SkyReels V4란 무엇인가? 최초의 통합 비디오-오디오 AI 모델 설명
SkyReels V4는 비디오와 오디오를 동시에 생성하는 최초의 오픈소스 AI입니다 — 1080p/32FPS로. 무엇을 하는지, 어떻게 작동하는지, 왜 중요한지 알아보세요.

안녕하세요, 저는 Dora입니다. 그날 처음으로 **SkyReels V4** 영상을 생성했습니다. 황혼 무렵 빗물에 젖은 골목을 걷는 고양이를 담은 15초짜리 영상이었습니다. 영상은 훌륭했습니다 — 1080p, 부드러운 움직임, 멋진 조명. 하지만 저를 멈추게 한 건 오디오였습니다. 웅덩이를 첨벙거리는 발소리. 멀리서 들려오는 교통 소음. 골목 벽에 은은하게 울리는 메아리. 오디오 편집 툴 하나 건드리지 않고, 완벽하게 동기화된 채로 모두 함께 생성되었습니다.
그게 달랐습니다.
V4 이전 모든 영상 AI 툴이 가졌던 문제
영상만 생성하는 방식이 늘 불완전하게 느껴졌던 이유
대부분의 영상 AI 툴은 무음 클립을 생성합니다. Runway, Pika, 심지어 이전 버전의 SkyReels도 — 비주얼만 만들고 거기서 멈춥니다. 해변에 파도가 밀려오는 아름다운 10초짜리 장면을 얻지만, 완전히 무음입니다. 파도 소리가 없습니다. 바람 소리도 없습니다. 주변 소리가 전혀 없습니다.
이건 기술적 실수가 아닙니다. 영상과 동기화된 오디오를 함께 생성하는 건 진짜 어려운 일입니다. 오디오는 전반적인 장면뿐 아니라 특정 시각적 사건에도 맞아야 합니다 — 발이 땅에 닿을 때 발소리가 나고, 문이 닫힐 때 문 닫히는 소리가 나고, 목소리가 입술 움직임에 맞아야 합니다.
”나중에 오디오 추가” 병목 현상
표준 워크플로우는 이렇게 됐습니다: 영상 생성, 내보내기, 오디오 편집기 열기, 효과음이나 음악 수동 추가, 일일이 손으로 동기화, 다시 내보내기. 15초짜리 클립 하나에 이 과정이 20~30분씩 걸렸습니다.
지난달 Pika 결과물로 이 과정을 직접 해봤습니다. 영상은 전문적으로 보였습니다. 하지만 적절한 주변 소리를 찾고, 시각적 단서에 맞게 타이밍을 맞추고, “나중에 얹은 티”가 나지 않도록 하는 데 영상 생성 자체보다 더 많은 시간이 걸렸습니다. 마치 자동차를 샀는데 엔진은 따로 설치해야 하는 것처럼, 워크플로우가 망가진 느낌이었습니다.
SkyReels V4가 실제로 무엇인가
SkyworkAI가 만든 모델 (V1/V2/V3 계보 설명)
SkyworkAI는 2025년 초 기본 텍스트-투-비디오 모델인 SkyReels V1을 출시했습니다. V2는 자기회귀 시퀀스를 통한 무한 길이 생성을 가능하게 하는 디퓨전 포싱 아키텍처를 도입했습니다. V3는 2026년 1월에 출시되어 멀티모달 인컨텍스트 학습을 선보였습니다 — 참조 이미지, 오디오 클립, 기존 영상을 입력하면 일관된 연속 콘텐츠를 생성했습니다.

2026년 2월 25일에 공개된 V4는 다른 종류의 도약을 보여줍니다. V3가 기능을 추가했다면, V4는 영상과 오디오를 동시에 생성하는 듀얼 스트림 시스템을 중심으로 전체 아키텍처를 재구성했습니다.
”통합 비디오-오디오 파운데이션 모델”이 실제로 의미하는 것
기술 논문에서는 V4가 두 개의 병렬 브랜치를 가진 멀티모달 디퓨전 트랜스포머(MMDiT)를 사용한다고 설명합니다. 하나의 브랜치는 영상 프레임을 합성하고, 다른 브랜치는 시간적으로 정렬된 오디오를 생성합니다. 두 브랜치는 멀티모달 대규모 언어 모델 기반의 텍스트 인코더를 공유하며, 이를 통해 프롬프트에 대한 동일한 의미론적 이해를 처리하고 생성 전반에 걸쳐 동기화를 유지합니다.
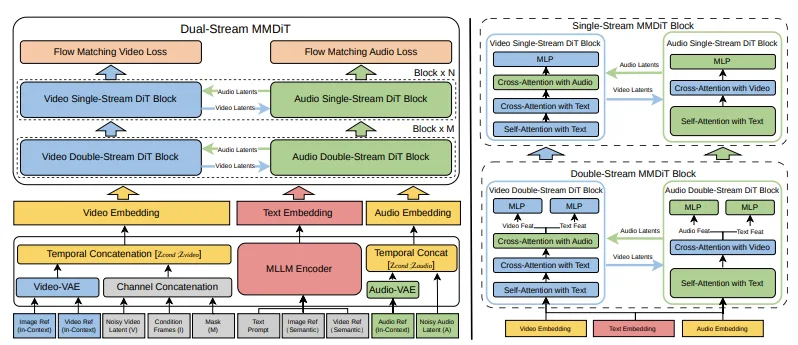
이건 영상 생성에 오디오를 끼워 넣은 것이 아닙니다. 시각과 청각을 동등하게 중요한 출력으로 다루며, 장면에 대한 동일한 잠재적 이해로부터 함께 생성하는 단일 모델입니다.
실제로는, “연단에서 연설하는 여성”을 프롬프트로 입력하면 모델이 입술이 움직이는 시각적 영상과 실제 음성 오디오를 프레임 단위로 동기화하여 생성합니다. “금속 지붕 위의 폭우”를 생성하면, 빗줄기가 흘러내리는 시각적 효과와 함께 특유의 금속성 북소리 같은 빗소리가 — 대략 맞춰진 것이 아니라 — 통합된 시청각 이벤트로 생성됩니다.
주요 기능 한눈에 보기
하나의 프롬프트로 영상 + 오디오 동시 생성
단일 프롬프트 생성이 핵심 기능입니다. “사막 풍경을 가로질러 울려 퍼지는 천둥”을 입력하면 V4는 구름이 모이고 번개가 번쩍이며, 시각적 타이밍에 맞는 천둥 소리가 울리는 15초짜리 영상을 만들어냅니다. 별도의 오디오 생성 단계도 없고, 수동 동기화 작업도 없습니다.
대화 장면으로 테스트해봤습니다. “북적이는 카페에서 말다툼하는 두 사람”을 프롬프트로 입력했더니 대화 영상뿐 아니라 배경 소음, 그릇 부딪히는 소리, 몸짓의 강도에 따라 높낮이가 바뀌는 목소리까지 담겼습니다. 립싱크가 완벽하지는 않았습니다 — 타이밍이 약간 어긋나는 순간이 몇 번 있었습니다 — 하지만 제가 수동으로 동기화한 어떤 결과물보다도 나았습니다.
1080p / 32FPS / 15초 출력
기술 사양: 최대 1080p 해상도, 초당 32프레임, 최대 15초 길이. 참고로, 대부분의 경쟁 툴은 720p가 최대이거나 HD 출력을 위해 훨씬 더 긴 생성 시간이 필요합니다.
15초 제한은 들리는 것보다 중요합니다. 대부분의 소셜 미디어 콘텐츠는 10~15초 단위로 소비됩니다. YouTube Shorts는 최대 60초, Instagram Reels는 90초입니다. 그 용도로는, 후반 작업이 필요한 30초짜리 무음 영상보다 동기화된 오디오가 포함된 15초짜리 영상이 훨씬 실용적입니다.
멀티모달 입력: 텍스트, 이미지, 영상, 마스크, 오디오 레퍼런스
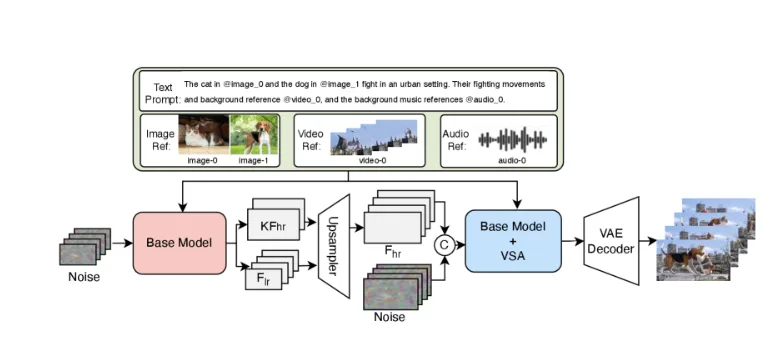
V4는 다섯 가지 입력 유형을 지원합니다: 텍스트 프롬프트, 참조 이미지, 영상 클립, 인페인팅용 바이너리 마스크, 그리고 오디오 레퍼런스. 이들을 조합할 수 있습니다 — 특정 인물의 이미지를 업로드하고, 자갈 위 발소리 오디오 샘플을 제공한 뒤 “새벽 숲 속을 걷기”를 프롬프트로 입력합니다. 모델은 세 가지 입력을 모두 활용해 생성을 유도합니다.
특정 건축 양식의 참조 이미지와 거리 분위기 오디오 클립을 조합한 멀티모달 프롬프팅을 테스트했습니다. 생성된 영상은 이미지의 건축적 세부 사항을 유지하면서 오디오 레퍼런스의 주변 소리를 레이어로 입혔습니다. 완벽하지는 않았습니다 — 일부 오디오 요소가 일반적으로 느껴졌습니다 — 하지만 기능 자체는 작동했습니다.
하나로 세 가지: 생성, 인페인팅, 편집
생성 외에도, V4는 채널 연결을 통해 인페인팅과 편집을 처리합니다. 영상과 수정할 영역을 나타내는 마스크를 제공하면, 모델은 나머지는 보존하면서 해당 영역만 재생성합니다. 이를 통해 전체 클립을 다시 생성하지 않고도 오브젝트 제거, 배경 변경, 특정 요소 교체 같은 작업이 가능합니다.
V4와 이전 버전 비교
V4 vs SkyReels V1/V2/V3 발전 과정
V1은 텍스트-투-비디오만 가능했습니다. V2는 디퓨전 포싱으로 길이를 추가했습니다. V3는 멀티모달 입력을 도입했지만 여전히 네이티브 오디오 없이 영상만 생성했습니다. V4는 최초로 오디오를 영상과 동시에 생성되는 일급 출력으로 다룹니다.
SkyReels V4에 주목해야 할 사람은?

콘텐츠 크리에이터와 영화 제작자
소셜 플랫폼용 숏폼 콘텐츠를 제작하는 누구에게나 즉각적인 혜택이 있습니다. 워크플로우 단축 — 프롬프트에서 완성된 시청각 클립까지 — 은 AI 영상 툴이 오히려 더 많은 작업을 만들어낸다고 느끼게 했던 병목을 제거합니다.
영화 제작자 친구가 V4로 다큐멘터리용 B-롤을 생성하는 것을 지켜봤습니다. “황혼에 도시 불빛이 켜지는 타임랩스”나 “창문 유리 위의 빗물 클로즈업” 같은 프롬프트에 적절한 주변 소리를 더해서요. 결과물이 실제 영상과 구별 불가능한 수준은 아니었지만, 배경 컷으로 쓰기엔 충분히 좋았고, 로케이션 촬영이나 스톡 영상 라이선스 없이 각각 60초 이내에 준비됐습니다.
영상 파이프라인을 구축하는 개발자
영상을 생성하거나 가공하는 애플리케이션을 만든다면, V4의 생성, 인페인팅, 편집을 위한 통합 인터페이스가 스택을 단순화합니다. 영상 생성, 오디오 합성, 동기화 보정을 위한 별도 모델을 체이닝하는 대신, 하나의 API 호출로 전체 흐름을 처리합니다.
모델 아키텍처는 상세하게 문서화되어 있으며, SkyworkAI는 이전 버전을 오픈소스로 공개한 이력이 있어 개발자 접근성이 확대될 것으로 예상됩니다. V3 가중치는 이미 Hugging Face와 GitHub에서 이용 가능합니다.
현재 접근 상태 및 향후 전망
2026년 3월 2일 기준, V4는 제한된 프리뷰 단계입니다. 공식 사이트에서 일일 생성 제한이 있는 무료 티어를 제공하지만, 아직 API 접근은 불가합니다. 논문 공개에서 공개 API까지 약 2주가 걸렸던 V3의 일정을 감안하면, 3월 중순쯤에는 더 넓은 이용이 가능해질 것으로 예상합니다.
기술 논문은 향후 작업으로 15초 이상으로 확장하고 세밀한 오디오 제어를 개선하는 내용을 언급합니다. 특히 시간 제한은 지금 당장 상당히 느껴지는 제약입니다. 하지만 V4가 해결하는 특정 문제 — 후반 작업 없이 짧고 동기화된 시청각 클립 생성 — 에 있어서는, 제가 테스트한 그 어떤 것보다 잘 작동합니다.
첫 테스트 이후 V4를 워크플로우에 계속 사용하고 있습니다. 모든 작업에 쓰지는 않습니다 — 촬영 영상이나 스톡 비디오가 더 적합한 경우도 여전히 있습니다. 하지만 빠른 B-롤, 주변 분위기 장면, 동기화된 오디오가 중요한 소셜 미디어 스니펫의 경우, V4가 충분한 마찰을 제거해줘서 이제는 가장 먼저 손이 갑니다.
통합 아키텍처는 점진적인 기능 추가처럼 느껴지기보다는, 처음부터 이렇게 작동했어야 했던 무언가를 고친 것처럼 느껴집니다.





