HappyHorse-1.0 vs Seedance 2.0: 지금 당장 어떤 모델이 앞서나?
HappyHorse-1.0은 오디오 없는 T2V 및 I2V에서 Seedance 2.0을 앞서지만, 오디오 지원과 안정적인 API는 부족합니다. 빌더들에게 이것이 의미하는 바를 알아보세요.

나는 Artificial Analysis Video Arena 리더보드를 새로고침하며 많은 시간을 보냈다. 안녕하세요, Dora입니다! 한 번도 들어본 적 없는 모델 — HappyHorse-1.0 — 이 주말 사이 조용히 등장해서 4개의 주요 랭킹 중 2개에서 Seedance 2.0을 1위에서 밀어냈다. 누가 만들었는지 아무도 모르는 것 같았다. Artificial Analysis 자체도 이를 “익명” 참가작이라고 불렀다. 내 타임라인은 절반은 흥분, 절반은 혼란으로 가득 찼다.
그래서 나는 수치를 뽑고, 접근 경로를 추적하고, 지금 이 모델들로 개발하는 사람이라면 실제로 중요한 단 하나의 질문을 파악하려 했다: 오늘 당장 출시할 수 있는 건 어느 것인가?
답은 리더보드가 보여주는 것만큼 깔끔하지 않다.
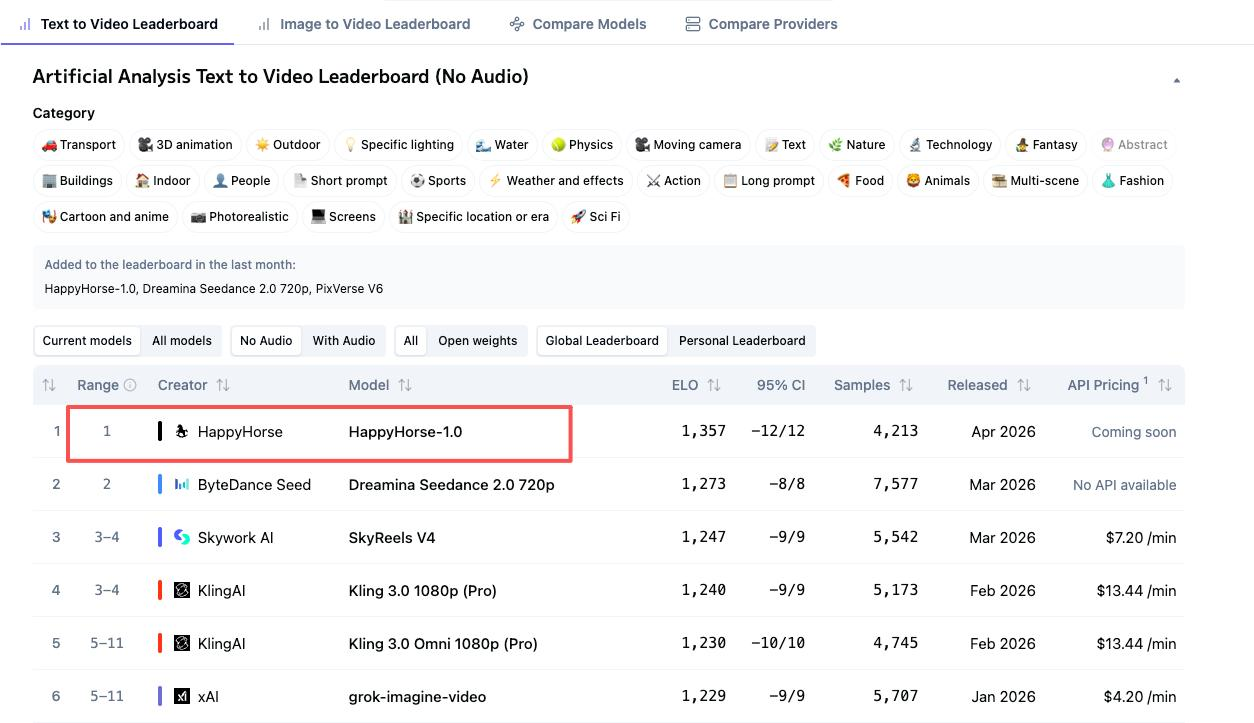
중요한 4가지 리더보드 수치
HappyHorse와 Seedance 2.0은 Artificial Analysis의 4개 별도 랭킹 상위에 위치한다. 하지만 오디오가 평가에 포함되는지 여부에 따라 순위가 바뀐다. 이 차이는 대부분의 비교에서 인정하는 것보다 훨씬 중요하다.
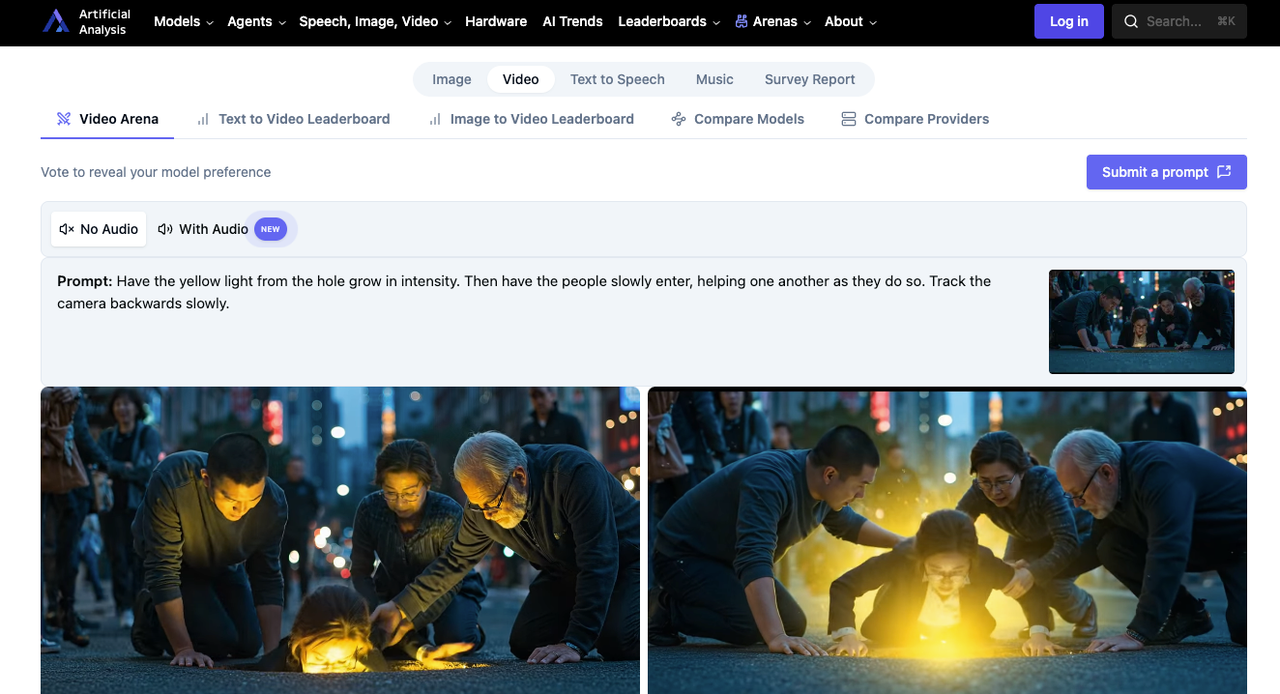
오디오 없는 T2V: HappyHorse 1위 (Elo 1333) vs Seedance 2.0 2위 (Elo 1273)
이것이 HappyHorse의 가장 강력한 결과다. 블라인드 투표 아레나에서 60점 Elo 격차는 의미 있다 — 대략 1대1 대결에서 사용자가 59% 정도의 확률로 HappyHorse의 결과물을 선호한다는 뜻이다. 여기서의 투표는 오디오가 인식에 영향을 미치지 않는 상태에서 시각적 동작 품질, 프롬프트 준수도, 장면 일관성을 포착하고 있다.
오디오 있는 T2V: Seedance 2.0 1위 (Elo 1219) vs HappyHorse 2위 (Elo 1205)
오디오가 개입되면 Seedance가 14점 차로 앞서간다. ByteDance의 듀얼 브랜치 디퓨전 트랜스포머는 단일 패스에서 영상과 오디오를 동시에 생성한다 — 영상 프레임을 위한 브랜치 하나, 오디오 파형을 위한 브랜치 하나, 크로스 어텐션으로 연결. 동기화된 음향 효과와 대화가 판단 기준이 될 때 이 아키텍처 선택이 효과를 발휘한다.
오디오 없는 I2V: HappyHorse 1위 (Elo 1392) vs Seedance 2.0 2위 (Elo 1355)
4개 카테고리 전체에서 HappyHorse의 최고 Elo다. 오디오 없는 이미지-투-비디오에서 37점 차는 이 모델이 참조 이미지 구성을 따르는 데 특히 강하다는 것을 시사한다 — 모션을 생성하면서 피사체 정체성, 프레이밍, 시각적 스타일을 일관되게 유지한다. 제품 애니메이션이나 컨셉-투-모션 작업을 하는 팀에게는 이 수치가 핵심이다.
오디오 있는 I2V: Seedance 2.0 1위 (Elo 1162) vs HappyHorse 2위 (Elo 1161) — 거의 동률
1점 차이. 이건 어떤 합리적인 오차 범위 내에 있다. 어느 모델도 실질적인 우위가 없다. 훨씬 더 많은 투표가 쌓일 때까지 이 카테고리는 무승부로 취급하라.
Elo가 실제로 측정하는 것 — 그리고 프로덕션 결정에서의 한계
이 Elo 점수는 Bradley-Terry 모델을 체스 랭킹에서 적용한 방식으로 블라인드 사용자 투표에서 나온다. 사용자는 동일한 프롬프트에서 익명으로 생성된 두 영상을 보고 더 선호하는 것을 선택한다. 이것이 우리가 가진 대규모 “감각 검사”에 가장 가까운 것이다.
하지만 Elo는 API 신뢰성, 생성 속도, 클립당 비용, 접근 안정성, 또는 실제로 모델을 프로그래밍 방식으로 호출할 수 있는지를 측정하지 않는다. 리더보드 순위는 품질 신호이지, 출시 결정이 아니다.
핵심 비교 표
| 항목 | HappyHorse-1.0 | Seedance 2.0 |
|---|---|---|
| T2V Elo (오디오 없음) | 1333 (1위) | 1273 (2위) |
| T2V Elo (오디오 있음) | 1205 (2위) | 1219 (1위) |
| I2V Elo (오디오 없음) | 1392 (1위) | 1355 (2위) |
| I2V Elo (오디오 있음) | 1161 (2위) | 1162 (1위) |
| 오디오 생성 | 존재하나, Seedance에 뒤처짐 | 더 강함 — 네이티브 듀얼 브랜치 동기화 |
| 알려진 제공자 | 아니요 — 익명 | 예 — ByteDance |
| 아키텍처 (주장) | 단일 스트림 40레이어 트랜스포머 | 듀얼 브랜치 디퓨전 트랜스포머 |
| 오픈 가중치 | ”곧 공개” 예정이라고 주장 | 아니요 |
| 안정적인 API | 공개 API 없음 | Dreamina를 통한 소비자 접근; 공식 API 일시 중지 |
| 오늘 접근 | 데모 사이트만 | Dreamina, CapCut Pro, 중국 앱 |
HappyHorse가 앞서는 부분
오디오 없는 시각적 동작 품질: 블라인드 투표가 포착하는 것
오디오 없는 랭킹에서의 Elo 격차 — T2V에서 60점, I2V에서 37점 — 은 사소하지 않다. 블라인드 비교에서 사용자들은 더 자연스러운 카메라 드리프트, 더 부드러운 신체 움직임, 더 강한 장면 분위기라고 묘사하는 것 때문에 일관되게 HappyHorse를 선택한다. 무음 제품 루프, 별도 음악으로 편집되는 소셜 클립, 또는 후반 작업에서 음악이 추가되는 B롤이 사용 사례라면 이것이 관련 있다.
단일 스트림 트랜스포머 아키텍처 (주장) vs 멀티 스트림 파이프라인
HappyHorse의 마케팅 자료는 단일 시퀀스에서 텍스트, 영상, 오디오 토큰을 처리하는 통합 40레이어 셀프 어텐션 트랜스포머를 설명한다 — 별도 브랜치 간 크로스 어텐션 없음. 정확하다면 이것은 Seedance의 듀얼 브랜치 방식과 아키텍처적으로 구별된다. 첫 번째와 마지막 4개 레이어는 모달리티별 프로젝션을 사용하고, 중간 32개 레이어는 모든 모달리티에 걸쳐 파라미터를 공유한다고 한다. 아직 이 주장을 독립적으로 검증할 수 없다. GitHub와 모델 허브는 “곧 공개”로 표시되어 있다.
다국어 오디오 지원 주장
HappyHorse는 영어, 만다린, 광둥어, 일본어, 한국어, 독일어, 프랑스어 — 7개 언어에 대한 네이티브 지원과 낮은 단어 오류율 립싱크를 주장한다. Seedance 2.0은 음소 수준 립싱크에 8개 이상의 언어를 지원한다. 서류상으로는 경쟁력이 있다. 실제로는 HappyHorse의 다국어 출력을 충분히 스트레스 테스트해서 동등성을 확인하지 못했다.
Seedance 2.0이 우위를 유지하는 부분
오디오 생성: 여전히 오디오 포함 리더보드 양쪽에서 선두
Seedance는 오디오 포함 T2V와 I2V 모두에서 1위를 유지한다. 듀얼 브랜치 아키텍처 — 영상 프레임을 생성하는 브랜치 하나, 오디오 파형을 생성하는 브랜치 하나, 밀리초 수준 동기화를 위해 크로스 어텐션으로 연결 — 는 이를 위해 목적 설계되었다. 출력에 대화, 주변 소리, 또는 프레임 정확한 폴리가 필요할 때, 오디오를 생성 중 일등 시민으로 취급하는(후처리 단계가 아닌) Seedance의 아키텍처 결정이 구조적 이점을 준다.
알려진 제공자: ByteDance, 안정적인 정체성, 확립된 생태계
Seedance 2.0을 누가 만들었는지 알 수 있다. ByteDance의 Seed 연구팀, Wu Yonghui(전 Google 펠로우, Google Brain 포함 Google에서 17년) 주도로, Pixeldance부터 Seedance 1.0, 1.5 Pro, 그리고 현재 2.0까지 문서화된 계보가 있다. HappyHorse? 출판 시점 기준으로 누가 만들었는지 공개적으로 확인한 사람이 없다. Artificial Analysis는 익명 참가작으로 추가했다. 아레나 데뷔 몇 시간 만에 여러 서드파티 래퍼 사이트가 등장했지만, 원래 개발자라고 주장하는 곳은 없다.
프로덕션 결정에서는 출처가 중요하다. 모델 업데이트, 컴플라이언스, 연속성 측면에서 누구에게 의존하고 있는지 알아야 한다.
접근 경로: Dreamina에 공개 진입점 있음
Seedance 2.0은 오늘 ByteDance의 Dreamina 플랫폼을 통해 국제적으로 접근 가능하며, 유료 플랜은 월 약 $18부터 시작한다. CapCut Pro 통합은 2026년 3월 말 일부 시장에 출시되었다. 중국 사용자는 월 약 69위안(~$9.60 USD)부터의 플랜으로 Jimeng을 통해 접근할 수 있다.
하지만 — 공식 Seedance 2.0 API는 저작권 분쟁 보도로 인해 2026년 3월 중순부터 일시 중지된 상태다. 소비자 접근은 작동한다. 프로덕션 규모의 프로그래밍 방식 API 접근은 파이프라인을 구축하기 전에 확인이 필요하다. 서드파티 제공자들은 API를 통해 Seedance v1.5를 제공한다; 공식 채널을 통한 Seedance 2.0 API 가용성은 사전 프로덕션 확인이 필요하다.
접근 격차가 실제 결정 요인
HappyHorse: 안정적인 API 없음, 공개 가중치 없음, 출판 시점 데모 전용
오픈소스 출시 주장에도 불구하고 HappyHorse의 GitHub와 모델 허브는 모두 “곧 공개”로 표시되어 있다. 여러 데모와 래퍼 사이트가 존재하지만, SLA, 속도 제한, 또는 제품을 구축할 수 있는 가격이 있는 문서화된 API 엔드포인트를 제공하는 곳은 없다. 안정적이고 문서화된 엔드포인트를 통해 현재 HappyHorse-1.0을 제공하는 서드파티 API 제공자를 단 하나도 찾을 수 없었다.
프로덕션을 위해 평가 중이라면, 이것이 가장 중요한 단일 요인이다. 신뢰할 수 있게 호출할 수 없는 모델은 출시할 수 있는 모델이 아니다.
Seedance 2.0: Dreamina를 통해 접근 가능 — 세부 사항 확인 필요
Dreamina를 통한 소비자 접근은 기능한다. 플랫폼은 @ 참조 시스템, 멀티샷 편집, 오디오-비주얼 생성을 포함한 전체 기능 세트를 지원한다. 하지만 워크플로우가 API 수준 통합을 필요로 한다면 상황이 덜 명확하다. Seedance 2.0의 공식 BytePlus API는 3월부터 일시 중지되었다. fal.ai와 PiAPI 같은 서드파티 제공자들은 Seedance 1.5를 제공했다; Seedance 2.0 프로그래밍 방식 접근과 관련 가격 구조는 프로덕션 의존성을 구축하기 전에 직접 확인해야 한다.
”리더보드 1위”와 “프로덕션 준비 완료”가 다른 질문인 이유
나는 계속 이 문제로 돌아온다. Elo는 통제된 비교에서 사용자가 어떤 모델을 선호하는지 알려준다. 다음 화요일에 503 오류 없이 10,000개의 생성을 처리할 수 있는지는 알려주지 않는다. HappyHorse가 진짜로 더 나은 무음 영상을 생성할 수도 있다. 하지만 신뢰할 수 있게 호출할 수 없다면, 그 품질 우위는 아레나에만 존재하고 당신의 파이프라인에는 없다.
의사결정 프레임워크
오디오 품질이 필수 → Seedance 2.0. 오디오 포함 리더보드 양쪽에서 선두이며 듀얼 브랜치 아키텍처가 네이티브로 동기화된 소리를 생성한다. 클립에 대화, 주변 오디오, 또는 프레임 정확한 음향 효과가 필요하다면 Seedance가 오늘 더 강한 선택이다.
시각적 동작 충실도가 우선이고 기다릴 의향이 있음 → HappyHorse 모니터링. 오디오 없는 Elo 우위는 실재한다. 오픈 가중치와 API 접근이 약속대로 실현된다면 HappyHorse는 무음 우선 워크플로우에 매력적이 될 수 있다. 하지만 “곧 공개”는 SLA가 아니다.
오늘 프로덕션 API가 필요함 → Seedance 2.0이 더 안전한 선택. 완벽해서가 아니라 — 공식 API 일시 중지는 실제 제약이다 — Dreamina가 문서화된 가격으로 기능하는 접근 경로를 제공하고, 서드파티 제공자들이 Seedance 2.0 엔드포인트를 활발히 준비 중이기 때문이다. HappyHorse는 아직 동등한 인프라가 없다.
FAQ
HappyHorse-1.0이 실제로 Seedance 2.0보다 낫나요?
무엇을 측정하느냐에 따라 다르다. HappyHorse는 오디오 없는 비교에서 시각적 품질이 앞선다 (T2V Elo 1333 vs 1273, I2V 1392 vs 1355). Seedance는 오디오가 평가의 일부일 때 앞선다. 어느 모델도 4개 카테고리 전체를 지배하지 않는다. “더 낫다”는 것은 특정 사용 사례와 오디오 중요성에 상대적으로만 의미가 있다.
HappyHorse는 왜 오디오 없이는 앞서고 오디오 있으면 뒤처지나요?
아마 아키텍처 때문이다. HappyHorse는 단일 통합 트랜스포머가 하나의 시퀀스에서 모든 모달리티를 처리한다고 주장한다. Seedance 2.0은 크로스 어텐션으로 연결된 별도의 영상과 오디오 브랜치가 있는 목적 설계된 듀얼 브랜치 디자인을 사용한다. 음질과 동기화가 시각과 함께 판단될 때 그 특화된 오디오 브랜치가 Seedance에 우위를 주는 것으로 보인다.
오늘 API를 통해 HappyHorse-1.0에 접근할 수 있나요?
2026년 4월 8일 기준으로 내가 확인할 수 있는 안정적이고 문서화된 엔드포인트를 통해서는 불가능하다. 여러 래퍼 사이트가 브라우저 기반 데모 접근을 제공하지만, API 문서, 속도 제한, 또는 프로덕션급 SLA를 게시하는 곳은 없다. 공식 GitHub와 모델 허브는 모두 “곧 공개”로 표시되어 있다.
프로덕션 결정에 Artificial Analysis 리더보드는 얼마나 신뢰할 수 있나요?
인지된 영상 품질에 대한 가장 신뢰할 수 있는 크라우드소싱 신호다 — 블라인드 투표, Elo 기반 랭킹, 실제 인간 선호도. 하지만 한 가지를 측정한다: 어떤 출력을 사용자가 나란히 놓고 선호하는지. 생성 속도, 비용, 신뢰성, API 업타임, 또는 접근 안정성을 고려하지 않는다. 품질 입력으로 사용하되, 완전한 조달 결정으로 사용하지 말라.
HappyHorse-1.0의 향후 버전에서 오디오가 개선될까요?
공개 로드맵이 없다. 이 모델은 일주일도 채 안 된 시간 전에 익명으로 아레나에 등장했다. “곧 공개” 오픈소스 출시가 이루어진다면 커뮤니티 기여가 오디오 품질을 개선할 수 있다. 하지만 일정도 없고, 확인된 개발팀도 없고, 발표된 v2 계획도 없다. 현재 리더보드에 있는 것 이상의 어떤 것도 추측이다.
리더보드가 말하는 것과 개발자가 실제로 사용할 수 있는 것 사이의 격차에서 흥미로운 일이 일어나고 있다. HappyHorse의 수치는 진정으로 인상적이다 — 하지만 접근 없는 수치는 그냥 수치다. 그 GitHub 저장소가 공개되는 것을 계속 지켜볼 것이다. 그때까지 비교는 어느 모델이 더 나은지에 대한 것이 아니다. 사용 가능한 모델이 어느 것인지에 대한 것이다.
WaveSpeedAI에서 HappyHorse-1.0 사용해보기
HappyHorse-1.0은 현재 WaveSpeedAI에서 이용 가능하다:
이전 글:




