겨왔다는 뜻입니다.
Elo 점수가 높을수록 더 자주 선호된다는 의미입니다. 그건 실제 신호입니다. 합성 테스트도, 선별된 예시도, 모델 카드도 아닌 수천 명의 실제 인간 선택을 기반으로 합니다.
투표 수와 표본 크기: 사람들이 건너뛰는 부분
신규 참가자에 대한 Elo의 특성이 있습니다. Seedance 2.0 같은 확립된 모델은 점수 뒤에 수천 개의 투표가 쌓여 있습니다 — Seedance 2.0은 T2V 카테고리에서 7,500개 이상의 투표 샘플을 보유합니다. HappyHorse의 샘플 수는 아직 공개적으로 분리되어 있지 않습니다. 투표가 많을수록 점수가 더 안정적입니다. 대결 횟수가 적은 신규 모델은 새로운 투표 하나하나에 더 크게 흔들릴 수 있습니다.

더 많은 투표가 들어오면 이 수치들은 바뀔 것입니다. 그 변화의 방향은 알 수 없습니다. 이틀 된 숫자를 기반으로 파이프라인 결정을 내리기 전에 그 점을 명심하세요.
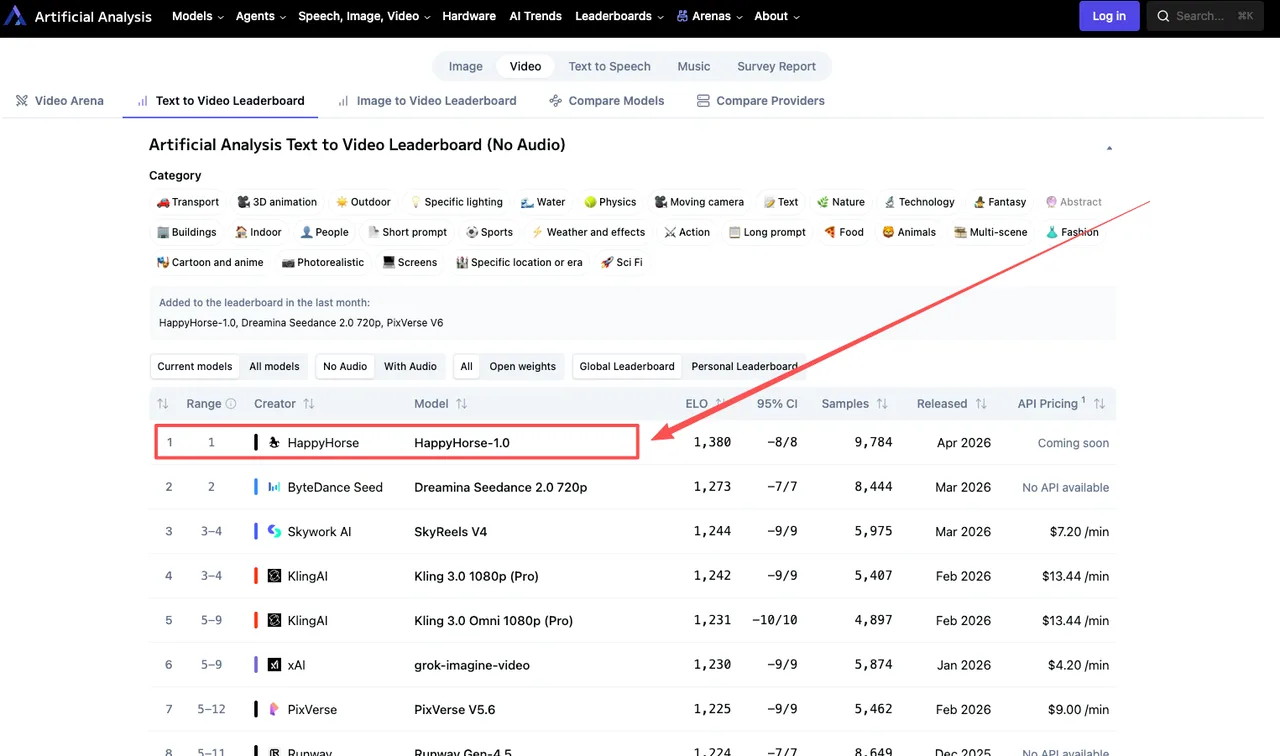
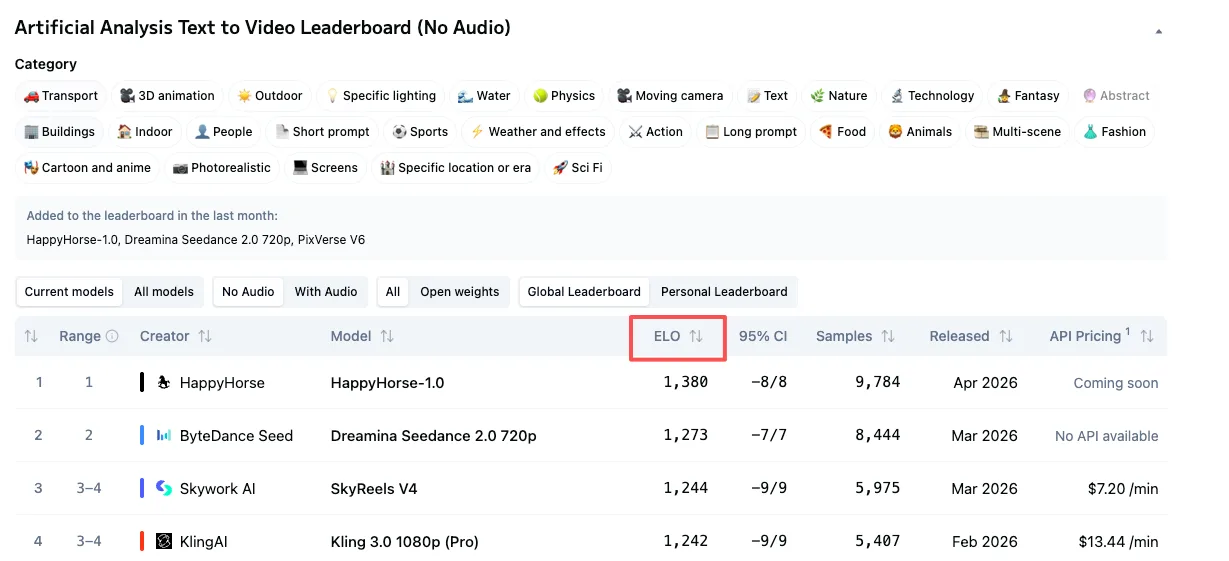
HappyHorse-1.0이 실제로 기록하는 점수
2026년 4월 초 기준 라이브 리더보드에서 가져온 현재 수치:
T2V (오디오 없음): HappyHorse-1.0이 Elo 점수 1357로 선두, Dreamina Seedance 2.0의 1273, SkyReels V4의 1244, Kling 3.0 Pro의 1243 앞에 있습니다.
I2V (오디오 없음): HappyHorse-1.0이 Elo 1402로 선두, Seedance 2.0은 1355, Grok Imagine Video는 1331입니다.
오디오 없는 I2V에서 84포인트 차이는 작지 않습니다. 60포인트 Elo 차이는 한 모델이 블라인드 대결의 약 58~59%를 이긴다는 의미 — 유의미합니다. 80포인트 이상의 차이는 더욱 강합니다.
오디오에서는 역전
오디오가 있는 이미지-투-비디오에서 HappyHorse-1.0은 현재 Elo 점수 1160으로 선두이고, Dreamina Seedance 2.0은 1158입니다. 2포인트 차이는 통계적 노이즈입니다. 그리고 오디오가 있는 T2V에서는 Seedance 2.0이 1220으로 선두이고 HappyHorse는 1215입니다.
따라서 “HappyHorse가 모든 곳에서 1위”라는 것보다 더 미묘한 그림입니다. 오디오를 제외했을 때 상당한 차이로 1위입니다. 오디오 품질이 방정식에 들어오면 Seedance 2.0과 사실상 동점입니다.
아키텍처 주장이 말하는 것(과 증명하지 못하는 것)
HappyHorse를 설명하는 여러 사이트들은 단일 스트림 트랜스포머 아키텍처에 약 150억 개의 파라미터를 갖추고, 단일 H100에서 1080p 클립 생성 속도가 약 38초라고 주장합니다. 2026년 4월 8일 기준으로, 이 HappyHorse 사이트들의 GitHub 및 HuggingFace 링크는 “coming soon” 페이지를 가리키거나 404 오류를 반환합니다. 가중치는 공개적으로 다운로드할 수 없습니다.
이러한 아키텍처 주장은 그럴듯하지만 검증되지 않았습니다. 파라미터 수, 아키텍처 유형, 추론 속도를 확인한 독립적인 기술 감사는 없습니다. 확인된 것이 아니라 주장으로 취급하세요.
알려지지 않은 모델이 Elo에서 이길 수 있는 이유
이것이 리더보드가 브랜드 인지도에 보상한다고 가정하는 사람들을 혼란스럽게 하는 부분입니다.
Elo는 누가 모델을 만들었는지 신경 쓰지 않습니다. Google인지 세 명짜리 연구소인지 알지 못합니다. Artificial Analysis의 비디오 아레나는 Elo 평점 시스템을 사용하며 실제 사용자 블라인드 투표에 전적으로 의존합니다. 파라미터, 논문, 또는 과대 광고는 무시합니다 — 오직 하나의 질문만 신경 씁니다: “둘 다 보고 나서 어느 영상이 더 좋았나요?”
그건 실제로 장점입니다. 자금이 풍부한 브랜드가 유리한 논문을 발표함으로써 더 좋은 결과를 살 수 없는 몇 안 되는 평가 시스템 중 하나입니다.
이 패턴은 전에도 있었습니다
익명 사전 출시 배포는 중국 AI 생태계에서 하나의 패턴이 되었습니다. 2026년 2월의 Pony Alpha 상황이 가장 명확한 선례입니다 — 미스터리 모델이 OpenRouter에 나타나 추측 게임을 촉발했고, Z.ai의 GLM-5가 스텔스 스트레스 테스트를 하는 것으로 밝혀졌습니다. HappyHorse는 이 템플릿에 맞습니다: 알 수 없는 이름, 출시 시 팀 귀속 없음, “coming soon” GitHub 링크가 있는 랜딩 페이지, 강력한 출력물.
주요 연구소가 조용한 역량 확인을 하는 것인지 진정한 새 팀인지 — 아직 미결입니다. 하지만 Elo 점수 자체는 그에 관계없이 실제입니다.
Elo가 숨길 수 없는 한계
Elo는 한 가지를 측정합니다: 블라인드 비교에서 실제 사용자가 어느 영상을 선호했는지. 모델이 배치 실행에서 어떻게 수행되는지는 측정하지 않습니다. API 가동 시간, 부하 시 지연, 또는 아레나 예시를 선별할 때 대 대규모 생성 시 출력 품질 유지 여부를 측정하지 않습니다.
모델은 블라인드 테스트 결과가 훌륭하면서도 프로덕션에서 완전히 사용 불가능할 수 있습니다. 이는 별개의 질문들입니다.
”리더보드 1위”가 개발자에게 의미하지 않는 것
HappyHorse의 현재 순위를 기반으로 도구 결정을 내리려 한다면 여기서 천천히 생각해보세요.
API 없음, 프로덕션 접근 없음
HappyHorse를 “리더보드 항목”에서 “실제 옵션”으로 만들 세 가지 조건: 실제 가중치와 추론 코드가 있는 GitHub 저장소, 검증 가능한 세부 정보와 라이선스가 있는 HuggingFace 모델 카드, 또는 문서화된 가격이 있는 API 엔드포인트. 이 글을 쓰는 시점에서 아무것도 존재하지 않습니다.
호출할 수 없다면 사용할 수 없습니다. 리더보드 위치는 출력 품질에 대한 정보이지 가용성에 대한 것이 아닙니다.
오디오 성능이 계산을 바꿉니다
워크플로에 오디오가 필요한 경우 — 보이스오버, 주변 소리, 립싱크 — HappyHorse의 우위는 사실상 사라집니다. 오디오 포함 카테고리에서 HappyHorse와 Seedance 2.0 사이의 차이는 T2V에서 5포인트, I2V에서 2포인트입니다. 이는 정상적인 Elo 변동 내의 동점입니다.
오디오가 필요한 사용 사례의 경우, 현재 실질적인 분야는 상위에서 Seedance/HappyHorse 동점처럼 보이며, SkyReels V4는 의미 있는 한 단계 아래에 있습니다.
팀 책임: 알 수 없음
Artificial Analysis는 모델을 아레나에 추가할 때 HappyHorse를 “익명”으로 설명했습니다. 모델과 연결된 한 사이트 세트는 Kling AI의 전 수장인 Zhang Di가 이끄는 Taotian Group(Alibaba)의 Future Life Lab 팀이 만들었다고 주장합니다. 또 다른 분석은 거의 동일한 사양을 공유하는 Sand.ai 오픈 소스 프로젝트인 daVinci-MagiHuman과 연결했습니다. 둘 다 공식적으로 확인되지 않았습니다.
프로덕션 도구의 경우, 팀 책임은 버그 수정, 모델 업데이트, 장기 지원에 있어 중요합니다. 익명 모델의 경우 그런 명확성이 없습니다.
개발자로서 비디오 리더보드를 읽는 방법
추상적인 이야기가 아닌 구체적인 프레임워크입니다.
Elo를 품질 신호로 사용하되, 조달 결정으로 사용하지 마세요. 모델이 자금이 풍부한 경쟁자들과의 블라인드 비교에서 꾸준히 이기고 있다면, 그것은 생산하는 것에 대해 실제적인 무언가를 말해줍니다. 주목할 가치가 있습니다. API 조건, 가격, 지연, 또는 팀이 버그 보고에 응답하는지에 대해서는 아무것도 말해주지 않습니다.
실질적인 리더보드는 3위부터 시작합니다. Elo 기준으로 가장 높은 품질의 두 모델 — HappyHorse와 Seedance 2.0 — 은 공개 API를 통해 접근할 수 없습니다. 다음 계층 — SkyReels V4, Kling 3.0, PixVerse V6 — 이 현재 실제 통합 결정이 이루어지는 곳입니다.
새로운 리더보드 진입자에 대해 언제 조기에 행동할지. 모델이 의미 있는 Elo 차이로 상위에 있고, 검증된 GitHub 릴리스가 있으며, 문서가 존재한다면 — 즉시 테스트할 가치가 있습니다. 상위에 있지만 GitHub에 “coming soon”이라고 나온다면 — 2주 후에 확인하도록 알림을 설정하세요. 허상 주변에 파이프라인을 재구성하지 마세요.
라이브 리더보드를 기사가 아닌 직접 확인하세요. 이 기사 포함. Elo 점수는 매일 변합니다. 여기서 참조한 수치는 2026년 4월 초를 반영하며 읽는 시점에는 이미 바뀌었을 것입니다.
FAQ
HappyHorse-1.0이 Artificial Analysis 리더보드에 얼마나 됐나요?
Artificial Analysis가 2026년 4월 7일에 새로 추가된 익명 모델로 발표했습니다. 이 글을 쓰는 시점에서 약 48시간 동안 라이브 상태였으며 투표 수가 여전히 쌓이고 있습니다.
모델이 Elo 1위를 무기한 유지할 수 있나요?
보통은 그렇지 않습니다. 더 새로운 모델들이 아레나에 진입하고 더 많은 투표가 모이면 순위가 바뀝니다. 적은 샘플로 이틀째 지배하는 모델은 투표 풀이 깊어짐에 따라 더 낮게 안정화될 수 있습니다. 점수는 항상 라이브입니다 — 영구적인 판단이 아닌 현재 데이터를 반영합니다.
Artificial Analysis가 아레나에 모델을 제출하는 사람을 검증하나요?
Artificial Analysis는 모델 제출에 대한 공식 검증 정책을 발표하지 않았습니다. 모델을 발표할 때 HappyHorse-1.0을 “익명”으로 설명했는데, 이는 팀의 신원을 알고 있지만 공개적으로 공개하지 않는다는 것을 시사합니다. 제출된 모델에 대한 기술적 감사를 수행하는지 여부는 문서화되어 있지 않습니다.
Elo 점수만으로 모델을 선택해야 하나요?
아니요. Elo는 블라인드 비교에서 시각적 선호도에 대해 알려줍니다. API 가용성, 생성당 비용, 지연, 가동 시간, 콘텐츠 정책, 또는 3개월 후에도 모델이 존재할지에 대해서는 아무것도 말해주지 않습니다. 여러 신호 중 하나입니다.
리더보드 순위와 함께 어떤 다른 지표가 중요한가요?
API 접근 및 문서; 생성당 또는 분당 가격; 사용 빈도에서의 지연 및 콜드 스타트 동작; Elo 점수 뒤의 샘플 수(투표가 많을수록 더 안정적); 그리고 팀이 모델을 유지하고 업데이트하는 실적이 있는지. WaveSpeed 모델 비교 페이지는 시작점을 원한다면 접근 가능한 모델들에 대한 이러한 차원 중 몇 가지를 추적합니다.
현재 상황은 이렇습니다. 알려지지 않은 팀과 공개 가중치가 없는 모델이 가장 신뢰할 수 있는 비디오 벤치마크에서 무시하기 어려운 차이로 1위를 차지했습니다. 실제 프로덕션 옵션이 될지는 향후 몇 주 안에 무엇이 출시되느냐에 달려 있습니다.
지켜볼 가치는 있습니다. 아직 행동할 가치는 없습니다.
더 많은 내용이 올 예정입니다.
WaveSpeedAI에서 HappyHorse-1.0 사용해보기
HappyHorse-1.0이 이제 WaveSpeedAI에서 사용 가능합니다:
이전 게시물:


