Models.dev vs Portkey Models: Metadata vs Gateway Catalogs
Compare Models.dev and Portkey Models by metadata depth, pricing visibility, gateway fit, routing use cases, and production verification needs.
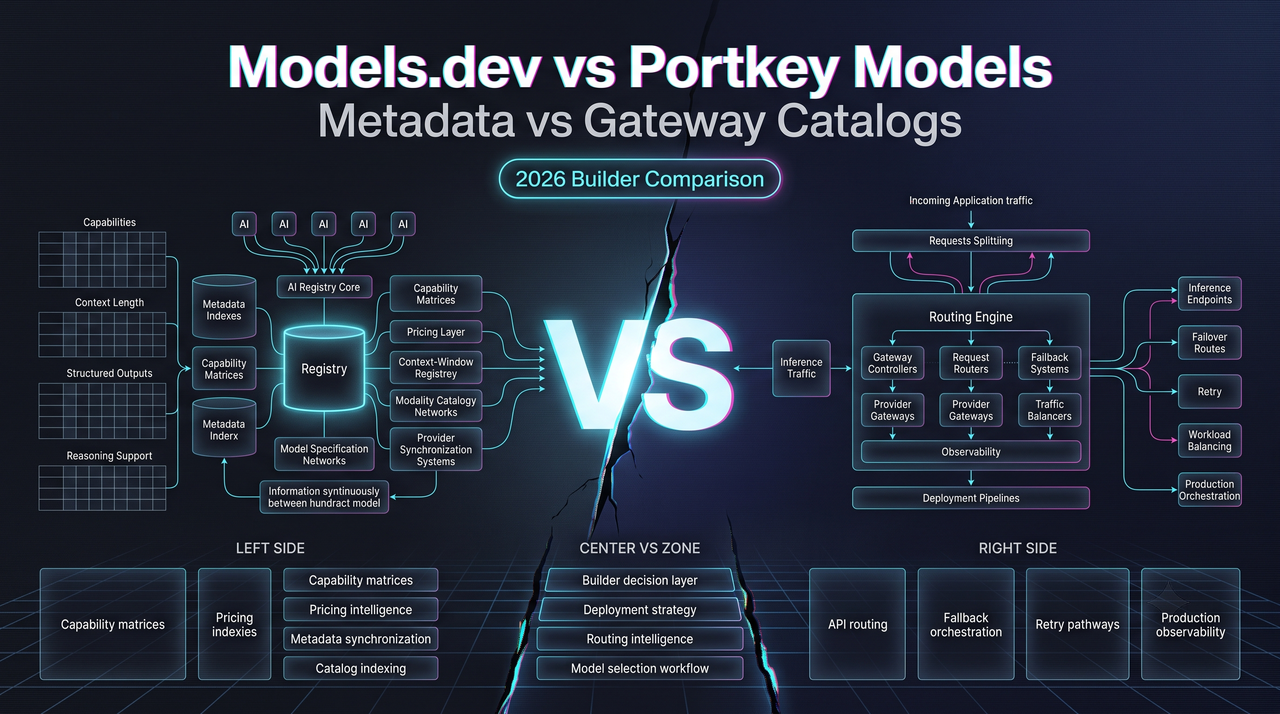
Hello, guys. It’s Dora. I ran into this comparison while cleaning up a model shortlist. The first table looked harmless: model name, provider, price, context window, tool support. Then the real question showed up.
Was I looking for open provider metadata, or was I looking for a catalog that made more sense inside an LLM gateway and cost-management workflow?
That is the useful way to read Models.dev vs Portkey Models. Models.dev is better treated as open model metadata. Portkey Models is better treated as pricing and gateway-adjacent catalog context. GitHub Models belongs in a side note, not as a third tool in the same category.
This piece is the distinction I would keep in my own workflow.
Quick Verdict for Developers
- Use Models.dev when the question is, “What are the model facts?”
- Use Portkey Models when the question is, “How does this model fit pricing, cost tracking, and gateway operations?”
- Use GitHub Models when the question is, “Can I test prompts and compare behavior before I commit to an integration?”
That separation matters. A model catalog can save time, but only if the team knows what kind of catalog it is using.
When you need open model metadata
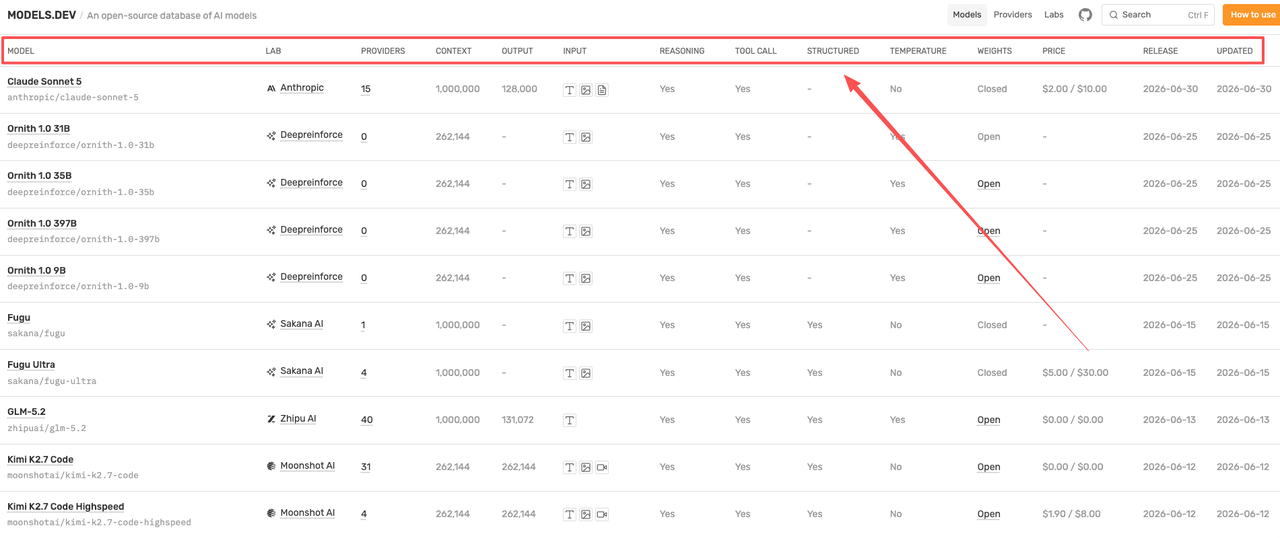 Models.dev is useful at the shortlist stage. Its own site exposes Models.dev API files for provider data, provider-agnostic model metadata, and the combined catalog. That makes it a clean starting point when a builder wants to check model identity, providers, context limits, output limits, modalities, reasoning flags, tool calls, structured output support, weights, and price fields.
Models.dev is useful at the shortlist stage. Its own site exposes Models.dev API files for provider data, provider-agnostic model metadata, and the combined catalog. That makes it a clean starting point when a builder wants to check model identity, providers, context limits, output limits, modalities, reasoning flags, tool calls, structured output support, weights, and price fields.
I would use it before integration work. Not after.
At this point, the job is to remove bad candidates. If a model cannot support the input type, output length, or capability profile the product needs, it should not reach the runtime test stage.
When you need gateway and cost-management context
Portkey Models belongs closer to cost work. Portkey’s own Portkey Models docs describe it as an open-source pricing and configuration database for LLMs across providers. That changes the use case.
I would not open Portkey Models just to answer “what exists?” I would open it when pricing units, provider differences, cache costs, or gateway-side model configuration are already part of the decision.
Different question. Different tool.
What Models.dev Is Best For
Models.dev is best for the first catalog pass.
I use that pass to avoid wasting engineering time. The point is not to prove that a model works in production. The point is to decide whether it deserves a test slot at all.
Provider-agnostic model metadata
The provider-agnostic part is the important part.
A model and a provider entry are not always the same thing. The same model family can appear through different providers, with different IDs, prices, feature flags, limits, and serving assumptions. If the team mixes those layers too early, the shortlist gets messy fast.
Models.dev helps keep those layers separate. That is useful for API builders, platform engineers, and product teams that want a neutral model catalog before choosing a serving route.
Capability filters before integration work
Capability filters are where Models.dev earns its place.
If the workflow needs tool calls, structured outputs, long context, image input, or open weights, I want those constraints visible before anyone writes code. A catalog pass should catch obvious mismatches. Then I still verify everything.
A metadata field can say a model supports structured output. It cannot tell me whether the model keeps my schema stable under retries, fallbacks, long prompts, or messy user input. This is where my data ends. The rest needs provider docs and real calls.
What Portkey Models Is Best For
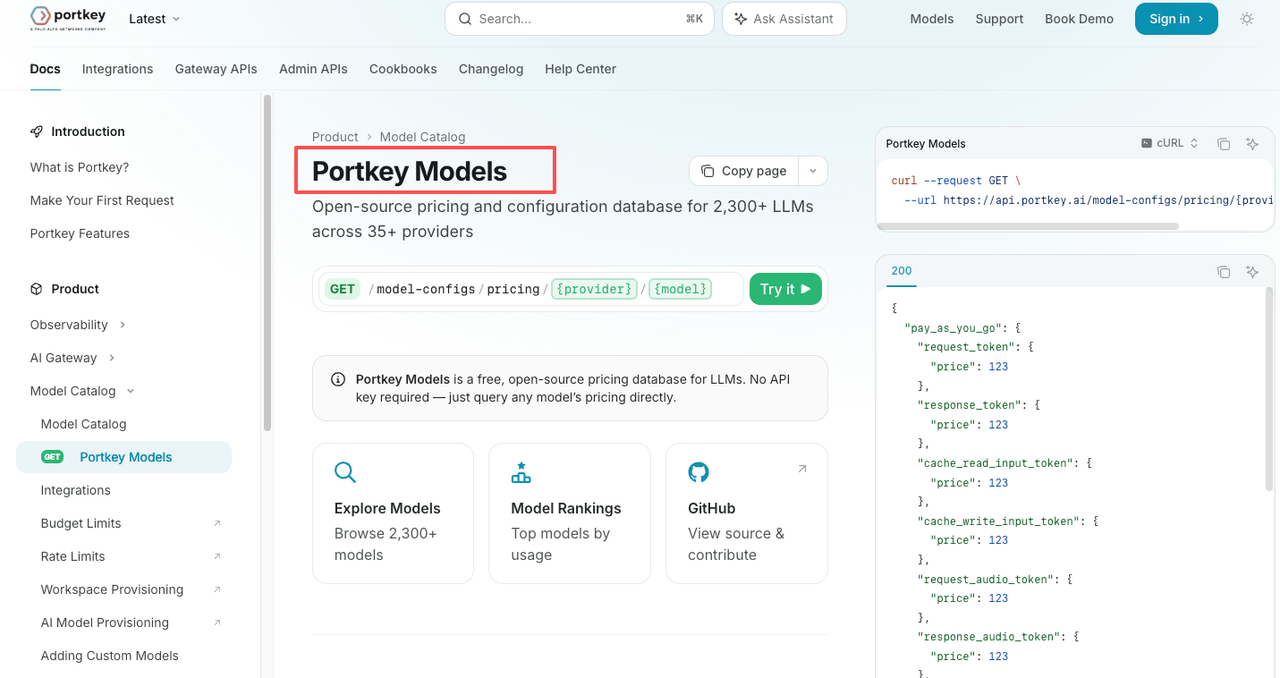
Portkey Models is best when the model decision is already connected to pricing visibility, gateway setup, or team-level cost control.
That does not mean Portkey has “better” data in every case. I would not make that claim without checking rows one by one. The safer conclusion is narrower: Portkey Models fits better when the catalog is part of a gateway and cost workflow.
Cross-provider pricing visibility
AI model pricing is not one number.
Input tokens, output tokens, cache reads, cache writes, audio units, image units, and provider-specific billing rules can all change the final cost. This matters less during a single prompt test. It matters a lot when traffic grows.
Portkey Models is useful when the team wants pricing information in a format that can connect to provider comparison and model configuration.
That is different from using a metadata table as a rough estimate.
Gateway and enterprise cost context to verify
The gateway context is the main reason I would consider Portkey Models in a production planning conversation. Portkey’s Portkey cost management docs describe real-time cost visibility, token tracking, provider-specific breakdowns, budget monitoring, and custom pricing configuration.
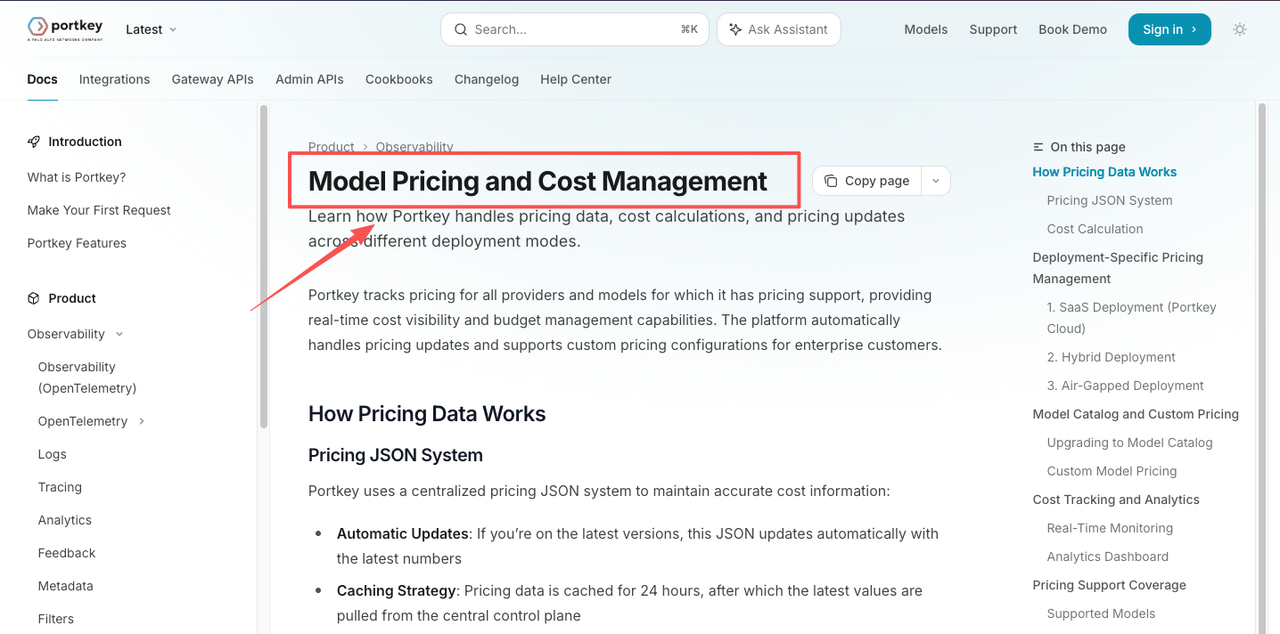
That sounds useful. It also needs verification.
I would check whether the exact model has pricing support, whether custom rates match the provider contract, whether cache pricing behaves as expected, and whether request-level logs match what finance or infra teams need. Catalog first. Gateway logs second. Billing reconciliation after that.
Side Note: Where GitHub Models Fits
GitHub Models should stay as a side note here. It is useful, but it is not the same kind of object.
GitHub describes GitHub Models docs around a model catalog, prompt management, model comparison, quantitative evaluations, and GitHub workflow integration. That makes it relevant for experimentation near code and prompts.
It does not make it the same as Models.dev. It does not make it the same as Portkey Models either.
Playground and experimentation, not the same category
GitHub Models fits when I want to test prompt behavior.
The GitHub model playground lets developers adjust model parameters, submit prompts, compare model responses, and move from playground testing toward API experiments. That is a good workflow for early validation.
It is not the place I would use to decide open provider metadata. It is not the place I would use to model gateway economics. If GitHub Models search intent grows, it deserves a separate article. For this comparison, keeping it small is cleaner.
Comparison Table
Metadata, pricing, gateway fit, API testing, governance
| Question | Models.dev | Portkey Models | GitHub Models |
|---|---|---|---|
| Main job | Open model metadata | Pricing and configuration catalog | Playground and prompt experimentation |
| Best first use | Shortlist models before provider testing | Compare pricing and gateway cost context | Test prompts and compare model behavior |
| Metadata fit | Strong for provider-agnostic model facts | Useful, but pricing/config context is the center | Useful inside GitHub workflow |
| Pricing fit | Good as a first-pass field | Stronger when cost management matters | Separate GitHub usage context |
| LLM gateway fit | Not a gateway | Closest fit when Portkey gateway is in scope | Not a gateway catalog |
| API testing fit | No inference testing | Needs gateway/runtime verification | Useful for experiments, not final production proof |
| Governance fit | Open catalog orientation | Better fit for budgets, overrides, and tracking | Fits GitHub org/repo workflows |
| Replaces provider docs? | No | No | No |
Production Decision Framework
The safest production workflow is boring.
Start with a catalog. Confirm through provider docs. Run real API calls. Track cost and failure behavior. Then decide. Skipping those steps makes the shortlist feel faster. Usually it just moves the work into debugging.
When to combine a catalog with direct provider tests
I would combine a catalog with direct provider tests whenever the model will touch a real user workflow, paid traffic, automated routing, or any fallback path.
A catalog can tell me a model might fit. It cannot confirm account access, rate limits, region availability, latency, schema stability, refusal shape, streaming behavior, retry behavior, or true monthly cost. Those are production questions.
Provider docs answer some of them. Runtime tests answer the rest. The failure shape matters more than people expect. A fallback that returns a different JSON shape is not a fallback. It is a new bug with better branding.
When to split GitHub Models into a separate article later
I would split GitHub Models into a separate article if the search intent becomes GitHub-specific.
Queries like “GitHub Models pricing,” “GitHub Models playground,” “GitHub Models evals,” or “GitHub Models API” are not really asking about Models.dev vs Portkey Models. They are asking how GitHub’s model workflow works for developers.
That article can go deeper into prompt files, side-by-side comparisons, evaluation metrics, repository workflows, and API experiments. This one should stay focused on metadata versus gateway catalogs.
FAQ

Is Models.dev better than Portkey Models for pricing?
Not generally. Models.dev includes price fields as part of broader model metadata. Portkey Models is more pricing-centered and fits better when gateway cost tracking or cross-provider cost comparison matters. I would use Models.dev for early filtering and Portkey Models when AI model pricing is closer to the actual decision.
Which tool is better for model routing?
Portkey is closer to routing because Portkey’s broader product includes an LLM gateway. Models.dev is not a router. Portkey Models alone is still not a routing decision. Routing needs gateway setup, fallback rules, request logs, and runtime tests.
Does either catalog replace provider docs?
No. Neither replaces provider docs. Catalogs help reduce the candidate list. Provider docs and real API calls confirm current availability, model limits, parameters, billing behavior, and production fit.
When should GitHub Models enter the workflow?
GitHub Models enters when the team wants a playground, prompt testing, or evaluations inside GitHub. It should stay separate from the metadata-versus-gateway catalog decision.
Conclusion
The best answer to Models.dev vs Portkey Models is not “pick one.” Pick based on the uncertainty you are trying to remove.
If the uncertainty is model identity, provider metadata, capabilities, or a clean shortlist, start with Models.dev. If the uncertainty is AI model pricing, gateway fit, cost tracking, or budget context, start with Portkey Models. If the uncertainty is prompt behavior, move GitHub Models into a separate experimentation step.
That keeps the categories clean. It also keeps the production test honest.
One fewer category mistake. Sounds small. Adds up fast.
Previous posts: