Claude Mythos 코딩 성능: AI 개발 워크플로우에 미치는 영향
Claude Mythos는 코딩 분야에서 Opus 4.6보다 훨씬 높은 점수를 기록한 것으로 알려져 있습니다. 2026년 AI 코딩 에이전트를 구축하는 개발자들에게 이것이 무엇을 의미하는지 알아보세요.

Fortune이 굵은 제목으로 단독 보도를 내보내자 모두가 사이버보안 우려에 집중했습니다. Anthropic이 미공개 모델을 홍보하는 블로그 초안을 포함해 내부 파일 약 3,000개를 실수로 노출했다는 내용이었습니다. 하지만 매일 Claude로 개발을 하는 저에게는 유출 사건 자체보다 그 초안에 조용히 묻혀 있던, 폭발적인 코딩 성능에 관한 주장이 더 눈에 띄었습니다.
WaveSpeedAI에서 이용 가능 — 토큰당 투명한 가격, OpenAI 호환 엔드포인트. Claude Opus 4.7 API → · Claude Sonnet 4.6 API → · Playground 열기 →
이 글에서 여러분과 저, Dora는 과대 광고나 보안 공황을 좇지 않고, Claude Mythos / Capybara의 코딩 능력에 대해 우리가 실제로 알고 있는 것(그리고 모르는 것)을 정확히 정리해 실제 제품을 출시하는 개발자와 팀에게 중요한 것만 곧장 이야기하겠습니다.
유출된 초안이 밝힌 Claude Mythos 코딩 성능
유출된 초안의 정확한 주장은 다음과 같습니다: “이전 최고 모델인 Claude Opus 4.6과 비교했을 때, Capybara는 소프트웨어 코딩, 학술적 추론, 사이버보안 등의 테스트에서 극적으로 높은 점수를 기록합니다.”
코딩 성능에 관해 Anthropic이 문서로 남긴 내용은 이것이 전부입니다. SWE-bench 퍼센트도, Terminal-Bench 점수도, 비교 표도 없습니다. “극적으로 높다”는 표현 자체가 실질적인 신호입니다 — 모호하지만 의미 없지는 않습니다.

참고로 Opus 4.6은 현재 공개 모델 중 SWE-bench Verified(약 80.8%), Terminal-Bench 2.0, Humanity’s Last Exam에서 선두를 달리고 있습니다. Anthropic의 공식 대변인은 이 모델이 “추론, 코딩, 사이버보안에서 의미 있는 발전”을 나타낸다고 확인했습니다. 훈련은 완료됐고 얼리 액세스 테스트가 진행 중이며, 코딩은 명시적으로 세 가지 주요 역량 차원 중 하나입니다. 나머지는 추론입니다.
이 모델 티어에서 코딩이 가장 중요한 역량인 이유
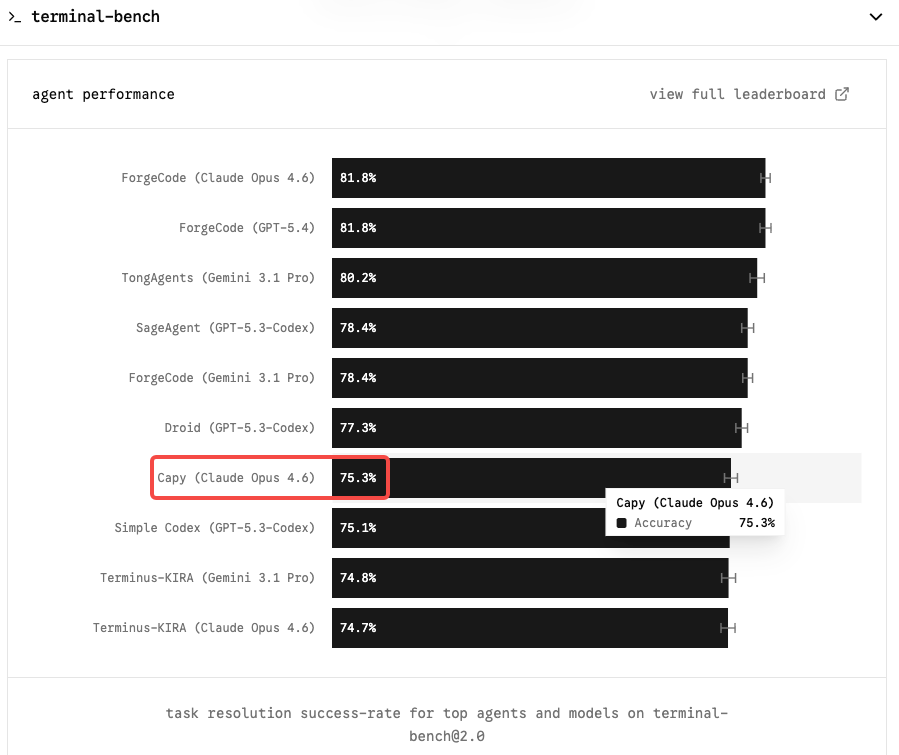
Terminal-Bench 2.0 맥락과 현재 Opus 4.6 점수
Terminal-Bench 2.0은 에이전틱 코딩 워크플로에서 가장 중요한 벤치마크입니다. 격리된 GitHub 이슈 해결을 테스트하는 SWE-bench와 달리, Terminal-Bench는 샌드박스 터미널 환경에서 시스템 관리, DevOps, 다단계 CLI 워크플로 등 실제 작업을 평가합니다. 더 어렵고 실제 프로덕션 환경에 가까우며 스캐폴드 기반 점수 인플레에 덜 취약합니다.
Claude Opus 4.6은 Terminal-Bench 2.0에서 65.4%, OSWorld에서 72.7%로 1위를 차지하고 있습니다. Capybara 티어 모델이 이 수치를 75~85% 범위로 끌어올린다면, 자율 코딩 에이전트를 운영하는 모든 팀에게 진정한 도약이 될 것입니다.
SWE-bench Verified에서는 상황이 더 압축되어 있습니다. 현재 여섯 개 모델이 서로 0.8점 이내에 있습니다. Opus 4.6은 80.8%, Gemini 3.1 Pro는 100만 토큰당 $2/$12로 80.6%를 달성합니다. 순수 SWE-bench는 더 이상 유의미한 차별화 요소가 아닙니다. Opus 4.6이 프리미엄을 정당화하는 곳은 Terminal-Bench와 장문 컨텍스트 일관성이며, Mythos도 바로 이 부분에서 가장 분명한 입지를 확보할 가능성이 높습니다.
“극적으로 높다”가 구조적으로 의미하는 것
초안에서 “극적으로 높다”는 표현은 “단계적 변화(step change)“와 함께 등장합니다 — Anthropic 대변인이 공개적으로 사용한 것과 같은 표현입니다. 두 용어 모두 가볍게 쓰인 것이 아닙니다. Opus 4.1에서 Opus 4.6으로의 도약은 같은 티어 내에서의 세대적 개선이었습니다. “단계적 변화”는 종류의 차이를 암시합니다 — 연속된 두 Opus 버전 간의 차이보다는 Sonnet과 Opus 사이의 격차에 가깝습니다.
코딩에서 Opus 4.6을 의미 있게 앞서는 모델은 소프트웨어 개발, 디버깅, 에이전틱 워크플로에서 중요한 도구가 될 것입니다. 열린 질문은 언제 사용 가능해지며 비용이 얼마냐는 것입니다. 이것이 정직한 틀입니다. Anthropic의 최근 실적을 감안하면 성능 주장은 신뢰할 만합니다. 검증이 아직 이루어지지 않았을 뿐입니다.
에이전틱 코딩 워크플로에 대한 시사점
장문 컨텍스트 코드 작업
코딩 팀에 대한 Capybara 티어 모델의 가장 즉각적인 실질적 함의는 원시 벤치마크 점수가 아닙니다 — 더 나은 추론이 규모에서 무엇을 하는가입니다.
Claude Code의 1M 컨텍스트 창은 이제 Opus 4.6에서 GA(일반 출시)가 됐으며, 압축 후 약 83만 토큰을 사용할 수 있어 전체 모노레포와 완전한 문서 세트를 다루기에 충분합니다. 코딩에서 Opus 4.6을 극적으로 능가하는 모델이 같은 창에 적용된다면, 대규모 코드베이스 전반의 아키텍처 이해도가 높아지고 멀티 파일 리팩토링에서 추론 오류가 줄어듭니다. 컨텍스트 창은 바뀌지 않습니다. 그 안에서의 추론 품질이 달라지는 것입니다.
오늘날 대규모 코드베이스 분석을 수행하는 팀 — 5만 줄 이상의 소스를 불러와 모델에게 전체 그림을 이해하도록 요청하는 작업 — 에게 이것이 가장 중요한 실질적 업그레이드 경로입니다.
다단계 디버깅 에이전트
Anthropic은 Opus 4.6 출시와 함께 Agent Teams를 실험적 기능으로 출시해 에이전틱 워크플로에서 중요한 발걸음을 내디뎠습니다. 하나의 세션이 팀 리더 역할을 합니다 — 작업을 조율하고, 태스크를 할당하며, 결과를 종합합니다. 팀원들은 독립적으로 작동하며, 각자 자신의 컨텍스트 창에서 서로 직접 소통합니다.
다단계 디버깅 에이전트는 더 나은 기반 모델의 복합적 가치가 가장 명확해지는 곳입니다. 멀티 에이전트 설정에서 팀 리더의 계획 품질이 전체 운영의 성패를 결정합니다. 더 강력한 모델은 태스크 분해를 더 잘하고, 서브에이전트를 위한 태스크 명세를 더 명확하게 작성하며, 통합 오류를 더 일찍 발견합니다.
유출된 초안은 소프트웨어 코딩을 사이버보안과 함께 Capybara가 Opus 4.6을 “극적으로” 앞서는 영역으로 명시했습니다. 이 격차가 Terminal-Bench 유형의 작업에서 실제로 크다면, 잘못된 가정에서 복구하는 데 인간 개입이 덜 필요한 더 신뢰할 수 있는 다단계 디버깅 에이전트로 직접 이어질 것입니다.
자기 주도적 코드베이스 탐색
이것이 실제로 가장 궁금한 사용 사례입니다. Claude Code가 코드베이스에서 문제를 추적하고, 근본 원인을 파악하며, 수정 사항을 구현합니다. 그 추적의 품질은 컨텍스트 창 크기가 아닌 추론 깊이의 함수입니다.
2026년의 전형적인 워크플로에서 개발자는 고수준 요구사항을 제시하고 리드 에이전트가 이를 별개의 태스크로 분해하며, 팀원들은 Model Context Protocol을 활용해 외부 도구에 접근하고 테스트를 실행하며 보안 감사를 동시에 수행합니다. 이런 설정에서 오케스트레이터로 작동하는 Capybara 티어 모델은 전체 워크플로를 더 자율적으로 만들 것입니다 — 즉, 명확화 요청이 줄고 초기 태스크 분해가 더 좋아지며 서브에이전트가 예기치 못한 상태에 부딪혔을 때 자기 수정이 더 안정적으로 이루어집니다.
Mythos를 사용할 수 없는 지금 빌더들이 해야 할 일
현재 사용 사례에 맞게 Opus 4.6을 벤치마크하는 방법
지금 당장 할 수 있는 가장 유용한 일은 벤치마크가 아닌 실제 워크로드에 대해 Opus 4.6으로 자체 평가를 실행하는 것입니다. SWE-bench 같은 일반 벤치마크는 표준화된 스캐폴딩으로 격리된 이슈 해결을 테스트합니다. 여러분의 프로덕션 코딩 에이전트는 특정 코드베이스 구조, 특정 태스크 세트, 특정 실패 모드를 가지고 있습니다. 중요한 것은 바로 그것입니다.
코딩 에이전트를 위한 실용적인 기준 평가는 다음과 같을 수 있습니다:
# 간단한 태스크 성공률 추적
results = {
"task_id": [],
"model": [],
"success": [],
"turns_needed": [],
"context_used_tokens": [],
"cost_usd": []
}
# 대표적인 태스크 20~30개를 Opus 4.6으로 실행
# 추적 항목: 첫 번째 시도에 성공했는가? 몇 번 시도했는가?
# 1M 컨텍스트 창의 몇 퍼센트를 소비했는가?
# 어디서 실패했는가 — 추론 오류, 도구 사용, 컨텍스트 오버플로?이것이 중요한 이유: Mythos가 출시될 때 특정 코드베이스 구조와 태스크 분포에서 역량 향상이 추가 비용을 정당화하는지 평가할 실질적인 기준선을 갖게 됩니다. Anthropic의 내부 테스트 스위트에서 “극적으로 높다”는 것이 여러분의 특정 워크플로에서 의미 있는 차이로 이어질 수도 있고 아닐 수도 있습니다.
‘최고의 모델’은 여러분이 소통하는 방식에 맞는 모델입니다. 좋은 하네스의 중간 티어 모델이 나쁜 하네스의 최첨단 모델을 이깁니다. 프롬프트 엔지니어링, 도구 구성, CLAUDE.md 구조 등 하네스 품질은 지금 개선할 수 있는 변수입니다. Mythos는 설계가 잘못된 에이전트 아키텍처를 고쳐주지 않습니다.
더 유능한 모델과 함께 확장될 아키텍처 결정
좋은 소식은 잘 설계된 에이전틱 아키텍처는 라우팅 레이어에서 모델에 구애받지 않는다는 것입니다. 지금 구축할 가치 있는 패턴들:
오케스트레이션과 실행을 분리하세요. 태스크를 분해하고, 파일을 할당하며, 출력을 검토하는 오케스트레이터 에이전트 — 구현을 담당하는 특화된 서브에이전트가 뒷받침하는 — 는 단일 파라미터 변경으로 기반 모델을 교체할 수 있습니다. 지금 이 분리를 구축하면 Mythos 업그레이드가 아키텍처 리팩토링이 아닌 구성 업데이트가 됩니다.
CLAUDE.md를 세션별 프롬프팅이 아닌 런타임 컨텍스트로 사용하세요. CLAUDE.md 파일은 저장소 내 AI 에이전트의 “헌법” 역할을 합니다 — 프로젝트 아키텍처, 코딩 표준, 빌드 명령에 대한 필요한 컨텍스트를 제공해 에이전트가 인간의 세세한 관리 없이 작동할 수 있게 합니다. 잘 구조화된 CLAUDE.md는 오늘날 Opus 4.6에서 태스크당 탐색 비용을 줄이고 내일 더 강력한 모델로부터의 이득을 증폭시킬 것입니다.
컨텍스트 한계를 우회하는 것이 아니라 1M 컨텍스트 창을 위해 설계하세요. 이미 1M 창 내에서 작동하도록 파일 로딩 전략, 청킹 로직, 컨텍스트 관리를 재구성한 팀은 Mythos의 추론 역량을 같은 창 전반에서 최대한 활용할 준비가 된 것입니다. 한계가 높아지지 않는다고 가정하는 컨텍스트 제한 우회책을 구축하지 마세요.
코딩 특화 팀이 출시 시 주목해야 할 것
개발자에게 중요한 신호는 일반 기업 신호와 다릅니다. 코딩 중심 팀에게 특히 중요한 것들:
출시 시 SWE-bench 및 Terminal-Bench 점수. Anthropic은 역사적으로 모델 출시와 함께 이것들을 공개해 왔습니다. Mythos가 “극적으로 높다”는 주장을 실현한다면, Terminal-Bench 2.0 점수가 Opus 4.6의 65.4%보다 의미 있게 올라가야 합니다. 75% 이상으로의 도약은 에이전틱 워크플로에 대한 주장을 검증할 것입니다.
Claude Code 모델 문자열 업데이트. Claude Code 문서와 API 모델 개요에서 새로운 모델 별칭을 확인하세요. Claude Code는 역사적으로 새로운 플래그십 출시 며칠 이내에 기본 모델을 업데이트해 왔습니다. Mythos가 공개 API로 출시된다면, 코딩 팀에게 처음 나타나는 곳이 여기일 것입니다.
Agent Teams 호환성 발표. Agent Teams는 Opus 4.6과 함께 실험적으로 출시됐습니다. Mythos가 출시 시 Agent Teams와 기본적으로 통합되는지 — 아니면 별도 구성이 필요한지 — 가 팀이 멀티 에이전트 워크플로에 얼마나 빨리 적용할 수 있는지를 결정할 것입니다.
Anthropic 변경 로그와 가격 문서. 이 두 페이지는 어떤 언론 발표보다 먼저 나타나는 가장 빠른 신뢰할 수 있는 신호입니다. 새로운 모델 문자열과 새로운 가격 행이 여기에 먼저 나타날 것입니다.
FAQ
Claude Mythos는 지금 코딩 작업에 사용할 수 있나요?
아니요. 2026년 4월 초 현재 Claude Mythos 또는 Capybara 티어를 위한 공개 API 엔드포인트가 없습니다. Claude Mythos / Capybara는 Anthropic이 선정한 소규모 얼리 액세스 고객에게만 제공되며, 공개 API도, 발표된 가격도, 확정된 출시일도 없습니다. Claude Opus 4.6 — SWE-bench Verified 80.8%, Terminal-Bench 2.0 65.4% — 이 현재 사용 가능한 최고의 옵션으로 남아 있습니다.
Claude Mythos는 Claude Code와 함께 작동하나요?
거의 확실히 그렇습니다, 결국에는. Claude Code의 아키텍처는 모델에 구애받지 않으며, 새로운 플래그십으로 전환하는 것은 단일 파라미터 변경입니다. 하지만 이것은 출시 시 Mythos에 대해 확인된 것이 아닙니다.
AI 코딩 도구를 만들기 위해 Mythos를 기다려야 하나요?
아니요. Anthropic은 “일반 출시 전에 훨씬 더 효율적이 되어야 한다”고 밝혔습니다. 지금 Opus 4.6으로 구축한다는 것은 Mythos가 출시될 때 여러분의 아키텍처가 프로덕션 검증된 상태임을 의미합니다. 업그레이드는 모델 문자열 교체가 될 것입니다. 기다리는 팀은 따라잡기에 급급하게 될 것입니다.
이전 포스트:




